







这里的pipeline指的是从dataset类中加载数据时,对数据做的一系列流水线操作。
调用顺序
首先来分析一下涉及到的一系列函数的调用顺序。
CustomDataset类是mmdetection中所有dataset类的基类,继承了pytorch中的Dataset类。继承Dataset类时,我们需要重写__getitem__函数,用于从磁盘中加载数据。
CustomDataset类中的__getitem__函数根据是否为test_mode,来决定调用prepare_test_img()还是prepare_train_img(),这两个函数分别用来准备测试数据和训练数据,关于dataset部分会单独讲解,这里就不过多介绍了。
在prepare_train_img()函数中,我们注意返回值语句。
return self.pipeline(results)
从这里开始,就正式进入了pipeline的流程。
pipeline中的各个操作需要在dataset的配置文件中进行定义。
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
dataset=dict(
type='VOCDataset',
pipeline=train_pipeline))
mmdetection中自己实现了一个Compose类,用于组合pipeline,Compose类的本质也是一个transform,在其__call__函数中做的是使用循依次调用pipeline中的各个操作函数对数据进行处理。
Compose将会按照定义的顺序调用pipeline。
results
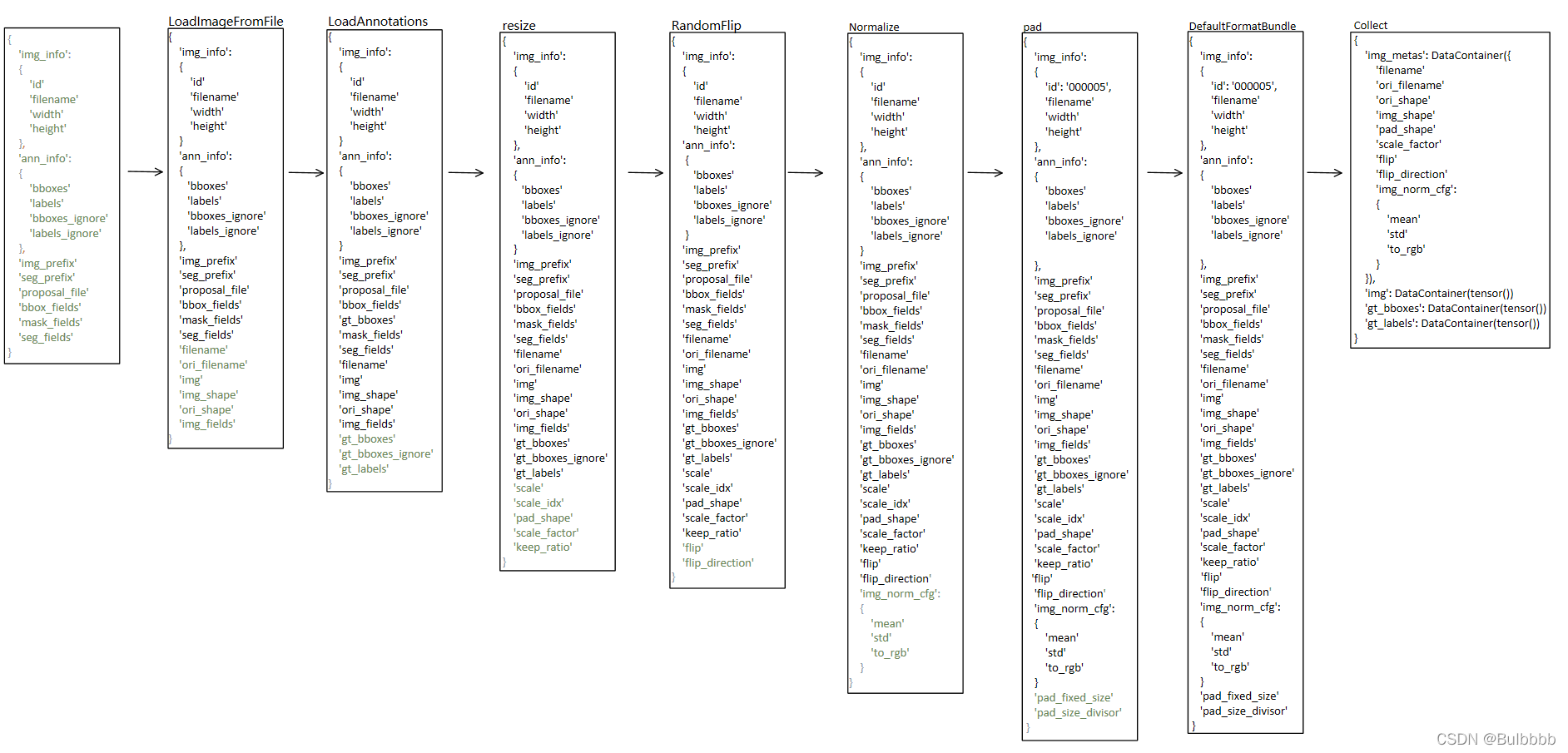
下面是result在经过pipeline时字段的变化情况。















 2457
2457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









