







模式识别与机器学习老师留了作业说是让找一篇线性判别的论文,所以就记录一下论文(《Neighborhood linear discriminant analysis》)吧,虽然只是一些翻译。。。
LDA : linear discriminant analysis,线性判别分析
nLDA : neighborhood linear discriminant analysis,邻域线性判别分析
本文所使用的图片均来自《Neighborhood linear discriminant analysis》
论文来自
https://doi.org/10.1016/j.patcog.2021.108422
一.摘要
1.进行线性判别的前提假设是同一类别的所有样本都是独立且有着相同的分布(i.i.d),因此假设不成立的时候,无法进行线性判别
2.本文提出了一种邻域线性判别分析,来缓解这个问题
3.在本文的方法中,邻域被视为最小的子类,不需要借助任何聚类算法就可以比子类更容易获得。
4.投射方向的寻求是为了使邻域内的散点近可能的小,邻域间的散点尽可能的大。
二.简介
1.线性判别是一种广泛使用的监督降维方法,它都是在类的层面上进行定义的(是类内的散点最小化,类间的散点最大化)。因此它需要假设同一类别的样本遵循同样的分布。
2.而在现实世界的数据中,有一些类是由几个分离的子类或聚类组成的多模态。
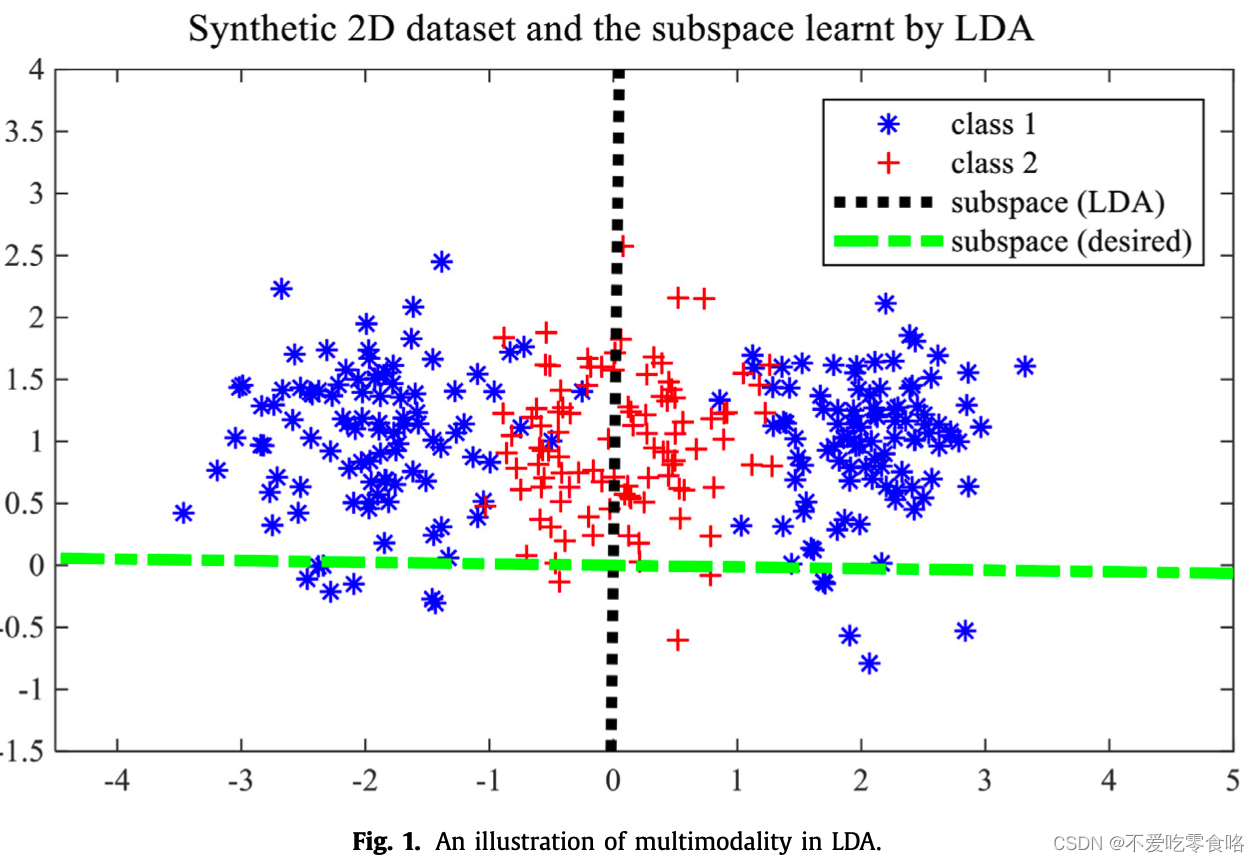
(图片来自论文《Neighborhood linear discriminant analysis》)
3.上图是一个多模态人工合成的例子,其中第一类用星星表示,第二类用加号表示。一个黑色竖直的虚线是线性判别分析得出来的投影子空间,而黄色水平的虚线可以由考虑类内多模态的判别器获得。很容易可以看出,在线性判别分析的投影子空间中,第一类和第二类是混在一起的,所以说它的分析没有成功。
4.线性判别分析可能无法在包含任何多模态的数据集上工作。因为它的散点矩阵是在类的水平上确定的,没有考虑类的内部结构。
5.一种直接的解决方法就是使用聚类算法,在聚类或子类层面上来确定散点矩阵。(如果没有对类内部的多模态进行预先了解,确定聚类或子类的数量是很困难的。)
6.因此本文提出了使用领域信息来定义散点矩阵。使用邻域间散点和邻域内散点来代替类间散点和类内散点。从而可以将邻域作为做小的子类,它不需要任何关于一个类的内部结构的先验知识。
7.本文方法得到的判别器被称为邻域线性判别分析(nLDA)。它继承了Fisher判别,可以作为一个广义的特征向量问题来解决。
8.邻域通过Parzen窗口、K近邻、反向最近邻来获得。
9.本文使用了反向最近邻的方法,它是一种先进的无监督群点检测方法,可以排除训练集中的一些“孤点”。本文想要的效果是属于同一类别的样本应尽可能地接近,不同类别的样本应尽可能地远离。
10.基于反向最近邻的散点没有直接考虑完整的类,因此可以解决数据集中包含多模态类的问题。
三.相关工作
1.线性判别分析在很多领域已经被广泛使用。 但是它有一些缺点,比如:
a.对噪声敏感
b.类内分散矩阵可能是不可逆的
c.多模态数据集无法使用线性判别
2.经典的线性判别使用的是第二范数
3.后面讲的都是一些改进方法,暂时先不看了。。。。直接看本文的方法
四.邻域线性判别分析
1.回顾线性判别的过程
a.作为训练集,由
组成(i=1,...,n,
∈
),
是属于j类所有的样本,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









