







呆呆象呆呆的所有博客目录

一、inductive bias 归纳偏置
1.1 背景与概念介绍
No-Free-Lunch (不存在免费午餐理论)提出没有先验知识进行学习是不可能的。如果我们不对特征空间有先验假设,则所有算法的平均表现是一样的。
通常情况下,我们不知道具体上帝函数的情况,但我们猜测它类似于一个比较具体的函数。这种基于先验知识对目标模型的判断就是归纳偏置(inductive bias)。归纳偏置所做的事情,是将无限可能的目标函数约束在一个有限的假设类别之中,这样,模型的学习才成为可能。其实,贝叶斯学习中的“先验(Prior)”这个叫法,可能比“归纳偏置”更直观一些。他是一些先验知识的融入后所做出的的针对模型的约束。
以此我们来看一下两个单词的意思:
归纳(Induction)是自然科学中常用的两大方法之一(归纳与演绎, induction and deduction),指的是从一些例子中寻找共性、泛化,形成一个比较通用的规则的过程;
偏置(Bias)是指我们对模型的偏好。
通俗的来讲,归纳偏置可以理解为:
-
在现实生活中,我们会从观察到的现象中归纳出一定的规则(heuristics)
-
根据这些规则对模型做一定的约束,归纳偏置即变成了关于目标函数的必要假设
-
提出这个假设的目的是为了选择出更符合现实规则的模型。在此过程中,归纳偏置起到“模型选择”的作用(这个作用在下一小节作用中体现和叙述)
1.2 作用
如果给出更加宽松的模型假设类别,即使用更弱的Inductive bias,那么我们更有可能得到强力模型-接近目标函数f。损失由近似损失和估计损失组成,这样做虽然减少了近似损失,但会增大估计损失,模型将更加难以学习,更容易过拟合。
归纳偏置的作用是使得学习器具有了泛化的功能。
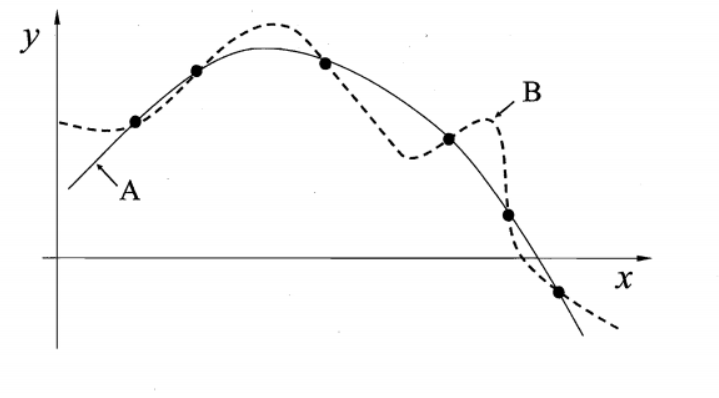
对于图中的6个离散的点可以找到很多条不同的曲线去拟合它们,但是我们自己训练的模型必然存在一定的“偏好”才能学习出模型自己认为正确的拟合规则。
哪条是较为准确地拟合出通用规则的曲线?明显地,实线是加了一定正则的偏置才能使得曲线更为简单,更为通用。
1.3 例子
一些常见原理的归纳偏置
| 分类 | 学习的问题&理论假设 | 归纳偏置(基于这些归纳偏置作为约束,才有了前面的模型) |
|---|---|---|
| 深度学习 | 使用CNN处理图像问题 | locality(局部性)即空间相近的grid elements有联系而远的没有 spatial invariance(空间不变性)空间变换的不变性,,根据该假设所设置的CNN具有kernel权重共享的特性 |
| 深度学习 | 使用RNN处理时序问题 | sequentiality(顺序性)序列顺序上的time steps有联系 time invariance(时间不变性)时间变换的不变性,根据该假设所设置的RNN具有权重共享的特性 |
| 深度学习 | 注意力机制 | 基于从人的直觉、生活经验归纳得到的规则。 |
| 机器学习 | 最近邻居 | 假设在特征空间(feature space)中一小区域内大部分的样本是同属一类。给一个未知类别的样本,猜则它与它最紧接的大部分邻居是同属一类。这是用于最近邻居法的偏置。这个假设是相近的样本应倾向同属于一类别。KNN(K-近邻算法)就是基于这种思想 |
| 机器学习 | 最少特征数 | 除非有充分的证据显示一个特征是有效用的,否则它应当被删除。这是特征选择算法背后所使用的假设。 |
| 机器学习 | 最大边界 | 当要在两个类别间画一道分界线时,试图去最大化边界的宽度。这是用于支持向量机(SVM)的偏置;即假设好的分类器应该最大化类别边界距离; |
| 机器学习 | 最小描述长度 | 当构成一个假设时,试图去最小化其假设的描述长度。假设越简单,越可能为真的。奥卡姆剃刀的理论基础。老生常谈的“奥卡姆剃刀”原理,即希望学习到的模型复杂度更低 |
| 机器学习 | 最大条件独立性 | 如果假说能转成贝叶斯模型架构,则试着使用最大化条件独立性。这是用于朴素贝叶斯分类器的偏置。 |
| 机器学习 | 最小交叉验证误差 | 当试图在假说中做选择时,挑选那个具有最低交又验证误差的假说。 |
二、选择性偏差
2.1 概念
在研究过程中因样本选择的非随机性而导致得到的结论存在偏差,不能代表整体,包括自选择偏差(self-selection bias)和样本选择偏差(sample-selection bias)。
维基百科解释
Selection bias is the bias introduced by the selection of individuals, groups or data for analysis in such a way that proper randomization is not achieved, thereby ensuring that the sample obtained is not representative of the population intended to be analyzed. It is sometimes referred to as the selection effect.
选择偏差是指选择个体、群体或数据进行分析时产生的偏差,这种偏差导致无法实现适当的随机化,从而确保获得的样本不能代表拟分析的人群。它有时被称为选择效应。
自选择偏差
是指解释变量(解释变量亦称“说明变量”、“可控制变量”,是经济计量模型中的自变量。)不是随机的,而是个体选择的结果,而这个针对自变量选择的过程会使对主效应的估计产生偏差。(我概括为:若所想要统计观察的变量为A;在自我选择样本,进行随机考量A的时候,加入了与A相关变量B的不随机筛选,导致选择出来的A已经不随机,如果样本的选择过程依赖了某个变量(是否上过大学/是否会访问该网站),而这个变量恰好是你关注的的变量的共同结果,则会导致选择性偏差。)
赵西亮老师在《基本有用的计量经济学》一书中也将这种偏差成为混杂偏差(confounding bias),即由共同原因造成的两个变量之间的相关性。自选择偏差与遗漏变量非常相像,很多学者提到自选择偏差也是内生性问题的来源之一,但其实自选择偏差本身是另一个研究问题,只是往往会造成遗漏变量,所以会误让人以为自选择是造成内生的主要原因之一。
例如研究是否上大学对收入的影响,我们将上大学的和没上大学的人进行简单比较,我们会发现大学生的平均工资比没上过大学的人的平均工资高。事实上,这种简单比较就存在严重的自选择问题,因为在这里比较的两类人在自身特质方面可能存在很大差异,上大学的孩子可能本身就很出色(更聪明、有毅力、能力强…),因而更有可能获得更高的收入。
样本选择偏差
是指样本选择不是随机的,使样本不能反映总体的某些特征,从而使估计量产生偏差。
赵西亮老师举了一个关于中国农村教育收益率的估计的例子。由于户籍的限制,在城市化过程中,农村中最有能力的个体率先通过升学、参军等途径突破户籍限制进入了城市体系,在调查样本中无法观测到这些已经成为城市居民的原农村居民,而调查数据中的个体是那些没有办法突破户籍限制的样本,因此,农村的样本就是一个选择性的样本,使用这一样本估计农村教育收益率将大大低估农村教育的作用。
再比如,我们很多大学生为了课程作业、毕业论文、亦或是所谓的学术科研调查活动,在网上发布调查问卷,然后转到空间、朋友圈,这种调查方式本身就存在样本选择问题,因为还有一大部分人群不在你的朋友圈(你的好友列表都是你的同学啊、朋友啊),还有一大部分人群根本不使用互联网,或者说根本不会看到你发布的问卷。(我觉得这个例子不如下面抽烟的例子好)
2.2 例子
- 例如调用全国大学生学习情况,如果样本空间只是清华、北大,那么肯定会对总体的调查结果产生很大的差别,这就是我们常说的选择性误差
- 找50个身体很好,但是抽烟的人。再找50个身体很差,但是不抽烟的人。对比两组人,得出结论:吸烟有益健康。样本存在选择性偏差。
- 在大学中开展社会调查,实际上是condition on受访者上过大学
- 使用某个在线网站上的数据做分析,实际上是condition on用户会访问该网站
- 分析从战场返回的战斗机上的弹孔位置,实际上是condition on飞机没有被击落
参考文献:
选择性偏差(selection bias)指的是什么? - 知乎
机器学习:没有免费午餐定理(No Free Lunch Theorem)_良百万-CSDN博客

















 2043
2043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









