









引言:AI与大模型风起云涌,催生了这匹存储“黑马”
【全球存储观察 | 科技热点关注】
这家总部设在美国的存储初创公司,真的赶上AI与大模型时代的风口了。Vast Data公司最新再次获得E轮融资1.18亿美元,但是这个存储公司融来的资金还没想好怎么用,现在只是和之前ABCD轮融资一道存银行吃利息而已。你是不是被震惊到了?
目前VAST Data该E轮已经筹集了1.18亿美元的新资金,由 Fidelity Ventures 领投,New Enterprise Associates、BOND Capital、Drive Capital、Nvidia、Dell Technologies Capital、高盛、Tiger Global、Commonfund、Norwest、83North、Greenfield和Next47跟投。估值为91亿美元,ABCDE轮筹集的现金总额达到3.81亿美元,约合人民币27.3亿元。
查阅已经被公开的资料发现,VAST Data天使轮融资0.15亿美元,A轮融资0.25亿美元,B轮融资0.4亿美元,C轮融资1亿美元,D轮0.83亿美元。其中Dell Technologies Capital在ABCDE五轮融资中都有参与。
VAST Data公司在全球拥有700多名员工,2016年,Renen Hallak与Jeff Denworth、曾在Kaminario和IBM担任领导职务的Shachar Fienblit和曾在Cisco和IBM担任领导职务的Alon Horev共同在美国纽约创立。
VAST Data通过使用底层QLC闪存,结合由SCM类型的SSD加速,同时关键的是在于分离了控制器和存储节点,并提供对文件和对象数据的并行横向扩展访问。最终实现了利用商用服务器硬件,为人工智能工作负载提供对大规模的数据集的更快访问。
Vast将存储、数据库和计算引擎服务统一在一个平台中,为跨数据中心和云的AI应用,以及GPU工作负载加速提供能力支持。
这样也就为用户省去了找一个集成商去整合NAS解决方案、对象存储、并行文件系统和数据仓库等构件一个复杂方案。麦肯锡(McKinsey)的数据显示,生成式AI预计将为全球经济创造2至4万亿美元市场价值,而其中GPU将为此提供大部分价值。VAST Data统一数据平台,可以为用户在AIGC应用上省钱,这个事情确实很吸引人。
为此,前几天,GPU云服务商CoreWeave的首席执行官兼联合创始人Michael Intrator表示,通过与VAST Data合作,能够使设施比传统云基础设施快35倍,成本低80%。如此看来,VAST Data公司的产业生态也逐渐在打开了。
值得一提的是,VAST Data平台已经通过Nvidia GPU Direct访问认证,并在其上构建了数据目录和数据库,以及即将推出的数据引擎,该引擎承诺使人工智能流程能够发现其所分析数据的新见解。随着人工智能不断被大肆宣传,也就成为了VAST Data筹集风投资金的好时机。
值得注意的是,VAST表示,这笔资金将推进其使命,提供一个新的基础设施类别,将数据放在系统工作的中心。目前还没有关于这些现金将如何实际使用的细节。
事实上,VAST Data联合创始人Jeff Denworth说:"这笔资金只是被用来提高人们对VAST和我们使命的认识。 VAST现在的现金流非常顺畅,业务拓展也很有建树。我们已经成功地建立了一个公司,它可以每年增加三倍的业务量,而不用烧掉堆积如山的风险投资。这笔新的E轮融资将与我们从B轮、C轮和D轮融资中获得的资金一起存在银行并收取利息。"
如此说来,除去天使轮与A轮的0.4亿美元融资,其他融资总共有3.41亿美元,约合人民币24.4亿元。
现在的VAST Data Universal Storage 5.0能力更为强大,针对在云方面的融合能力,VAST DataSpace拥有多集群管理器、快照、复制等技术功能,简化用户的云部署,目前可以看到Vast Data与亚马逊云科技AWS的对接。
针对AI与大模型训练等以性能为中心的应用场景而言,Vast Data强调为用户提供更细粒度的QoS保障,采用全新的用户级控制为每个使用者行为设置了护栏,并利用人工智能特别是深度学习的能力,监控存储系统中使用者的行为,并且可以限定任何一位高级用户可能破坏其他人的数据访问体验。
Vast Data的现任CMO Marianne Budnik表示,在不到一年的时间里,新一代人工智能重塑了数据基础设施的格局,并对高度可扩展、高性能和安全的系统提出了新的要求,这些系统可以应对大型语言模型带来的独特挑战。新的专用云已经形成,以满足人工智能特定的用例。企业越来越专注于构建AIGC相关应用并更好支持客户发展。
在2022年11月ChatGPT推出后,大多数组织今天正在探索生成性人工智能用例,许多组织正在进行重大投资。由于人工智能应用程序旨在从大量数据中提取见解,因此它们需要具有最高规模和性能的基础设施。
人工智能计算下一个时代的基础只能通过解决以前阻碍人工智能应用进行实时数据处理和学习的基本基础设施权衡来建立。对于非结构化数据存储,这意味着以文件和对象存储的VAST DataStore模式已经打破性能和容量之间的权衡。
通过VAST DataStore,可以摆脱存储分层复杂性,成为企业人工智能就绪的非结构化数据存储的基础,甚至VAST也成为了HPE GreenLake文件存储背后的软件。
业界的评价还是很有亮点,VAST Data成为了用于生成AI的最有效的存储平台,可以容纳多个访问协议,并独立扩展性能和容量,允许按需性能灵活性和长期成本效益。VAST自第一天起就一直在为人工智能计算奠定基础,这是一个可以匹配人工智能时代公司雄心壮志的数据平台。而今,VAST Data连续第二年被认定为2023年Gartner分布式文件系统和对象存储魔力象限™的挑战者。
不过,这里再说一下核心能力。Vast Data核心能力源自DASE分布式创新架构。
在20年前,谷歌推出无共享系统(shared-nothing)的想法带来了存储领域的革命,分布式存储从而走向了历史舞台。20年后,VAST构建了DASE系统,旨在打破分布式系统的传统扩展限制。
DASE架构将计算逻辑与系统状态解耦,并引入了新的共享和事务数据结构,这些设计结合在一起为下一代人工智能注入计算奠定了基础。
DASE将容量与性能、数据与丰富的元数据、边缘与云、简单与规模相结合。以前相互排斥的数据和系统概念现在“未来架构”的平台上和谐共存。
然而,深度学习和数据存储平台之间的鸿沟现在清晰而存在。为什么今天的数据存储平台不能满足现代深度学习的需求?
从根本上说,这些系统并非旨在存储和处理AI应用的丰富数据类型。今天流行的数据存储平台是为现代化业务发展而设计,而不是为人工智能而设计。事实上,如果深度学习从未存在,今天数据存储平台的采用将保持不变,因为这些系统主要侧重于块存储数据。虽然这些系统已经过改造,以解决机器学习和深度学习用例的某些需求,但差距仍然存在。
与基于批处理的计算架构不同,VAST架构利用实时写入缓存区,并在流入系统时实时捕获和操作数据。该缓存区可以拦截小型随机写入操作或大规模并行写入操作到持久内存空间,小型随机写入操作如事件流或数据库条目,大规模并行写入操作如应用程序检查点文件创建。
借助该内存空间可以立即与主存储如基于闪存的相对更低成本超大规模存档存储中的其他系统语料库进行检索和相关分析。因此,Vast Data平台专注于深度学习,致力于从非结构化数据中进行存储并支撑大模型数据检索与分析。
因此,说来说去,Vast Data为深度学习以及大模型训练带来了更友好的数据存储平台支撑,自然更容易被新的应用所采纳,被资本所看好。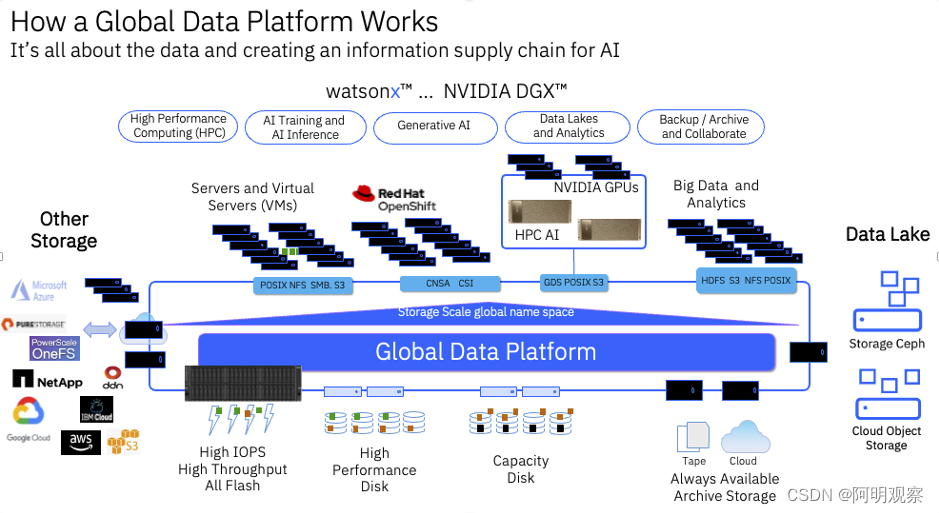
其实,在针对AI领域蓬勃发展的背后,对AI相关存储支持的专注也有大厂的参与,比如老将IBM也将IBM Storage Scale、IBM Storage Scale System、IBM Cloud Object Storage和IBM Storage Ceph多个软件整合在一起,建构了IBM的全球数据平台Global Data Platform,看着这名字就觉得大气,不愧是久经沙场的老手。
因此,在面向AI发展的存储基础设施创新之路上,Vast Data的对手还有不少的,回头有时间,阿明再和大家梳理梳理。
新老玩家都在努力,Vast Data可不要太傲娇哦。
另外,阿明观察认为,Vast Data融资超过20亿元都一分钱不花,除了天使轮与A轮没办法必须花钱,后续业务发展迅猛上来,现金流动起来后,也就自我满足了。
然而我们国内的存储初创为什么融资难,融资额也显得捉襟见肘呢?对比一下国内存储市场与美国存储市场,或许就能找到答案。Vast Data从诞生开始就生在了一个良好的存储生态之中,起点高自然看得远,也容易获得顶级用户的合作。
假如Vast Data诞生在国内将会如何?首先资本市场少有熟悉存储行业又熟悉AI行业的专业机构或人员,很难寻求到融资“意中人”,这是一难。
即便可以融资成功几轮,但参照目前国内融资成功过的相关存储厂商,名字这里我就不提了免得大家误会,就以ABCD字母代替了。比如A公司、X公司、S公司他们的融资总额不会太高,此外参与跟投或主要投资的机构其实对行业技术的了解程度还是有差距。大家可以看看Vast Data的几轮投资者和跟投的机构就明白了。因为行业专业性的误差,会影响投资规模大小,这是二难。
好!即便融资规模上来了,产品与解决方案也走向正规了,然而寻求典型有实力有发展的创新用户却不容易,国内采购者更多的看存储厂商资历与性价比,更直白一点就是价格。
初创企业再牛也很难在价格上与大厂直接PK,即使让步很大获得了用户订单,但后续带来的服务成本会拖累公司技术团队,加上项目订单利润稀薄或者无利润或负利润。
在这样情况下,中标项目订单越多看似初创企业营收规模上来了,但实际上埋下了“雷”。因为单项目的利润存在问题从而很难后期为公司带来健康的现金流,做一单亏一单还要免费补贴技术服务,目的就是做大营收规模,吸收用户成功案例。
由此反而为后续融资带来麻烦,即便想法走IPO流程,但营收规模即使够了利润规模却上不去,依然是白搭。这就是国内存储初创企业为什么用户案例一堆一堆,然而一走IPO流程就难上加难的原因,融资超过E轮E+轮也难以走上IPO正常流程。
像走向这样的状态,公司惟有寻求新的融资对象,靠融资支撑后续规模化发展,依靠时间堆积,用户项目堆积来寻求可能存在的发展分水岭,这简直和彩票站买几注差不多。用户案例越多,营收规模越大,越难以健康循环发展,这是三难。
国内存储初创企业真正的独立创新,找到完全不一样的路子几乎和登天一样难。大家可以细数一下到目前为止成立的国内存储初创企业,看似创新突破,还获得了N多项技术专利,然而直接被替代的风险非常高,技术门槛与生态门槛几乎就是无。
最关键还在营销推广上,虽说解决方案与大厂有所差异化,但依然如大厂一样走渠道,找总代,要不自己建直销团队打行业领域与存储大厂硬碰硬。如果你是行业内人士,或许你应该知道为什么一家成立没几年的存储厂商可以在某个项目订单上打败某花厂,其中的原因我就不明说了,试问一下打败大厂的原因真的是技术颠覆、技术创新么?营销推广创新难以突破,这是四难。
四难叠加,也就难住了一大批国内存储初创企业,要么选择被某大厂并购或收编,要不就只能熬完手头融资的银子不得不默默无闻,真正可以走向资本与技术相互趋动的健康发展道路实在难找。
因此,看看Vast Data现在的成功,可以与存储大厂直接PK,直接搞定全球知名的连存储大厂都艳羡的客户,成功之道也是有着良好的发展沃土。
数据存储超越还是追赶,我们得正视一下事实,实事求是,再出发,也都不算晚。切忌好高骛远,一出来就要弯道超车,得小心翻车的潜在隐患才是。
- END-
你
怎
么
看
?
欢迎文末评论补充!
【全球存储观察|全球云观察 |阿明观察 |科技明说】专注科技公司分析,用数据说话,带你看懂科技。本文和作者回复仅代表个人观点,不构成任何投资建议。














 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









