







mini-batch梯度下降法
mini-batch梯度下降法的介绍

但是当m是一个很大的数(比如500W),在对整个训练集执行梯度下降算法的时候,我们必须处理整个数据集,才能进行下一步梯度下降算法。然后我们需要重新处理500W个训练样本,才能进行下一步梯度下降算法。
所以如果你在处理完整个500W个训练样本之前,先让梯度下降算法处理一部分,你的算法速度会更快。
In particular, here is what you can do.
我们可以把训练集分割成小一点的子训练集,这些子集被取名为mini-batch。
假设每一个子集只有1000个样本。那么你其中的x(1)到x(1000)取出来,将其称为第一个子训练集X{1}。然后再取出接下来的1000个样本,称为X{2}。最后我们得到5000个mini-batch。
在这里在明确一下符号:
- 小括号 i 表示训练集里的值,即x(i)是第 i 个训练样本。
- 中括号 i 表示来表示神经网络的层数,即z[l]表示神经网络第 l 层的 z 值(W,b同理)。
- 大括号 t 来代表不同的mini-batch,所以我们有X{t}, Y{t}。其中在这里X{t}的维度应该是(n_x, 1000),Y{t}的维度应该是(1, 1000)
mini-batch梯度下降法的前向传播和反向传播
前向传播

- Z[1] = W[1] + b[1]
- A[1] = g[1](Z[1])
- ……
- A[L] = g[L](Z[L])
cost J{t} = 如上图
另外需要注意的是,前向传播过程中依旧用到矢量化编程。
反向传播
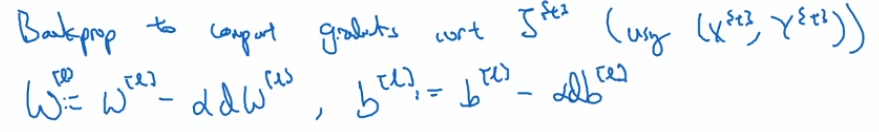
W[l]=W[l] - α * dW[l]
b[l]=b[l] - α * db[l]
batch梯度下降 or mini-batch梯度下降
mini-batch梯度下降法与batch梯度下降算法的不同仅仅是将X,Y变为X{t},Y{t}。
使用batch梯度下降法,每次迭代你都需要遍历整个训练集(而一次遍历训练集只能让你做一个梯度下降),可以预期每次迭代的成本都会下降。

使用mini-batch梯度下降法,一次遍历训练集能让你做number of Sample/mini-batch个梯度下降。
但是需要注意的是,使用mini-batch梯度下降法,则并不是每一次迭代的cost都是下降的。
特别是在每次迭代中,我们要处理的是X{t}, Y{t},如果要做出成本函数J{t}的图,而J{t}只与X{t}, Y{t}有关。
也就是说每次迭代下我们都在训练不同的训练集(不同的mini-batch),所以成本函数J的图像可能长这样,趋势是减小但有噪声。

当然正常来说,我们想要多次遍历训练集(还需要另外一个for循环或while循环),来一直处理遍历训练集,直到最后收敛到一个合适的精度。
如果你有一个丢失的训练集(When you have a lost training set)(???),mini-batch梯度下降法比batch梯度下降法运行得更快。
所以几乎每个研习深度学习的人,在训练巨大的数据集时都会用到mini-batch梯度下降法
超参数batch(或batch-size)
batch-size的不同的设定结果
m是训练集的大小,下面我们考虑几种情况。
batch-size=m:batch梯度下降法
完全等同于batch梯度下降法。
缺点是: 每次迭代消耗的时间太长。(所以仅限于训练样本不大的时候)
batch-size=1:随机梯度下降法stochastic gradient descent
每个样本Sample都是独立的mini-batch。即(X{n}, Y{n}) = (x(n), y(n))。
一次只处理一个Sample。
缺点是: 你会失去所有向量化带来的加速,导致效率过于低下。
1<batch-size<m:
这是我们在实际中的选择。
这样一方面我们得到了大量向量化,另一方面也能更快的make progress。
不同的batch-size对成本函数J的减小的影响

batch梯度下降法从某处开始,相对噪音低一些,幅度也大一些,是可以找到最小值的。
随机梯度下降法从某一点开始,每次迭代只对一个样本进行梯度下降。所以大部分时候我们向着全局最小值靠近,但有时候会远离最小值(哪个样本恰好给你指的方向不对)。
因此随机梯度下降法是有很多噪声的,但平均来看它最终会靠近最小值。随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。但它并不会在达到最小值并在此停留。
批处理(1<batch-size<m),它不会总朝着最小值靠近,但要比随机梯度下降更持续地靠近最小值的方向。它也不一定在很小的范围内收敛或波动,可以用学习率衰减learning rate decay来解决。
batch-size的确定
- 如果训练集比较小(small training set)(<2000 Samples):
直接使用batch梯度下降法。 - 更大的训练集(bigger training set):
typical batch-size:一般为62~512。
考虑到电脑内存设置和使用的方式,batch-size如果是2的次方,代码会运行得快一些。
X{t}, Y{t}要符合CPU/GPU内存,者取决于你的应用方向以及训练集的大小。如果你处理的mini-batch和CPU/GPU内存,算法的表现会急转直下到惨不忍睹。(说实话我没懂)















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









