








论文总结
本文首先提出了三维目标检测中对于一些含有点云数量很少的目标,人类都难以辨别,此外,大部分的网络都是单独的考虑每一个proposal,这也大大加大了网络来辨别的难度。此外,作者通过观察发现,如果能够结合上下文信息的话,我们可能能够更加简单的辨别出所需要的目标。

上图是作者用来展示上下文信息的重要性的。如果单独拿一个目标出来,人类肉眼都难以辨别这个是什么类型的目标,但是如果知道这是一个餐厅的话,有60%的概率能够辨别出来是椅子,如果能够知道这个目标周围有社么的话,有85%的把握知道这是一个椅子,如果既知道是餐厅,又知道是厨房的话,就有90%的把握能够预测出是椅子。
因此,针对上面的现象,作者提出了多个层级的上下文信息提取模块。首先是patch2patch的上下文信息。patch应该指的是原始的点云场景中的一个局部区域。作者文中的解释是,通过相似的patch之间的互补来弥补一些目标点很少的问题。此外,由于votenet中仅单独的考虑每一个proposal,这没有充分的利用proposl中的上下文信息。因此作者还提出了一个objec2object的提取上下文信息的模块。此外,全局的上下文信息也能够再一定程度上为目标检测提供潜在的信息,作者还在网络中加入了全局的特征。
其具体流程如下:
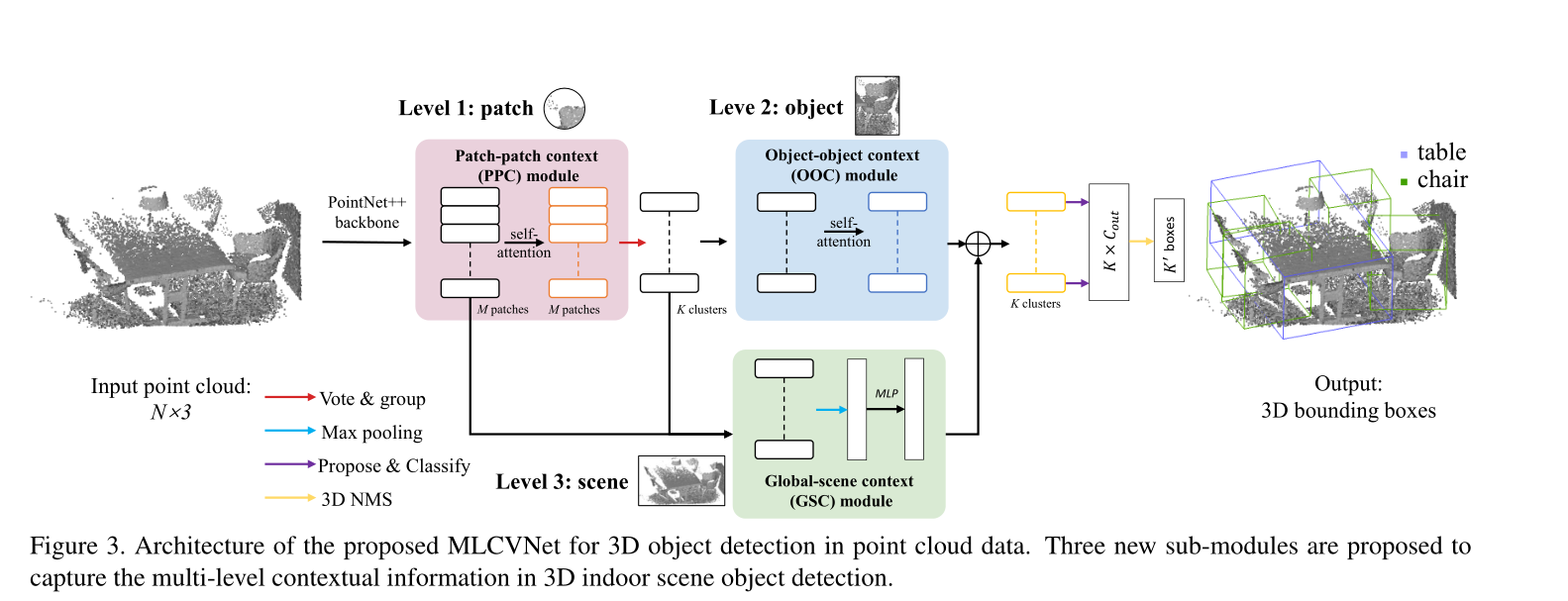
从上图可以看出,相比于传统的votenet网络,作者在voting之前加入了patch2patch的上下文信息提取网络,此外,作者在voting之后,也在各个proposal2proposal的上下文特征提取网络。此外,还增加了一个提取全局特征的分支。
其中第一层级的上下文信息patch的基本原理如下,首先使用PointNet++提取全局的特征。经过PointNet++提取特征后输出的点的特征表示的是该点所处的局部区域的所有点的特征。我们将这个局部区域称为点云空间的一个patch。然后作者针对这些patch使用self-attention结构来提取特征,使得每一个patch的特征都能受到场景中其他patch的影响,从而减轻因点云数据缺失带来的影响。
然后对于目标层级的上下文信息的提取,作者基本也是采取的同样的处理方式。
全局上下文信息的提取作者使用了未经过self-attention的Patch特征和Clusters的特征,将这些特征最大池化之后生成一个一维的向量,然后拼接起来经过一个MLP就生成了全局特征。将生成的全局特征和Object2Object Context模块的数据拼接用于三维边界框的计算。
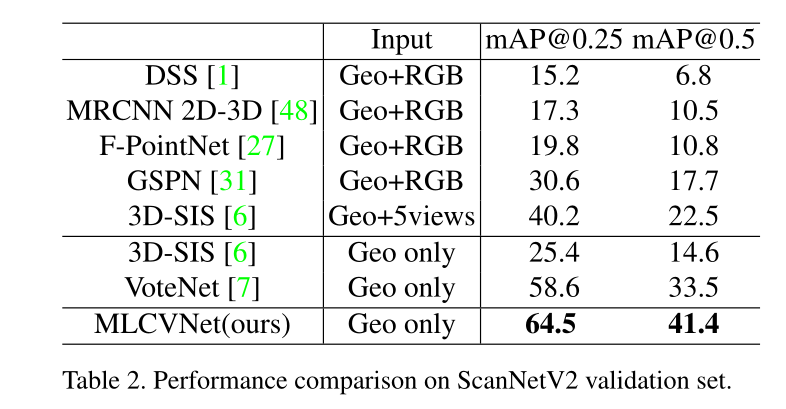
从上述表格中可以看出,相比于VoteNet,引入上下文特征之后大大提高了模型的检测性能。
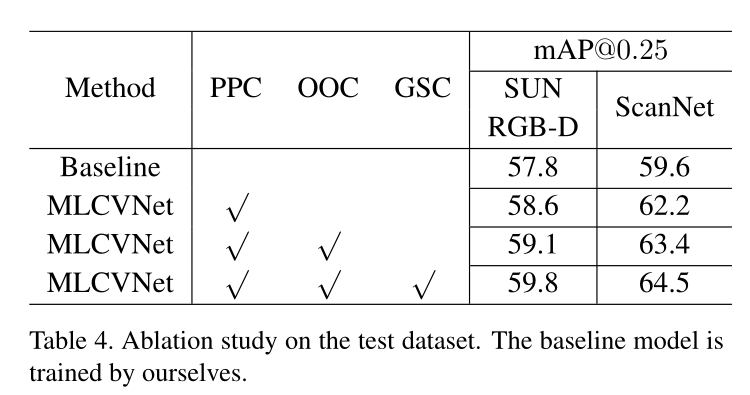
上述表格展示了不同的子模块对于模型性能的影响。















 4783
4783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









