









论文:CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
代码:https://github.com/FreedomIntelligence/Chain-of-Diagnosis
提出背景
如何利用大模型来提高诊断的准确性和效率。
然而,这些模型在实际应用中遇到了可解释性的重大挑战,包括决策的随意性和缺乏透明度。
为了解决这些问题,提出了一个名为“诊断链”(CoD)的新方法,旨在通过一系列明确的步骤提高LLMs的透明度和可解释性。

- 主诉:患者描述他们的症状,如流鼻涕和咳嗽。
- 症状核实:系统询问患者是否有其他症状,如喉咙痛。
- 疾病预测:基于患者的回答和已知的症状(显性和隐性症状),系统建议可能的疾病,如鼻炎。
本文的贡献如下:
- 我们引入了诊断链(CoD)诊断方法,旨在增强LLMs在疾病诊断中的可解释性;
- 我们提出了一种使用疾病百科全书数据合成病例的方法。这使得以低成本创建各种疾病的CoD训练数据成为可能,同时避免了隐私和伦理问题;
- 使用CoD,我们建立了DiagnosisGPT,可以支持9,604种疾病的自动诊断。实验表明,DiagnosisGPT在多种诊断数据集中超越了其他LLMs;
- 我们介绍了DxBench,这是一个诊断基准,包括1,148个真实病例,涵盖461种疾病,手工验证并源自公开的医生-患者对话。
解法拆解
目的:
CoD(诊断链)的目的是通过提供一个模拟医生诊断思维的透明诊断链来增强大型语言模型在医学诊断中的可解释性。
问题:
在使用大型语言模型(LLMs)进行医学诊断时,一个主要问题是其决策过程的“黑箱”性质,使得医生和患者难以理解和信任模型的诊断结果。
解法:
CoD通过将复杂的诊断决策转化为一个分步骤的透明和可解释的诊断链来解决这一问题。

这幅图展示了一个使用CoD系统进行医学诊断的实例,流程包括以下步骤:
-
症状抽象:
- 分析患者描述的症状(例如牙痛和对冷或酸性食物的敏感性)。
-
候选疾病回忆:
- 根据提供的信息,系统识别出可能的诊断,例如牙齿腐烂(Tooth Decay)、牙髓炎(Pulpitis)、牙本质过敏(Dentin Hypersensitivity)。
-
诊断推理:
- 系统通过逻辑推理确定症状与潜在疾病之间的关联。
-
置信度评估:
- 为每种可能的疾病分配一个置信度(例如,Tooth Decay: 0.4)。
-
决策制定:
- 基于置信度阈值进行决策,如果最高置信度超过设定阈值,则提供具体的诊断,否则询问更多症状。
CoD 分为五步:
-
症状抽象(因为需要明确患者问题的关键症状)
- 通过函数 f1 从患者的问题中总结出关键症状 S,使模型能专注于这些症状并提供对患者查询的清晰理解。
- 之所以使用症状抽象,是因为精确识别和总结症状是诊断过程中的首要步骤,有助于准确引导后续的疾病识别和分析。
-
疾病回忆与知识整合(因为要从潜在的大量疾病中快速锁定几种可能性)
- 通过函数 f2 从已知的疾病数据库中检索与症状 S 最相关的前 K 种疾病 D′。
- 使用密集检索训练方法优化此检索器,确保可以高效精确地从大量疾病中筛选出与当前症状最相关的少数疾病。
- 之所以进行疾病回忆与知识整合,是因为仅通过症状直接匹配疾病可能会忽略深层次的病理联系,整合知识有助于提高诊断的准确性和深度。
-
诊断推理(因为需要分析疾病与症状之间的对应关系)
- 通过函数 f3 对每一种可能的疾病 D′ 进行详细推理,生成诊断推理过程 T。
- 之所以采用诊断推理,是因为详细分析每一种可能疾病与症状的对应关系可以提高诊断的精确度,并帮助医生理解决策背后的逻辑。
-
置信度评估(因为需要定量评估每种疾病的可能性)
- 在生成推理过程 T 后,通过函数 f4 生成关于各种疾病的置信度分布 C,这个分布显示了模型倾向于诊断每种疾病的置信程度。
- 之所以进行置信度评估,是因为通过量化的方式可以更明确地显示模型对各种疾病诊断的确信程度,便于医生做出最终判断。
-
决策制定(因为最终需要决定是否进行诊断或继续询问)
- 根据置信度分布和预设的置信度阈值 τ,CoD 决定是直接进行疾病诊断还是继续进行症状询问。
- 之所以设置决策制定步骤,是因为在实际医疗环境中,决策需要在确保准确性和考虑患者耐心(询问次数)之间取得平衡。
这些子解法构成了一个决策树形的逻辑链,从症状抽象开始,逐步深入到疾病回忆与知识整合,再到诊断推理和置信度评估,最后根据置信度进行决策制定。
假设一个患者来到诊所,抱怨头痛和疲劳。
以下是如何使用诊断链(CoD)模型进行多轮问诊的示例:
第一轮问诊:
-
症状抽象:
- 患者输入其主要症状:头痛和疲劳。
- CoD通过函数 f1 分析这些症状,并总结为关键症状 S = {“头痛”, “疲劳”}。
-
疾病回忆与知识整合:
- CoD 使用函数 f2 查询与头痛和疲劳相关的疾病,如颅内压增高、贫血、甲状腺功能低下等。
-
诊断推理:
- CoD 分析每种可能的疾病与患者症状的匹配程度,并生成初步的诊断推理过程 T。
-
置信度评估:
- CoD 通过函数 f4 评估各疾病的置信度,发现没有任何一种疾病的置信度超过预设阈值 τ。
-
决策制定:
- 由于没有达到置信阈值,CoD 决定进行更深入的问诊。
第二轮问诊:
-
进一步询问症状:
- CoD 提出具体问题,例如:“您是否有视力模糊或双视?” 或 “您最近是否有体重变化?”
-
更新症状信息:
- 患者回答有轻微的视力模糊。
- 更新的症状 S = {“头痛”, “疲劳”, “视力模糊”}。
-
再次疾病回忆与知识整合:
- 以新增的症状重新运行函数 f2,筛选相关疾病。
-
诊断推理更新:
- CoD 重新评估疾病与更新症状的对应关系。
-
重新评估置信度:
- 更新置信度评估,此时可能发现某些疾病的置信度已增加。
-
新的决策:
- 如果某个疾病的置信度超过了阈值 τ,CoD 可能建议进行特定的诊断测试或直接给出诊断。
- 如果置信度仍低于阈值,可能推荐进一步的医学检查或转诊至专家。
通过这种方式,CoD 模型可以逐步收集更多信息,直到能够做出准确的诊断或确定需要进一步的医疗行动。
这个过程模拟了医生在面对诊断不确定性时的实际操作,通过增加问诊轮次来逐步缩小疾病的可能范围,提高诊断的准确性。
多轮精准问题
我最好奇的是,CoD 怎么设计的多轮精准问诊。
多轮诊断任务涉及使用明确的(自述的)和隐含的(询问的)症状来预测疾病。
医生要么进一步询问,要么做出诊断,目标是在最少的询问中达到高准确率。
CoD(Chain of Diagnosis)利用信息论原理进行多轮精准问诊,全流程包括:
- 首先通过症状抽象收集患者的显性症状并提取关键信息;
- 接着在疾病回忆与知识整合阶段,利用LLM从数据库中筛选与症状匹配的疾病;
- 在诊断推理阶段,分析各疾病与症状的对应关系,形成诊断思路;
- 置信度评估则生成各疾病的可能性分布;
- 决策制定阶段根据置信度确定是否需要更多信息或可直接诊断;
- 最后,症状询问与熵减少环节通过提问降低诊断的不确定性,优化诊断决策。
这个过程通过对症状的询问优化诊断决策,具体如下:
-
使用检索器(retriever)来找出可能的疾病:
- 检索器是一个预训练的模型,能根据输入的症状找出可能相关的疾病。
- 例如,如果输入症状是"发烧、咳嗽、疲劳",检索器可能会返回"感冒、流感、新冠肺炎"等可能的疾病。
-
使用大语言模型生成诊断结果和置信度分布:
- 大语言模型(如GPT)接收检索器的输出和患者的症状描述,生成诊断结果。
- 同时,模型会给出每种可能疾病的置信度。
- 例如,模型可能输出:{“流感”: 0.7, “感冒”: 0.2, “新冠肺炎”: 0.1}
-
通过设定置信度阈值(confidence_threshold)来决定是否做出诊断:
- 如果最高置信度超过预设阈值(如0.5),模型会给出诊断。
- 否则,模型会要求更多信息。
-
考虑症状数量(min_sym_num):
- 如果症状数量不足,即使置信度高,也可能不给出诊断。
举个例子:
假设一个患者描述:“我最近感到发烧和咳嗽。”
-
检索器分析症状,返回可能的疾病:感冒、流感、新冠肺炎。
-
大语言模型生成诊断和置信度:
{“流感”: 0.4, “感冒”: 0.3, “新冠肺炎”: 0.3} -
假设置信度阈值是0.5,min_sym_num是3:
- 最高置信度(0.4)低于阈值(0.5)
- 症状数量(2)少于最小要求(3)
-
结果:模型不会给出确定诊断,而是会问更多问题,如:
“您还有其他症状吗?比如疲劳或者肌肉酸痛?”
这个过程允许模型在信息不足时保持谨慎,同时通过询问更多问题来收集必要的信息,以做出更准确的诊断。
熵减少过程
在信息理论中,熵是一个衡量系统不确定性的度量。
在医疗诊断的背景下,熵可以被用来描述医生对患者疾病状态的不确定性。
一开始,医生可能面对多种可能的诊断,每种都有不同的可能性。
CoD通过结构化的询问过程系统地减少这种不确定性。
症状询问的熵减少
-
显性症状与隐性症状的辨识:
-
显性症状(explicit symptoms)是患者直接报告的症状。
-
隐性症状(implicit symptoms)则是需要通过医生的询问才能显现的症状。
CoD框架首先分析患者的显性症状,并根据这些信息推断可能的疾病。然后,通过询问隐性症状来进一步确认或排除某些诊断。
-
-
信息增益与症状选择:
- 每次询问都应该旨在最大化信息增益,即选择那些最有可能显著减少诊断不确定性的症状进行询问。
- CoD通过计算每个症状询问后熵的预期减少量来优化询问的顺序。
- 理想的症状询问是那些在回答后能最大限度减少剩余疾病可能性熵的症状。
-
熵的计算与更新:
- 在CoD中,每个疾病的置信度可以视为疾病概率分布的一部分,熵可以通过这个分布来计算。
- 当通过询问显性或隐性症状获得新信息时,置信度分布会更新,熵据此减少,反映出诊断决策的不确定性降低。
-
诊断的动态更新:
- 在CoD框架中,随着每一步的症状询问,诊断可能会根据新信息进行更新,这种动态更新帮助医生逐步锁定最可能的疾病。
CoD作为熵减少过程的应用,通过有序且目标明确的症状询问来优化决策过程,使得医生可以在保持高效的同时,逐步减少对疾病状态的不确定性,从而达到快速且准确诊断的目的。
这种方法不仅提高了诊断的精确度,也为医生提供了一个清晰的决策支持机制。
逻辑链
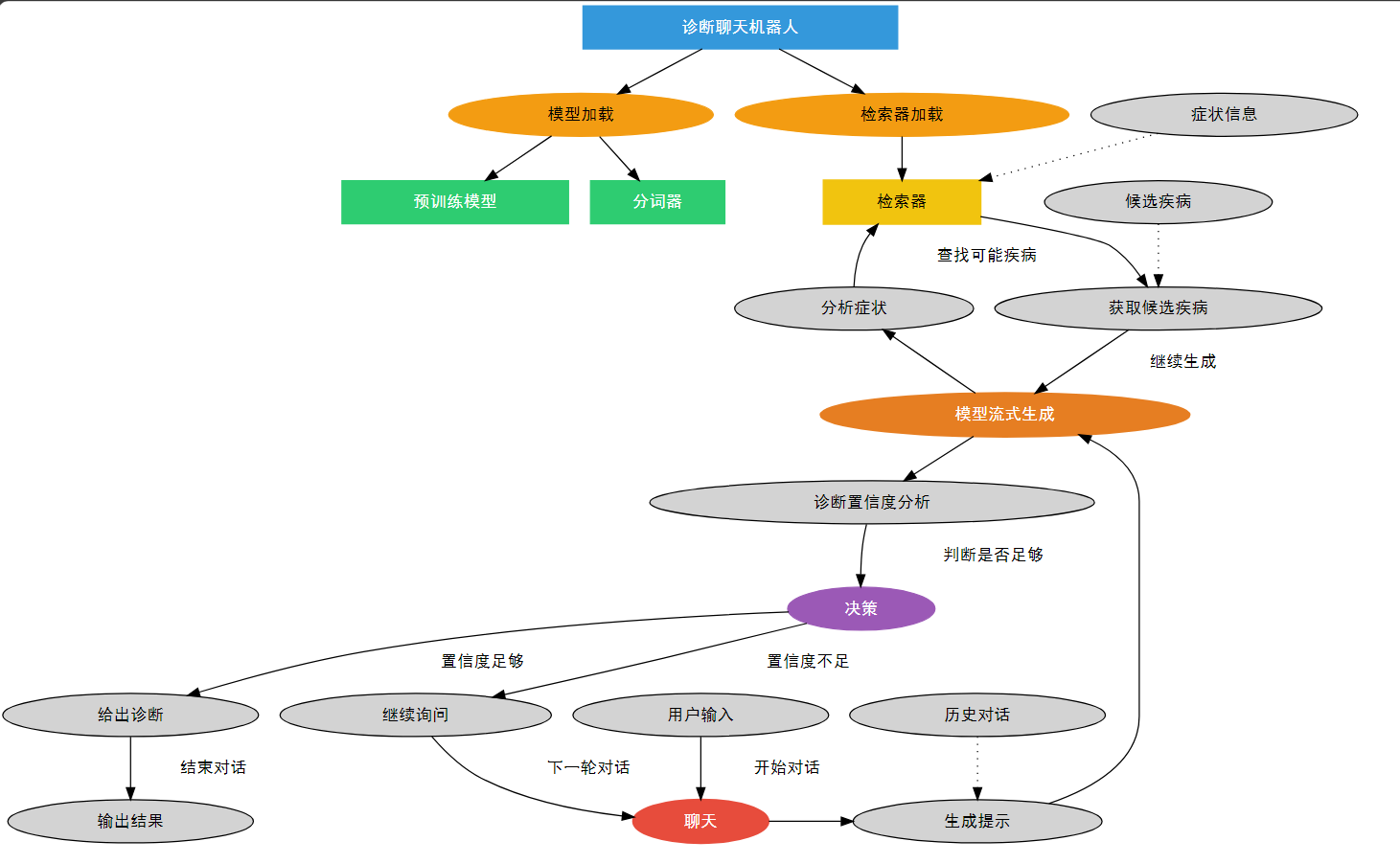
当然,我很乐意为您提供一个通俗易懂的全流程拆解介绍。让我们从头开始,逐步解释这个诊断聊天机器人的工作流程:
-
初始化阶段:
- 诊断聊天机器人启动时,首先进行两项重要的加载工作:
a) 模型加载:装载预训练模型和分词器。这就像给机器人安装了一个"大脑"和"语言处理器"。
b) 检索器加载:准备一个能快速查找信息的工具,类似于医生的参考手册。
- 诊断聊天机器人启动时,首先进行两项重要的加载工作:
-
对话开始:
- 用户输入症状或问题,开始与聊天机器人对话。
- 聊天功能被激活,准备处理用户的输入。
-
生成对话:
- 聊天机器人使用"生成提示"功能,将用户输入转化为机器可以理解的格式。
- 然后,"模型流式生成"开始工作,这就像机器人开始思考并组织语言。
-
症状分析和疾病检索:
- 机器人分析用户描述的症状。
- 使用检索器,根据症状信息查找可能的疾病。这就像医生根据症状查阅医学手册。
- 获取候选疾病列表,为下一步诊断做准备。
-
持续对话和信息收集:
- 机器人可能会继续生成回复,询问更多细节或提供初步信息。
- 这个过程可能会重复多次,就像医生反复询问病人以获取更完整的信息。
-
诊断分析:
- 收集足够信息后,机器人进行诊断置信度分析。
- 这相当于评估自己对诊断的把握程度。
-
决策阶段:
- 基于置信度分析结果,机器人做出决策:
a) 如果置信度足够,给出诊断。
b) 如果置信度不足,决定继续询问更多信息。
- 基于置信度分析结果,机器人做出决策:
-
结果输出:
- 如果给出诊断,机器人会提供详细的诊断结果。
- 如果需要继续询问,会回到聊天阶段,开始新一轮的对话。
-
循环优化:
- 整个过程中,历史对话会被用来改进后续的对话生成,使交互更加连贯和个性化。
这个流程就像一个非常细心的数字医生,不断收集信息,分析症状,查阅资料,直到有足够的信心给出诊断或决定需要更多信息。
整个过程是迭代的,确保了诊断的准确性和全面性。
医学诊断的LLM增强可解释性的研究
├── 1 引言【描述背景和问题】
│ ├── 医学诊断的重要性和复杂性【背景介绍】
│ ├── LLMs在自动化诊断中的应用【技术应用】
│ └── LLMs应用的挑战【问题描述】
│ ├── 解释性不足【具体挑战】
│ └── 诊断的随意性【具体挑战】
├── 2 诊断问题定义【详细阐述诊断过程】
│ ├── 诊断任务的定义【任务描述】
│ └── 诊断的挑战【面临的问题】
│ ├── 症状询问的时机和方式【诊断精准性】
│ └── 效率与准确性的权衡【核心难点】
├── 3 方法论:诊断链(CoD)【解决方案】
│ ├── CoD的目的和构造【方法概述】
│ ├── CoD的哲学和属性【理论基础】
│ │ ├── 透明性的定义和重要性【属性1和2】
│ │ └── 事后解释的作用【属性3】
│ ├── 诊断链的构造【具体实施步骤】
│ │ ├── 症状抽象【步骤1】
│ │ │ ├─ 输入【病人描述的症状和病史】
│ │ │ │ └─ 数据源【病人自述、病历记录】
│ │ │ ├─ 处理【文本分析和关键信息提取】
│ │ │ │ ├─ 方法【自然语言处理技术】
│ │ │ │ └─ 工具【LLM, 特定算法如实体识别】
│ │ │ └─ 输出【结构化的症状信息】
│ │ │ └─ 用途【为疾病回忆与知识整合提供输入】
│ │ ├── 疾病回忆与知识整合【步骤2】
│ │ │ ├─ 输入【结构化的症状信息】
│ │ │ ├─ 过程【基于症状检索相关疾病数据库】
│ │ │ │ ├─ 数据库查询【使用匹配算法】
│ │ │ │ └─ 算法【文本相似度度量、机器学习模型】
│ │ │ └─ 输出【候选疾病列表】
│ │ │ └─ 用途【为诊断推理提供必要的输入数据】
│ │ ├── 诊断推理【步骤3】
│ │ │ ├─ 输入【候选疾病列表】
│ │ │ ├─ 过程【逐一分析每个疾病与症状的匹配程度】
│ │ │ │ ├─ 方法【详细对比症状与疾病描述】
│ │ │ │ └─ 工具【逻辑推理、专家系统或机器学习模型】
│ │ │ └─ 输出【每个疾病的推理结果】
│ │ │ └─ 用途【为置信度评估提供基础】
│ │ ├── 置信度评估【步骤4】
│ │ │ ├─ 输入【每个疾病的推理结果】
│ │ │ ├─ 过程【基于推理结果计算每种疾病的概率】
│ │ │ │ ├─ 计算模型【概率统计模型、贝叶斯更新】
│ │ │ │ └─ 考量因素【症状严重性、流行病学数据】
│ │ │ └─ 输出【疾病的置信度分布】
│ │ │ └─ 用途【决定是否进一步信息收集或进行诊断决策】
│ │ └── 决策制定【步骤5】
│ │ ├─ 输入【疾病的置信度分布】
│ │ ├─ 判断【根据置信度分布决定是否有足够信息做出诊断】
│ │ │ ├─ 是【进行诊断】
│ │ │ │ └─ 操作【根据高置信度疾病诊断】
│ │ │ └─ 否【要求更多信息或测试】
│ │ │ └─ 操作【指定需要的测试或症状查询】
│ │ └─ 输出【最终诊断或进一步诊断步骤】
│ │ └─ 用途【影响患者治疗和管理】
│ └── CoD作为熵减少过程【决策支持机制】
│ └── 症状询问的熵减少【决策优化】
│ ├── 计算症状信息增益
│ │ ├── 症状出现的概率【统计症状在已知数据中的出现频率】
│ │ └── 症状与疾病的相关性【相关系数计算-量化症状和特定疾病间的关联强度】
│ └── 更新条件熵
│ ├── 重新计算症状后的疾病概率【使用Bayes规则更新疾病的后验概率】
│ └── 比较前后熵值【信息熵公式计算-对比更新前后的信息熵,衡量熵的减少量】
└── 4 合成病例的生成【数据支持结构】
├── 构建疾病数据库【阶段1】
│ ├── 收集疾病数据【包括症状、治疗、流行病学信息等】
│ └── 数据整合【标准化和格式化疾病信息】
└── 制定合成病例【阶段2】
├── 模拟病例【基于真实病例数据或疾病特征合成】
└── 校验合成效果【确保病例数据质量和可用性】
CoD 中的信息论概念
熵
熵在信息论中是衡量信息量或系统不确定性的一个概念。
在医疗诊断中,熵用来量化医生关于患者病情的不确定性。
高熵意味着高不确定性,即诊断时可选的疾病种类多且不清楚具体是哪一种;低熵则意味着对患者的病情有较清晰的认识。
信息增益
信息增益是描述在已知某一信息后,系统不确定性减少的量。
在CoD中,通过选择询问那些最可能显著减少熵的症状(即最有信息量的症状),来优化诊断过程。
例如,在构建决策树时,选择哪个特征作为节点分裂的依据,就是通过计算每个特征的信息增益来决定的。
特征的信息增益越大,说明这个特征带来的信息量越大,使用这个特征进行分裂所得到的子节点的纯度提升越明显,即分类的不确定性减少得越多。
条件熵
条件熵是在已知一个或多个变量的情况下,另一个变量的不确定性。
在CoD中,例如,医生了解到某些症状后,对疾病的不确定性(熵)通常会降低。
这是通过条件熵来计算的,即在已知某症状后,疾病分布的熵。
条件熵
H ( X ∣ Y ) H(X|Y) H(X∣Y)表示在已知变量 Y Y Y的条件下,变量 X X X的不确定性。
如果医生了解到某些特定的症状信息 ( Y ),这些信息将帮助医生更好地预测患者的疾病状态(即 ( X ) 的不确定性降低了)。
如果 ( Y ) 与 ( X ) 完全无关,那么了解 ( Y ) 并不会减少对 ( X ) 的不确定性,此时条件熵与原始熵相等。
概率分布与熵的计算
在CoD框架中,每种疾病的置信度可以看作是概率分布,这个分布的熵可以用来衡量整体诊断过程中的不确定性。
通过逐步的信息获取(即询问症状),这个分布会被更新,熵相应减少。
信息增益
I G ( Y ) = H ( X ) − H ( X ∣ Y ) IG(Y) = H(X) - H(X|Y) IG(Y)=H(X)−H(X∣Y),表示得到信息 Y Y Y 后,关于 X X X 的不确定性的减少量(原始的熵减去条件熵)。
如果医生得到了某些独特的症状信息 ( Y ),这使得他对患者的疾病 ( X ) 的理解更加清晰,那么这条信息就具有高的信息增益,可能导致更精确的诊断结果。
CoD 提示词
指导大模型进行医学诊断
初始输入:
您是一位专业医师,任务是根据患者的症状信息来诊断患者。我将为您提供可能的疾病信息,您需要仔细考虑患者可能患有的候选疾病。
患者症状信息标记为<symptoms>,候选疾病标记为<candidate_diseases>。
<symptoms> {Known_symptoms} <symptoms>
<candidate_diseases> {candidate_diseases} <candidate_diseases>
如果您认为可以做出诊断,请从<candidate_diseases>中选择最可能的疾病(只选择一个)。
示例输出:
{"judge": true, "disease": "common cold"}
如果您认为症状信息不足,请询问患者更多的症状信息,注意您只能询问一个症状。
示例输出:
{"judge": false, "symptom": "Do you have a lack of appetite?"}
请以JSON格式输出。
患者回应后的输入:
患者的回应将被标记为<Patient>。
我给您的提示将被标记为<Hit>。
<Patient> {patient_response} <Patient>
<Hit>请根据患者的回应现在决定是否可以做出诊断。
如果您认为可以做出诊断,请从<candidate_diseases>中选择最可能的疾病(只选择一个)。
示例输出:
{"judge": true, "disease": "common cold"}
如果您认为症状信息不足,请询问患者更多的症状信息,注意您只能询问一个症状。
示例输出:
{"judge": false, "symptom": "Do you have a lack of appetite?"}
请以JSON格式输出。<Hit>
这个提示是对如何使用大型语言模型(LLM)进行病人诊断的详细说明。
它概述了医生如何根据患者提供的症状信息来确定是否可以做出诊断,以及如何选择可能的疾病或进一步询问症状的具体步骤。具体包括:
- 症状信息:标记为
<symptoms>,表示当前已知的患者症状。 - 候选疾病:标记为
<candidate_diseases>,代表可能的疾病列表。 - 诊断决策:
- 如果认为可以根据现有症状做出诊断,则从候选疾病中选择最可能的一种。例如:
{"judge": true, "disease": "common cold"}表示诊断为普通感冒。 - 如果现有症状信息不足,需要询问患者更多的症状信息,每次只能询问一个症状。例如:
{"judge": false, "symptom": "Do you have a lack of appetite?"}表示询问患者是否缺乏食欲。
- 如果认为可以根据现有症状做出诊断,则从候选疾病中选择最可能的一种。例如:
- 患者回应:标记为
<Patient>,代表患者对询问的回答。 - 操作指示:标记为
<Hit>,基于患者的回答,指导是否可以做出诊断或需要进一步获取症状信息。
这个过程确保了诊断活动的系统性和结构性,同时也强调了在不确定情况下如何继续获取信息以提高诊断的准确性。
如何利用大模型来生成特定疾病特征的合成患者案例
疾病:{disease name}
该疾病概述:{overview}
该疾病常见症状包括:{symptoms}
请根据上述描述完成以下任务:
1. 首先,生成受此病影响的人群的基本人口统计信息:性别和年龄。
2. 您需要构建关于此病的五个真实案例。在这五个案例中,两个应该只有一个主要症状,两个应该有两个主要症状,一个应该有三个以上的主要症状(主要症状是最显著的症状)。每个案例应包括2-4个隐性症状(通常是医生询问后可以引出的症状)。确保每个案例都是该疾病的典型例子。
输出为JSON格式,并且只输出JSON内容,不输出其他任何内容。示例输出为:
{"Basic Information": {"Gender": "Female", "Age": "Child"}, "Case
1": {"Main Symptoms": ["Symptom 1", "Symptom 2"], "Implicit Symptoms":
["Symptom 3", "Symptom 4", "Symptom 5"], "Case 2": "..."}
目的:
- 生成医学案例:利用GPT-4根据疾病数据库的信息,合成具体疾病的患者案例,用于医疗训练、研究或算法测试。
过程:
-
疾病数据库信息:
- 每个疾病条目包括疾病名称、概述、症状和治疗方法。
- 示例中使用“疾病名称”、“概述”和“症状”作为输入数据。
-
案例生成指导:
- 基本人口统计信息生成:首先生成受此病影响的人群的基本人口统计信息,如性别和年龄。
- 构造五个真实案例:
- 指定案例中的主要症状数量,其中两个案例只有一个主要症状,两个案例有两个主要症瞩,一个案例有三个以上的主要症状。
- 每个案例还需要包括2至4个隐性症状(即通常需要医生询问后才能显现的症状)。
- 确保每个案例都能典型地反映该疾病的特征。
-
输出格式:
- 所有生成的信息以JSON格式输出,确保输出仅包含JSON内容,不包含其他任何输出。
- 输出示例如:包含基本信息、主要症状及隐性症状的多个案例描述。
用途:
- 这种合成案例生成方法可以帮助在没有实际患者数据的情况下,进行医疗人工智能模型的训练和测试。
- 它也可以用于医学教育,提供学生模拟病例分析和诊断的机会。
这个提示词为使用语言模型来自动生成详细且符合实际病症特点的医学案例提供了一种结构化的方法,这对于提高医疗模型的实用性和准确性具有重要意义。
患者自述提示
系统提示:
我希望你扮演一个患者,并以患者的声音向医生描述你的病情。
请避免使用过于专业的术语。
医生的问题将用<Doctor>标记。
你的回应将用<Patient>标记。
我提供的提示将用<Hint>标记。
查询:
<Doctor> 你好,我是医生。有什么可以帮助您的? <Doctor>
<Hint> 你的症状是:{explicit_syms}
如果症状包括关于患者年龄和性别的信息,例如老年人,女性等,请告诉医生。
请以患者的声音回答,只输出患者的话,不要输出其他内容。 <Hint>
诊断推理提示
您是一位专业医师,任务是根据提供的症状信息诊断患者。您将获得一份候选疾病清单,您的角色是为患者提供详细的诊断分析和候选疾病的置信度分布。
您首先需要分析患者的状况,并思考患者可能患有哪些候选疾病。
然后,以JSON格式输出候选疾病的诊断置信度分布,请输出一个字典而不是列表。
输出示例为:
{"analysis":..., "distribution": {"动物皮肤病": 0.25, "热疹": 0.2, "皮炎": 0.55}}
患者的明确症状:{explicit_syms},
患者的隐性症状:{implicit_syms},
候选疾病:{candidate_diseases}
请首先分析患者的状况,然后输出这些疾病的概率分布。
重新思考诊断提示
您的诊断分析未通过审查,因为您对可能错误的疾病分配了过高的置信度。请重新考虑您的评估,并提供一个新的诊断分析以及置信度分布。确保输出格式保持完全相同。
输出示例为:
{"analysis":..., "distribution": {"动物皮肤病": 0.25, "热疹": 0.2, "皮炎": 0.55}}
医生诊断提示
系统提示:
请扮演医生的角色,询问患者的病情或诊断疾病。患者的回应将用<Patient>标记。
您的回应将用<Doctor>标记。我提供的提示将用<Hint>标记。
查询:
{Chat_history}
<Hint>医生的诊断将通过<diagnosis of disease>标记。这种被诊断疾病的治疗方法将通过<treatment method>标记。
<diagnosis of disease> {disease_name} <diagnosis of disease>
<treatment method> {treatment} <treatment method>
根据上述信息和历史对话记录,请诊断患者并提供详细建议。
以医生的语气回复,并且开头不要使用“医生”这个词。<Hint>
症状生成提示
您现在是一位专业医生,您需要根据以下信息推断下一个要询问患者的症状。
患者的明确症状:{explicit_syms}
患者的隐性症状:{implicit_syms}
患者目前可能患有的疾病:{predicted_disease}。
请推断下一个要询问患者的症状,只询问一个之前未曾询问过的症状。
输出格式应为json,例如:
{"symptom": "headache"}
医生询问提示
系统提示:
请扮演医生的角色,向患者询问他们的病情或诊断疾病。
患者的回答将用<Patient>标记。
您的回答将用<Doctor>标记。
我提供的提示将用<Hint>标记。
查询:
{Chat_history}
<Hint>请根据这些症状询问患者的状况:
{current_sym}
请以医生的语气回答,只提一个对话式的问题,确保患者能理解。开头不要用“医生”这个词。<Hint>
症状评估提示
您现在是一名专业医生。
请根据患者的信息判断患者是否有该症状。
已知患者的主要症状是 {explicit_syms},
隐性症状是 {implicit_syms}。
请确定患者是否有 {choose_sym}。
在患者现有的症状中搜索,注意同义词。如果找到,输出真;如果没有找到,输出假。
输出格式为json,例如:
{"headache": true}
患者回应提示
系统提示:
我希望你扮演一个患者,并以患者的声音向医生描述你的病情。请避免使用过于专业的术语。
医生的问题将用<Doctor>标记。你的回答将用<Patient>标记。我提供的提示将用<Hint>标记。
查询:
{Chat_history}
<Hint>请根据信息回答医生的问题,注意你{do_or_do_not}有这个症状:{choose_sym}
请以患者的语气回答,避免使用过于专业的术语。开头不要用“患者”这个词。<Hint>
提取结构化病例的提示
以下是一个患者病例的信息:
诊断疾病:disease
患者自述:self-report
患者与医生之间的对话:conversation
请从上述信息中提取一个结构化的病例,该病例是一个包含(显性症状(患者报告的症状)、隐性症状(医生询问的症状)、疾病(医生诊断的疾病))的元组。症状和疾病需要使用专业术语。输出模板是:
{"explicit_sympom": ["发热", ...], "implicit_sympom": ["咳嗽", ...],
"disease": "感冒"}

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









