







本文主要讲解该算法的实现过程
实验环境
python3.6+pytorch1.2+cuda10.1
数据集
102 Category Flower Dataset数据集由102类产自英国的花卉组成,每类由40-258张图片组成
下边使用的数据集看好多人私信要,我就上传到CSDN了:鲜花分类集(已划分)-深度学习文档类资源-CSDN下载
下边是代码实现过程及讲解
数据加载
#选择设备
device = torch.device("cuda:0")
#对三种数据集进行不同预处理,对训练数据进行加强
data_transforms = {
'train': transforms.Compose([
transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
#数据目录
data_dir = "./data"
#获取三个数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'valid','test']}
traindataset = image_datasets['train']
validdataset = image_datasets['valid']
testdataset = image_datasets['test']
batch_size = 8
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size,
shuffle=True, num_workers=4) for x in ['train', 'valid','test']}
print(dataloaders)
traindataloader = dataloaders['train']
validdataloader = dataloaders['valid']
testdataloader = dataloaders['test']
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid','test']}定义网络结构
使用ResNet152
#使用resnet152的网络结构,最后一层全连接重写输出102
class Net(nn.Module):
def __init__(self,model):
super(Net,self).__init__()
self.resnet = nn.Sequential(*list(model.children())[:-1])
#可以选择冻结卷积层
# for p in self.parameters():
# p.requires_grad = False
self.fc = nn.Linear(in_features=2048,out_features=102)
def forward(self,x):
x = self.resnet(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
resnet152 = models.resnet152(pretrained=True)
net = Net(resnet152)使用VGG19
class Net(nn.Module):
def __init__(self,model):
super(Net,self).__init__()
self.features = model.features
# for p in self.parameters():
# p.requires_grad = False
self.classifier = nn.Sequential(
nn.Linear(25088, 4096,bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(4096, 4096,bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(4096, 102,bias=True)
)
def forward(self,x):
x = self.features(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
vgg = models.vgg19(pretrained=True)
net = Net(vgg)参数设定
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(filter(lambda p: p.requires_grad, net.parameters()),lr=0.0001,momentum=0.9)测试集检验
def valid_model(model, criterion):
best_acc = 0.0
print('-' * 10)
running_loss = 0.0
running_corrects = 0
model = model.to(device)
for inputs, labels in validdataloader:
inputs = inputs.to(device)
labels = labels.to(device)
model.eval()
with torch.no_grad():
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
running_loss += loss.item()
running_corrects += torch.sum(preds == labels)
epoch_loss = running_loss / dataset_sizes['valid']
print(running_corrects.double())
epoch_acc = running_corrects.double() / dataset_sizes['valid']
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
'valid', epoch_loss, epoch_acc))
print('-' * 10)
print()验证集检验
def test_model(model, criterion):
best_acc = 0.0
print('-' * 10)
running_loss = 0.0
running_corrects = 0
model = model.to(device)
for inputs, labels in testdataloader:
inputs = inputs.to(device)
labels = labels.to(device)
model.eval()
with torch.no_grad():
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
running_loss += loss.item()
running_corrects += torch.sum(preds == labels)
epoch_loss = running_loss / dataset_sizes['test']
print(running_corrects.double())
epoch_acc = running_corrects.double() / dataset_sizes['test']
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
'test', epoch_loss, epoch_acc))
print('-' * 10)
print()
训练模型
def train_model(model, criterion, optimizer, num_epochs=5):
since = time.time()
best_acc = 0.0
for epoch in range(num_epochs):
if (epoch+1)%5==0:
test_model(model, criterion)
print('-' * 10)
print('Epoch {}/{}'.format(epoch+1, num_epochs))
running_loss = 0.0
running_corrects = 0
model = model.to(device)
for inputs, labels in traindataloader:
inputs = inputs.to(device)
labels = labels.to(device)
model.train()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item()
running_corrects += torch.sum(preds == labels)
epoch_loss = running_loss / dataset_sizes['train']
print(dataset_sizes['train'])
print(running_corrects.double())
epoch_acc = running_corrects.double() / dataset_sizes['train']
best_acc = max(best_acc,epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
'train', epoch_loss, epoch_acc))
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
return model开始训练
epochs = 48
model = train_model(net, criterion, optimizer, epochs)
valid_model(model,criterion)
torch.save(model, 'model.pkl')输出结果
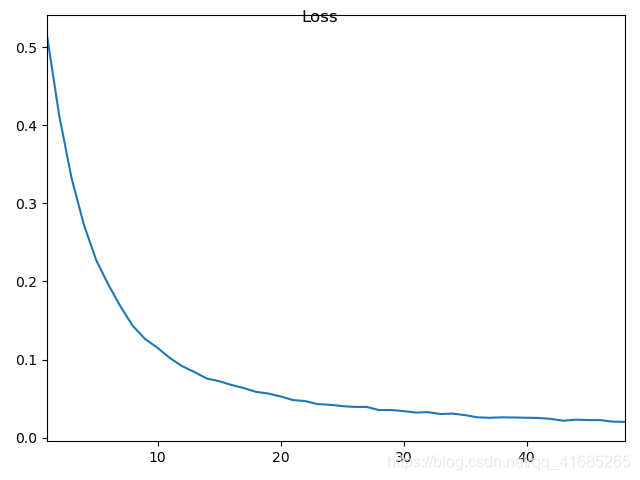
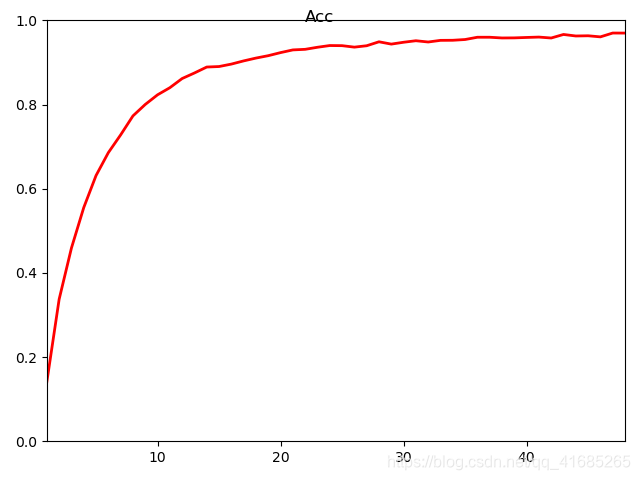
在最后,训练集的精度达到了97.01%,测试集上达到了97.45%
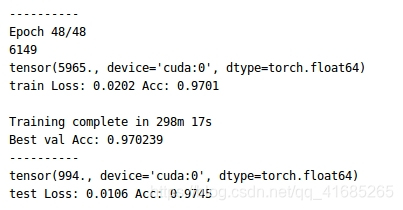


















 5176
5176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











