







人工智能主要分支
人工智能、机器学习和深度学习的关系
机器学习是人工智能的一个实现途径,深度学习是机器学习的一个方法发展而来——神经网络。
主要分支介绍
计算机视觉
计算机视觉(CV)是指机器感知环境的能力。
语音识别
语音识别是指识别语音并将其转换成对应文本的技术,目前主要的技术壁垒是「鸡尾酒会效应」,无法识别对象是不是在和机器对话。
文本挖掘/分类
指文本分类,该技术可用于理解、组织和分类结构化和非结构化的文档。
机器翻译
机器翻译(MT)是利用机器的力量自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
机器人
机器人学研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。
机器人可以分为固定机器人和移动机器人。
人工智能发展必备三要素
- 数据
- 算法
- 计算力
GPU和CPU的区别
GPU更适合计算密集型的程序,易于并行的程序,CPU更适合IO密集型的程序。
机器学习工作流程
什么是机器学习
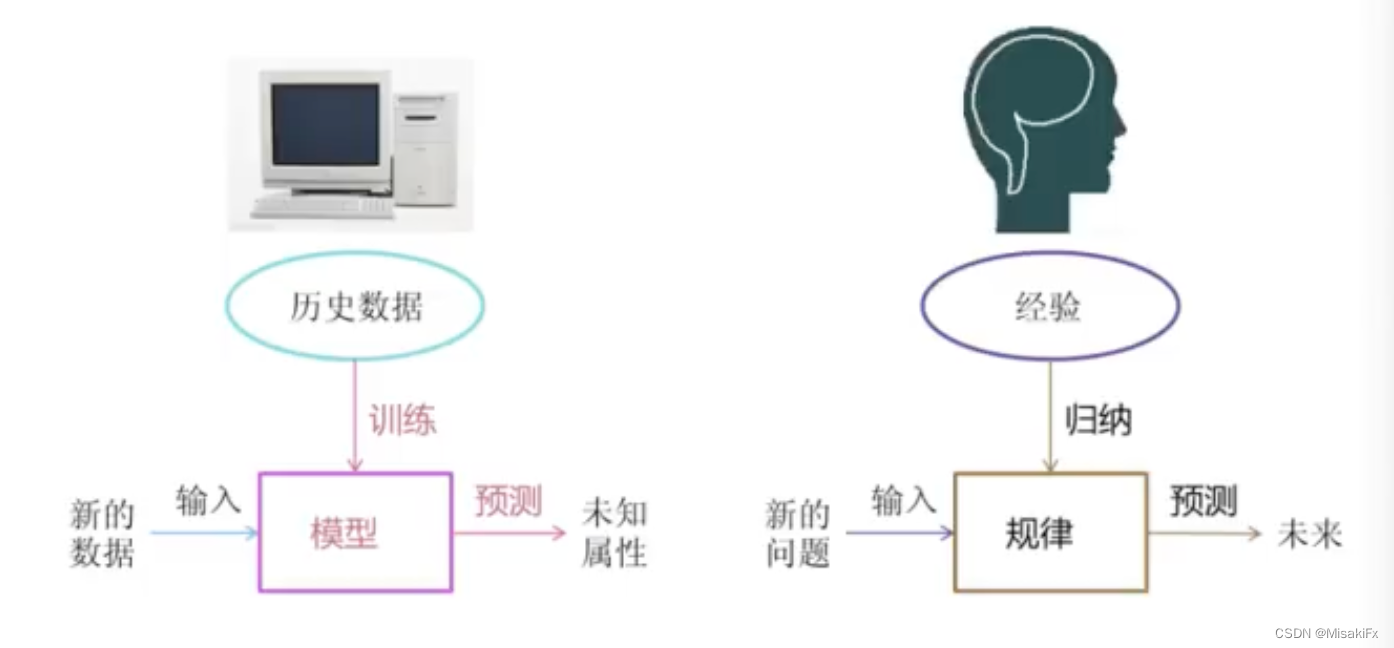
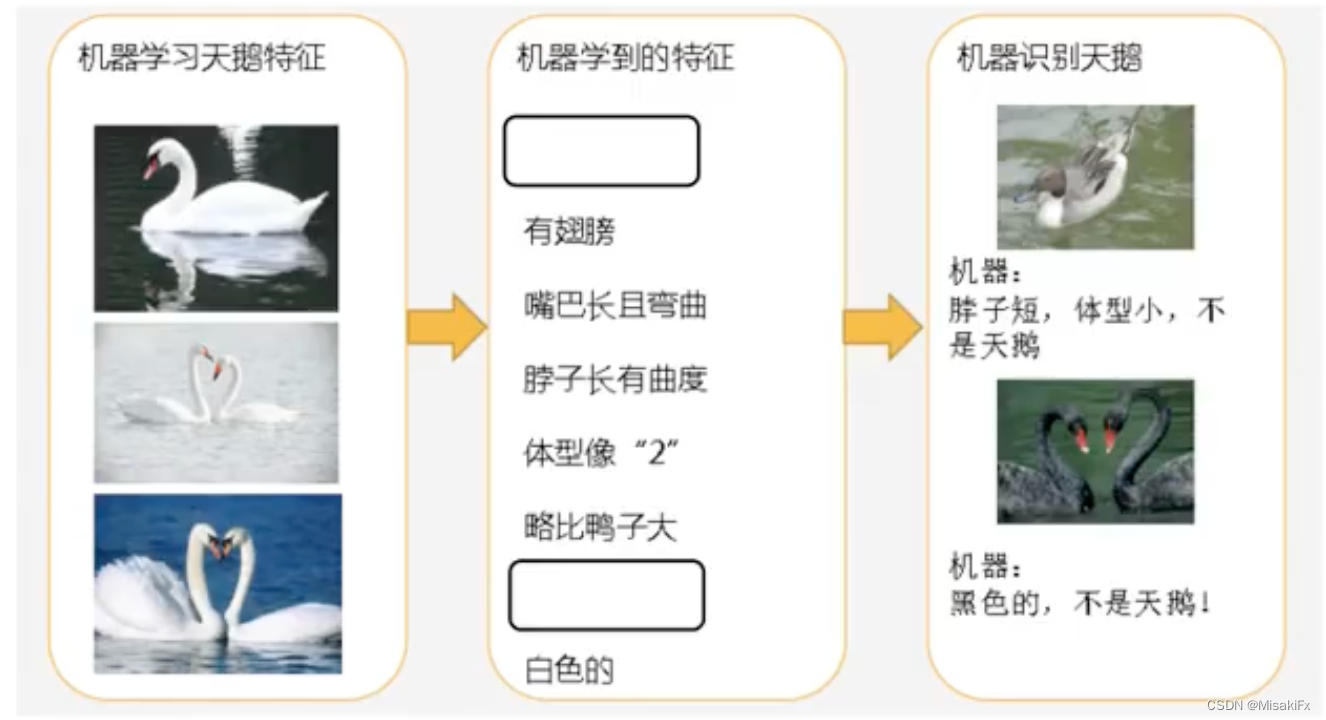
机器学习是从数据中自动分析获得模型,并利用模型对位置数据进行预测。
机器学习工作流程
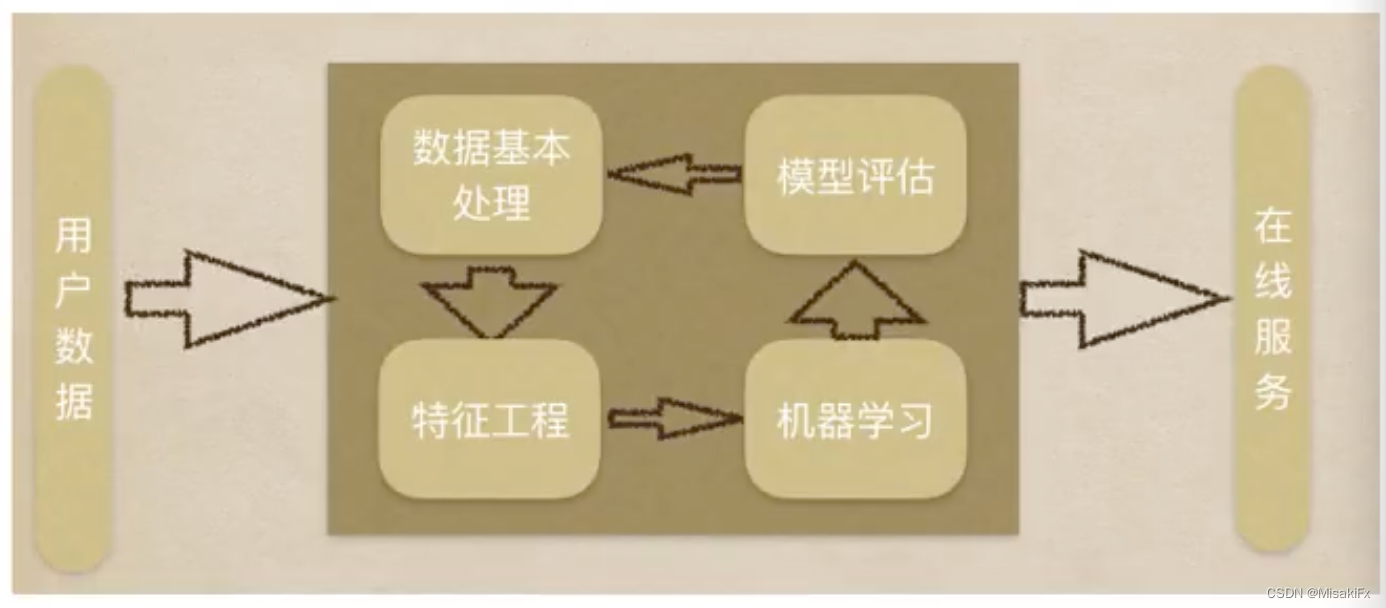
机器学习工作流程可以分为以下5个流程,他们之间不断循环往复,优化模型。
- 获取数据
- 数据基本处理
- 特征工程
- 机器学习(模型训练)
- 模型评估
数据集
数据简介
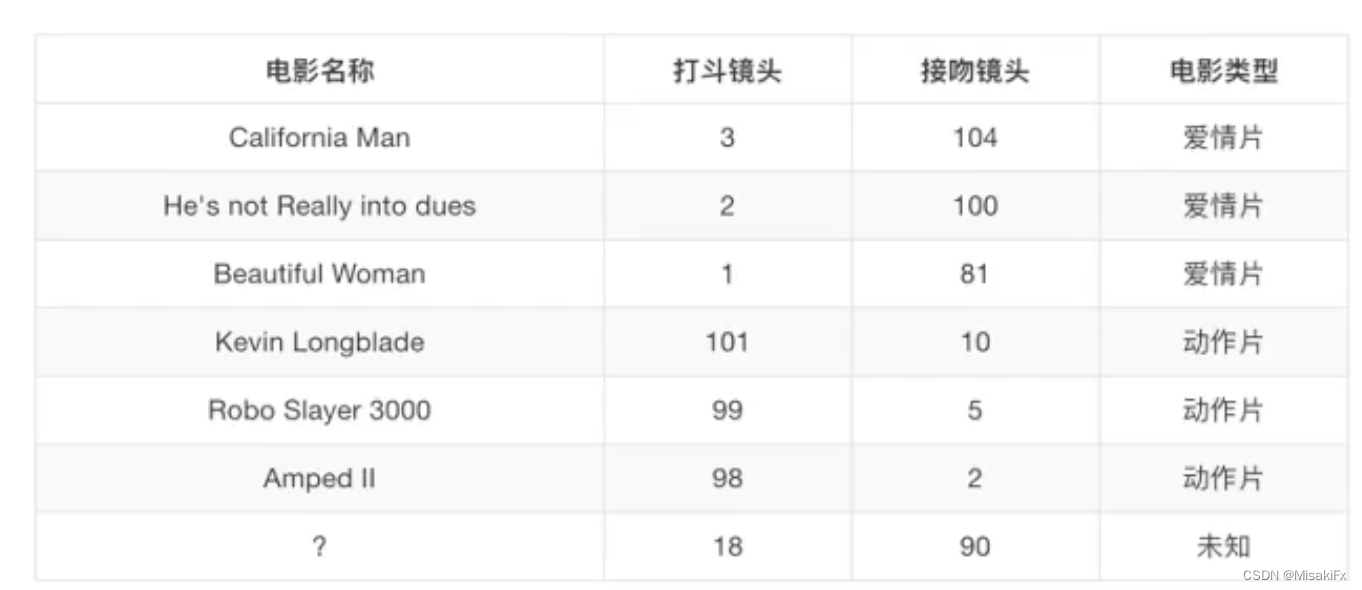
样本:一行数据称为一个样本。
特征:一列数据称为一个特征。
目标值:要预测的目标就是目标值。
特征值:某一特征具体的值。
比如上图中我们根据打斗镜头和接吻镜头对电影的类型进行预测,打斗镜头和接吻镜头就是特征,每一部电影的数据就是一条样本,最终要预测电影类型就是目标值。
数据类型构成
数据类型一:特征值+目标值,一般用于监督学习。
数据类型二:只有特征值,一般用于无监督学习。
数据分割
一般要将数据集按照一定比例划分为训练数据和测试数据。
训练数据:用于训练,构建模型。
测试数据:在模型检验时使用,用于评估模型。
一般是按照80%/20%,或者70%/30%分割。
数据基本处理
是对数据进行缺失值、去除异常值等处理。
特征工程
什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
特征工程内容
-
特征提取
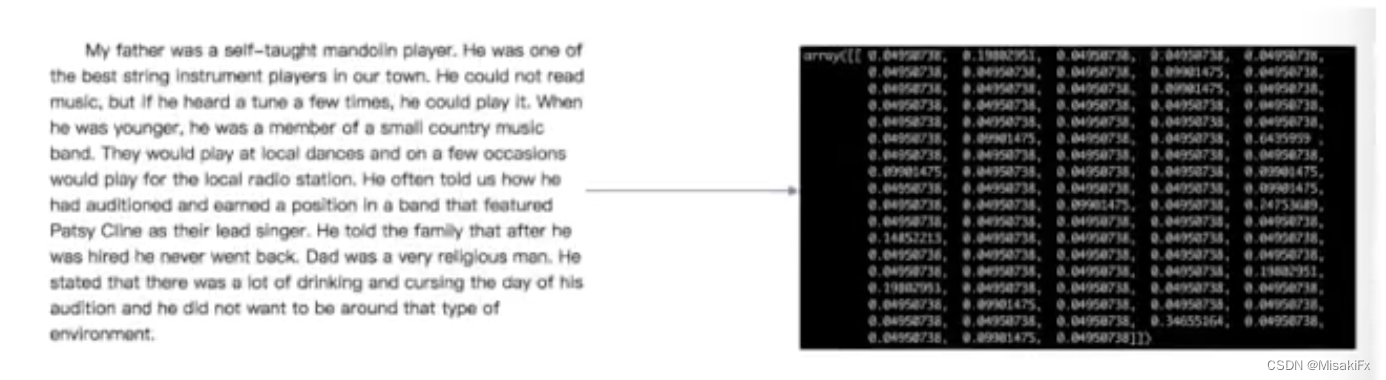
将任意数据(文本图像等)转换为可用于机器学习的数字特征。 -
特征预处理
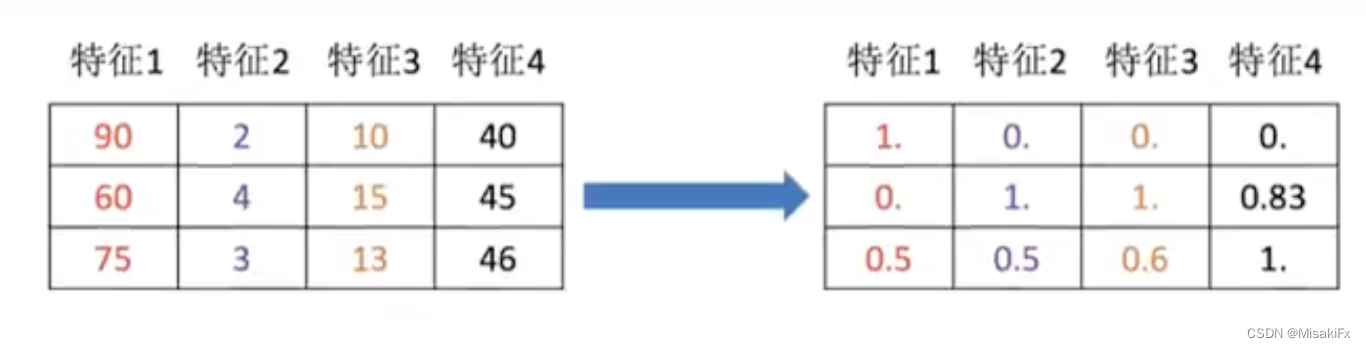
通过一些转换函数将特征数据转换为更适合算法模型的特征数据过程。 -
特征降维
在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
机器学习算法分类
分为监督学习,无监督学习,半监督学习和强化学习。
监督学习
监督学习针对的是有特征值有目标值的算法。其中函数输出如果是连续的值就称为回归,如果是离散的则称为分类。
常见的回归问题比如根据房子大小预测房子价格,分类问题比如根据年龄大小预测肿瘤良性还是恶性。
无监督学习
输入的数据集是只由特征值构成的问题则是无监督学习,由机器根据特征自行给出答案,无标准答案,比如常见的聚类问题。
半监督学习
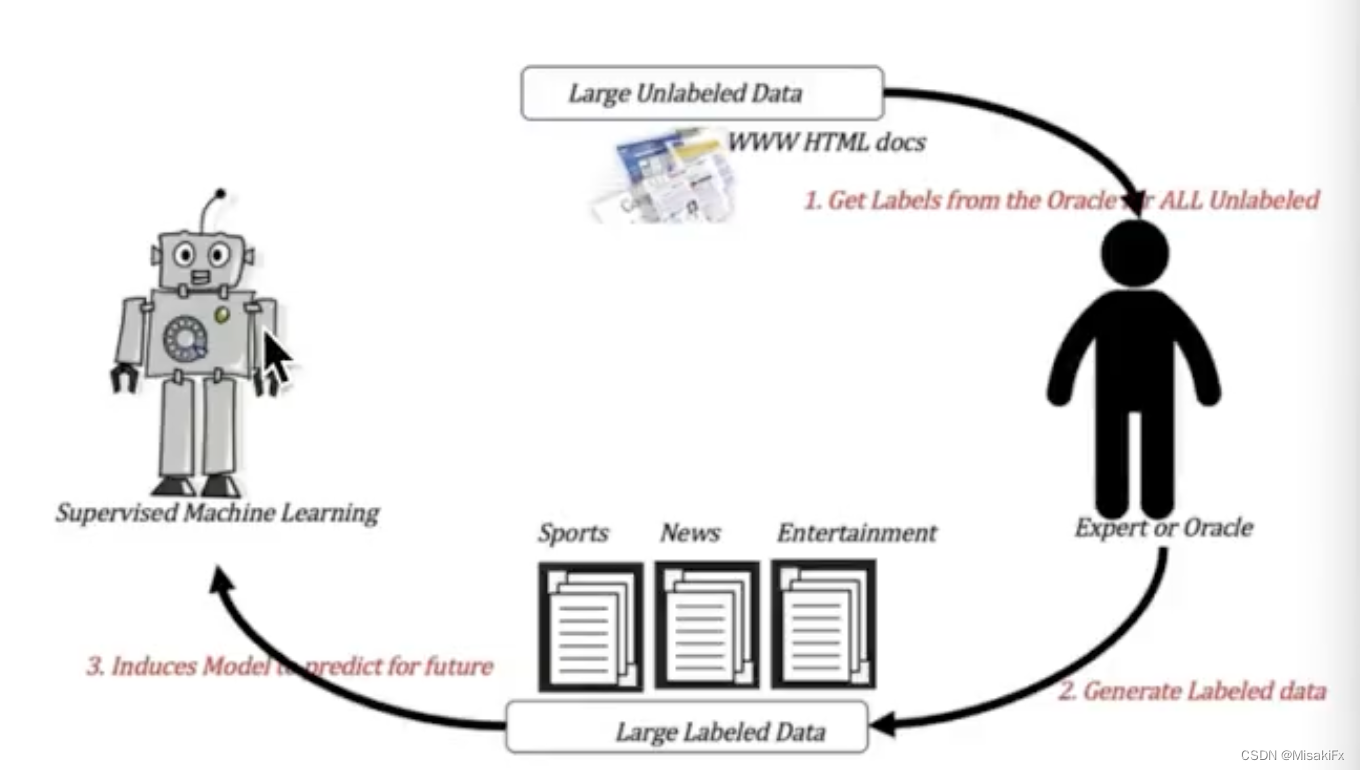
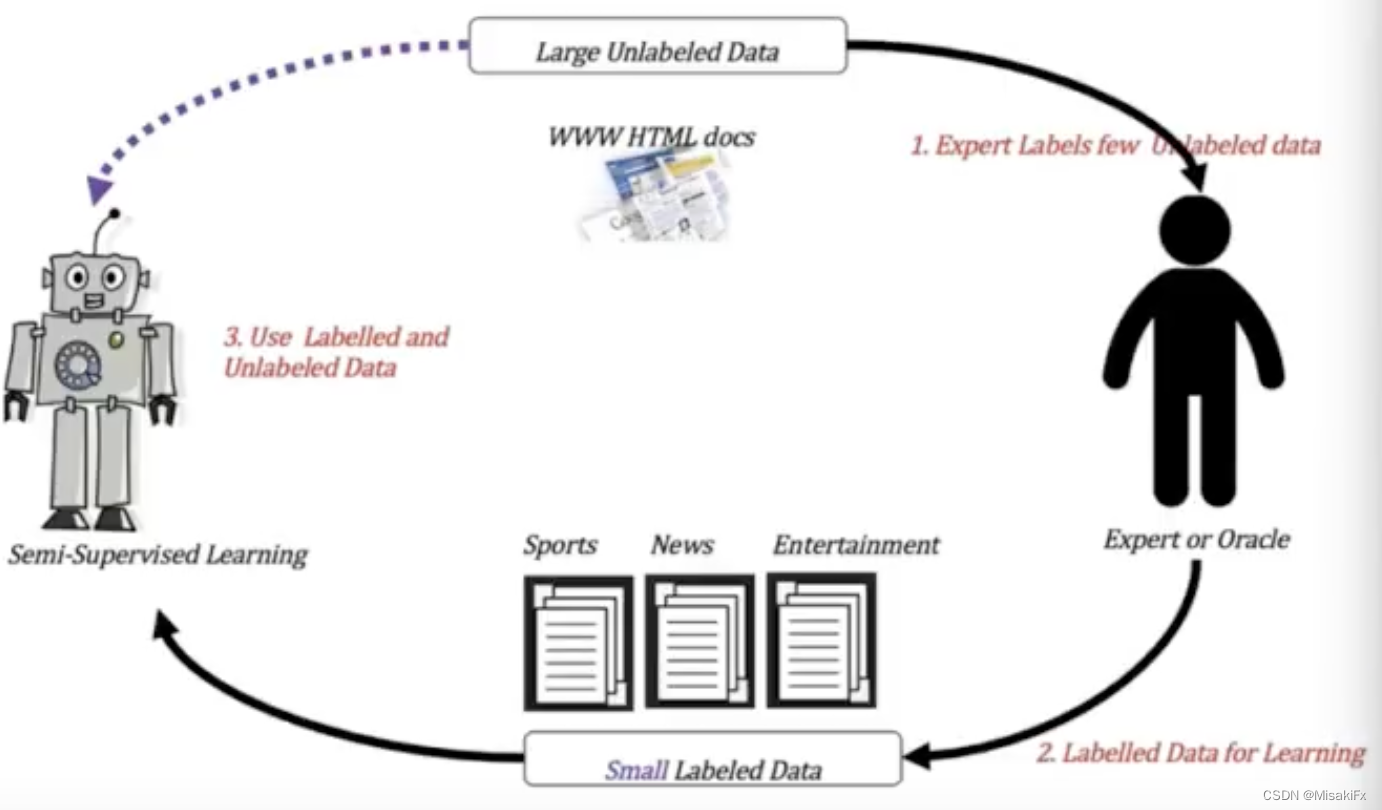
监督学习拿到的初始数据集都是经过专家打标有明确的目标值,而大量数据如果都进行明确打标可能会有很高人力成本,所以产生了半监督学习。半监督学习只拿一小部分数据去让专家打标获取目标值,剩下的大部分数据会直接交给半监督学习模型,把两部分数据一起交给模型进行训练。
强化学习
钱花学习是让模型自己进行决策,通过正反馈或者负反馈的方式让模型作出正确的决策。
模型评估
分类模型评估
常见评估指标:
- 准确率
- 预测正确的数占样本总数的比例。
- 精确率
- 正确预测为正占全部预测为正的比例。
- 召回率
- 正确预测为正占全部正样本的比例。
- F1-score
- 主要用于评估模型的稳健性。
- AUC指标
- 主要用于评估样本不均衡的情况。
回归模型评估
- 均方根误差(RMSE)。RMSE是一个衡量回归模型误差率的常用公式,它仅能比较误差是相同单位的模型。
R M S E = ∑ i = 1 n ( p i − a i ) 2 n RMSE=\sqrt{\frac{\sum^{n}_{i=1}(p_{i}-a_{i})^2}{n}} RMSE=n∑i=1n(pi−ai)2 - 相对平方误差(RSE)。RSE可以比较误差是不同单位的模型,与RMSE作用相同。
R S E = ∑ i = 1 n ( p i − a i ) 2 ∑ i = 1 n ( a ˉ − a i ) 2 RSE=\frac{\sum^{n}_{i=1}(p_i-a_i)^2}{\sum^{n}_{i=1}(\bar{a}-a_{i})^2} RSE=∑i=1n(aˉ−ai)2∑i=1n(pi−ai)2 - 平均绝对误差(MAE)。MAE与原始数据单位相同,它仅能比较误差是相同单位的模型。量级近似于RMSE,但是误差值回相对小一些。
M A E = ∑ i = 1 n ∣ p i − a i ∣ n MAE=\frac{\sum^{n}_{i=1}|p_i-a_i|}{n} MAE=n∑i=1n∣pi−ai∣ - 相对绝对误差(RAE)。与MAE不同,RAE可以比较误差是不同单位的模型。
R A E = ∑ i = 1 n ∣ p i − a i ∣ ∑ i = 1 n ∣ a ˉ − a i ∣ RAE=\frac{\sum^n_{i=1}|p_i-a_i|}{\sum^n_{i=1}|\bar{a}-a_i|} RAE=∑i=1n∣aˉ−ai∣∑i=1n∣pi−ai∣ - 决定系数。决定系数(
R
2
R^2
R2)回归模型汇总了回归模型的解释度,由平方和术语计算而得。
R 2 = 1 − ∑ i = 1 n ( p i − a i ) 2 ∑ i = 1 n ( a i − a ˉ ) 2 R^2=1-\frac{\sum^n_{i=1}(p_i-a_i)^2}{\sum^n_{i=1}(a_i-\bar{a})^2} R2=1−∑i=1n(ai−aˉ)2∑i=1n(pi−ai)2
拟合
模型评估用于评价训练好的模型的表现效果,其表现效果大致可分为两类:过拟合、欠拟合。
- 欠拟合:模型学习到的特征过少,导致分类标准粗糙,无法正确分类。
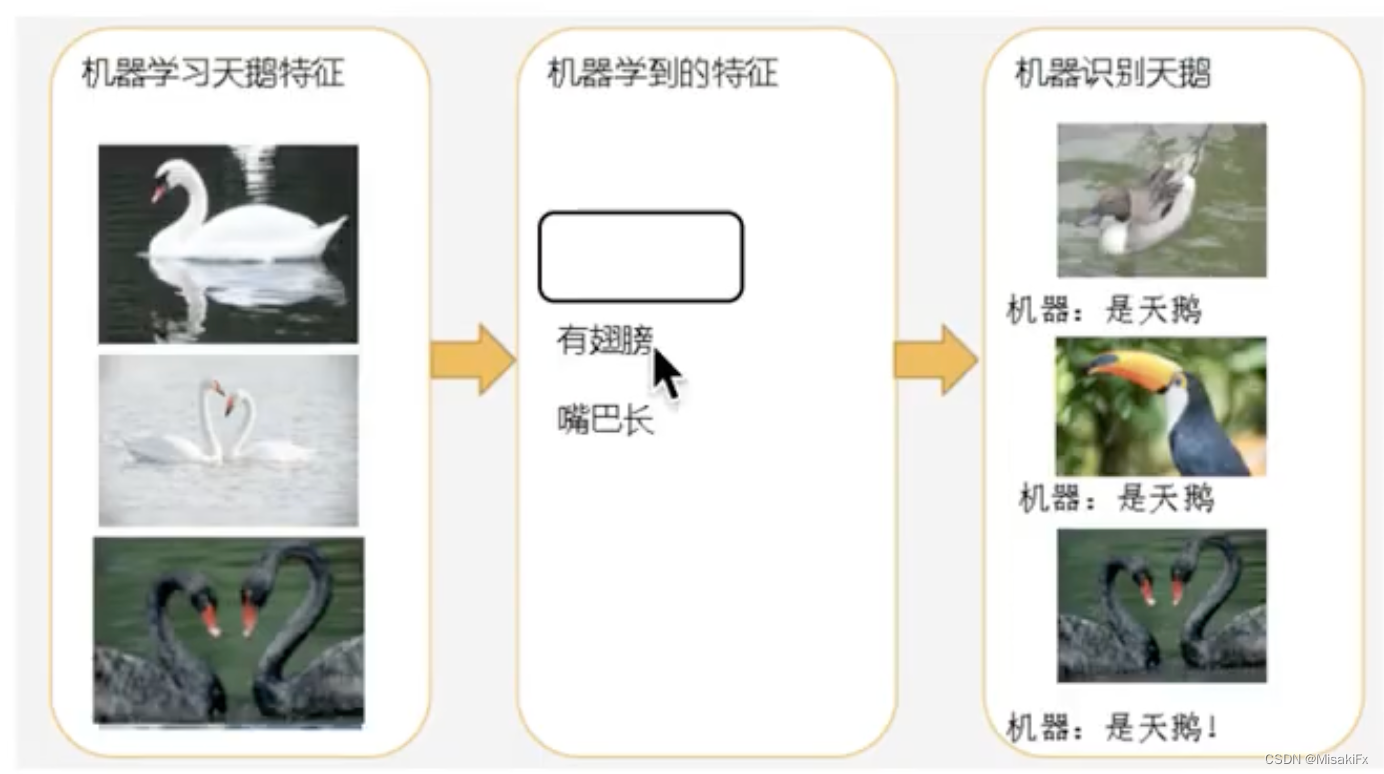
- 过拟合:所建的模型在训练样本中表现过于优越,学习的特征过多,导致在验证数据集一集测试数据集中表现不佳。














 4186
4186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









