







1. GRU 简介
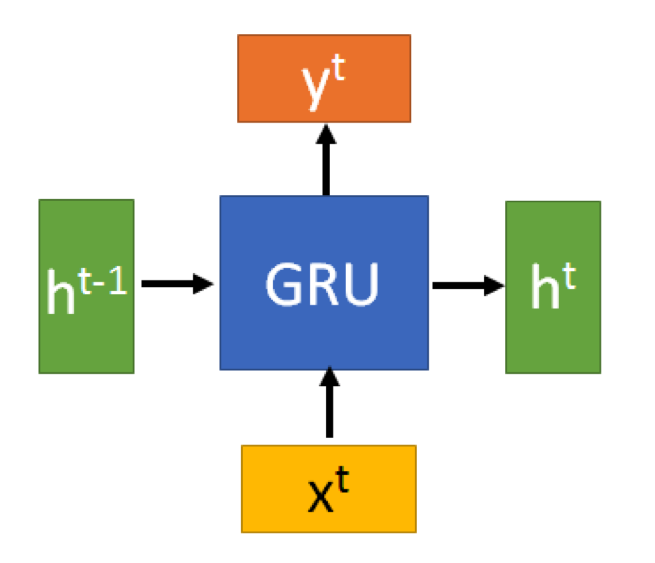
门控循环单元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。GRU 是循环神经网络的一种,和 LSTM 一样,是为了解决长期依赖问题。GRU 总体结构与 RNN 相近,如下图
但 GRU 的思想却与 LSTM 更加相似,反映在其内部结构上。如下图所示
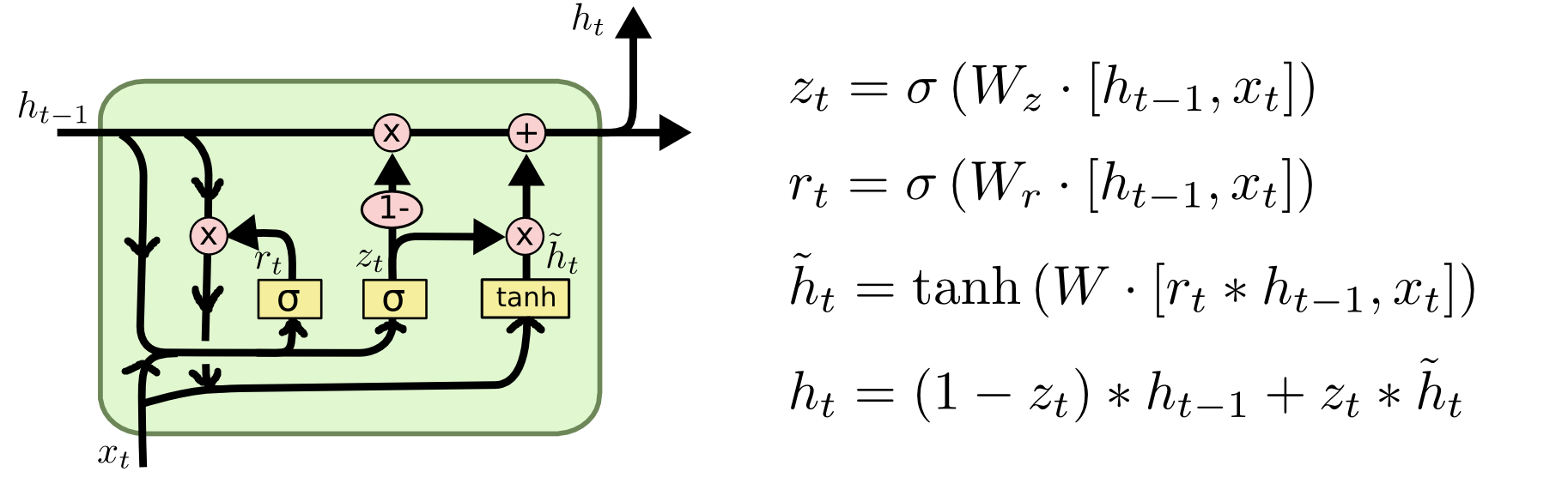
LSTM 使用三个门 (遗忘门、输入门和输出门) 来控制信息传递,GRU 将其缩减为两个 (重置门和更新门)。GRU 去除了单元状态,转而使用隐藏状态来传输信息,因此其参数减少,效率更高。虽然 GRU 对 LSTM 做了很多简化,但其依旧保持着与 LSTM 相近的效果。
2. GRU 详解
要想掌握 GRU,最好先理解 LSTM。关于 LSTM 的讲解,推荐本人另一篇博客《LSTM 浅析》。GRU 有两个门,重置门决定如何把新的输入与之前的记忆结合,更新门决定多少先前的记忆起作用。重置门和更新门的结构如下图
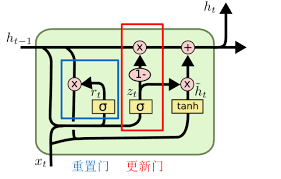
2.1 重置门
GRU 中的隐藏状态
h
t
h_t
ht 与 LSTM 中不同,可视为 LSTM 中单元状态和隐藏状态的混合,记录着历史信息。重置门为上图蓝框部分。重置门计算参数
r
t
∈
(
0
,
1
)
r_t \in (0, 1)
rt∈(0,1),将
r
t
r_t
rt 作为比例因子,控制着
h
t
−
1
h_{t-1}
ht−1 中将有多少信息被保留。重置门部分主要完成两项工作,一是参数
r
t
r_t
rt 的计算
r
t
=
σ
(
W
r
⋅
[
h
t
−
1
,
x
t
]
)
r_t = \sigma(W_r \cdot [h_{t-1}, x_t])
rt=σ(Wr⋅[ht−1,xt])
二是将
r
t
r_t
rt 与
h
t
−
1
h_{t-1}
ht−1 相乘,得到候选隐藏状态
h
~
t
\tilde{h}_t
h~t
h
~
t
=
σ
(
W
o
⋅
[
r
t
⊙
h
t
−
1
,
x
t
]
+
b
o
)
\tilde{h}_t = \sigma(W_o \cdot [r_t \odot h_{t-1}, x_t] +b_o)
h~t=σ(Wo⋅[rt⊙ht−1,xt]+bo)
h
~
t
\tilde{h}_t
h~t 包含了历史信息和当前时刻的新输入。
重置门的值越小,流入信息越少/先前信息遗忘得越多。重置门有助于捕捉时间序列里的短期依赖关系。
2.2 更新门
更新门的作用类似于 LSTM 中的遗忘门和输入门,决定着
h
t
h_t
ht 将从
h
t
−
1
h_{t-1}
ht−1 中保留多少信息 (不经过非线性变换), 以及需要从
h
~
t
\tilde{h}_t
h~t 中接受多少新信息。更新门为上图红框部分。在 LSTM 中,遗忘门和输入门是互补关系,具有一定的冗余性。GRU 直接使用一个门
z
t
z_t
zt 来保持输入和遗忘间的平衡。更新门部分主要完成两项工作,一是参数
z
t
z_t
zt 的计算
z
t
=
σ
(
W
z
⋅
[
h
t
−
1
,
x
t
]
)
z_t = \sigma(W_z \cdot [h_{t-1}, x_t])
zt=σ(Wz⋅[ht−1,xt])
二是隐藏状态
h
t
h_t
ht 的计算
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
^
t
h_t = (1-z_t) \odot h_{t-1} + z_t \odot \hat{h}_t
ht=(1−zt)⊙ht−1+zt⊙h^t
z
t
z_t
zt 控制着
h
t
−
1
h_{t-1}
ht−1 和
x
t
x_t
xt 有多大比例流入
h
t
h_t
ht 中,更新门的值越大,流入信息越多。更新门有助于捕捉时间序列里的长期依赖关系。
3. GRU 的 PyTorch 实现
To be continue…
【参考】
- LSTM;


















 3178
3178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









