







Python实现Fisher判别分析方法
参考论文:《导线覆冰预报模型的拟合过程及过程辨识方法》
背景
Fisher判别分析是一种经典的两分类技术。其分类思路是根据最大化类间离散度,最小化类内离散度(即各总体的方差尽可能小,不同总体均值之间的差距尽可能大)的原则,确定原始向量的投影方向,使训练样本投影到该方向时各类之间最大程度地分离,从而达到正确分类的目的。
假设有2个总体A、B,从第一个总体A中抽取n1个样品,从第二个总体中抽取n2个样品,每个样品有p个影响指标。已知来自总体A+B的训练样本为:
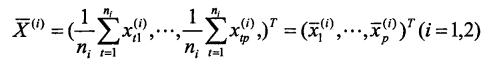
判别分析就是要根据这些数据,按照两组间的区别最大、而使每个组内部的离差最小的原则,确定判别函数,并找出临界值,然后对总体进行分类。
判别函数:
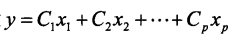
一、计算步骤
(1)计算两类样本的平均值:
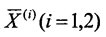
(2)计算两类样本的协方差矩阵S和总样本的协方差矩阵S:
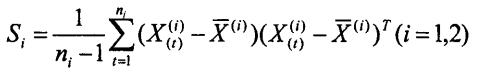
当两类总体的协方差矩阵的总和等于总协方差矩阵时,即为总样本的协方差矩阵S:
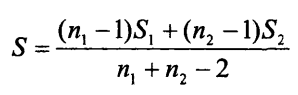
(3)建立最优判别函数:
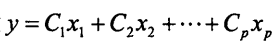
判别函数中的系数通过下式求得:
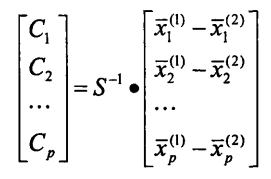
(4)计算判别临界值y0:
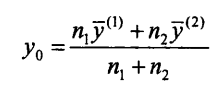
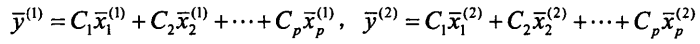
(5)确定判别准则:
对于一个新样品x= (x1,x2,…,xp)带入判别函数中所得计算值记为y,则判别准则为:

二、python代码实现
1.引入库
代码如下(示例):
利用numpy和pandas库
import numpy as np
import pandas as pd
2.读入数据
代码如下(示例):
通过excel文件读取两类样本,一类为“正”,另一类为“负”
Z_dataread = pd.read_excel(r"D:\\Sample_V2.xlsx", sheet_name='zheng')
F_dataread = pd.read_excel(r"D:\\Sample_V2.xlsx", sheet_name='fu')
利用pd.read_excel()读取表格数据为DataFrame。
3.获取总样本集
代码如下(示例):
将两类样本进行合并,获得总样本集
A = [Z_dataread , F_dataread]
A_data = pd.concat(A)
利用pd.concat()将两类样本合并。
4.计算样本数量
代码如下(示例):
统计两类样本的样本数,为判别函数提供基础数据
N1 = Z_dataread.shape
N2 = F_dataread.shape
NN1 = N1[0]
NN2 = N2[0]
NN1、NN2为样本行数。
5.样本计算及构建判别函数
1、计算两类样本均值:
Z_mean = Z_dataread.mean()
F_mean = F_dataread.mean()
2、计算两类样本及总样本的协方差矩阵:
Z_cov = Z_dataread.cov()
F_cov = F_dataread.cov()
A_cov = A_data.cov()
3、判别函数的C:
T=Z_mean-F_mean
C1 = A_cov.dot(T)
C2 = np.array(C1)
C1为计算完为41的矩阵,通过np.array函数转置成14的矩阵,这里可以用其他方法进行转置
4、计算临界值y0:
y1 = C2.dot(Z_mean)
y2 = C2.dot(F_mean)
y0 = (NN1*y1 + NN2*y2)/(NN1+NN2) #判别式
5、进行分类判别:
def pan(yn1,y0,y1,y2):
if y1 > y2:
if yn1 > y0:
New = '正'
elif yn1 < y0:
New = '负'
else:
New = '维持'
elif y1 < y2:
if yn1 > y0:
New = '负'
elif yn1 < y0:
New = '正'
else:
New = '维持'
return New
5.构建样本进行验证
样本中的特征值为4,也就是4列,因此利用几个样本数据进行验证:
1、构建样本数据:
n1 = pd.Series([-1,60,1,123])
n2 = pd.Series([5,90,5,321])
n3 = pd.Series([-1,95,2,345])
2、利用判别函数进行计算:
yn1 = C2.dot(n1)
yn2 = C2.dot(n2)
yn3 = C2.dot(n3)
3、计算结果与临界值y0对比,确认分类情况:
print(pan(yn1,y0,y1,y2))
print(pan(yn2,y0,y1,y2))
print(pan(yn3,y0,y1,y2))
4、将分类结果添加到验证数据的新列:
n11 = n1.append(pd.Series(pan(yn1,y0,y1,y2)))
n22 = n2.append(pd.Series(pan(yn2,y0,y1,y2)))
n33 = n3.append(pd.Series(pan(yn3,y0,y1,y2)))
总结
提示:这里对文章进行总结:
文章仅是对论文中所述的Fisher判别分析方法进行复现,在代码上仅以能实现为主。
有方法可以利用Fisher判别分析方法实现多特征分析,后续可以尝试复现一下。















 2278
2278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









