







主要技术点包括:
- 集成学习模型:使用了随机森林、XGBoost、Adaboost、决策树等集成学习算法
- 可解释AI (XAI)技术:使用LIME、SHAP、Eli5、PDP、ALE等工具来解释模型决策
- 特征工程:采用多种特征选择方法,包括信息增益、方差阈值、前向选择和递归特征消除
- 数据预处理:处理缺失值,使用MCAR测试和多种插补技术
解决的主要问题:
5. 慢性肾病(CKD)的早期预测和诊断
6. 模型决策的可解释性问题,使医生能够理解并信任AI模型的预测结果
7. 识别对CKD预测最重要的生物医学指标
主要优势:
8. 高准确性:最佳模型(随机森林)达到99%的准确率
9. 强可解释性:通过多种XAI技术提供模型决策的详细解释
10. 临床验证:与肾病专家合作验证研究发现
11. 全面评估:使用多种评估指标(准确率、可解释性、忠实度等)进行模型评估
12. 实用性:可帮助医生进行早期诊断,制定个性化治疗方案
论文大纲
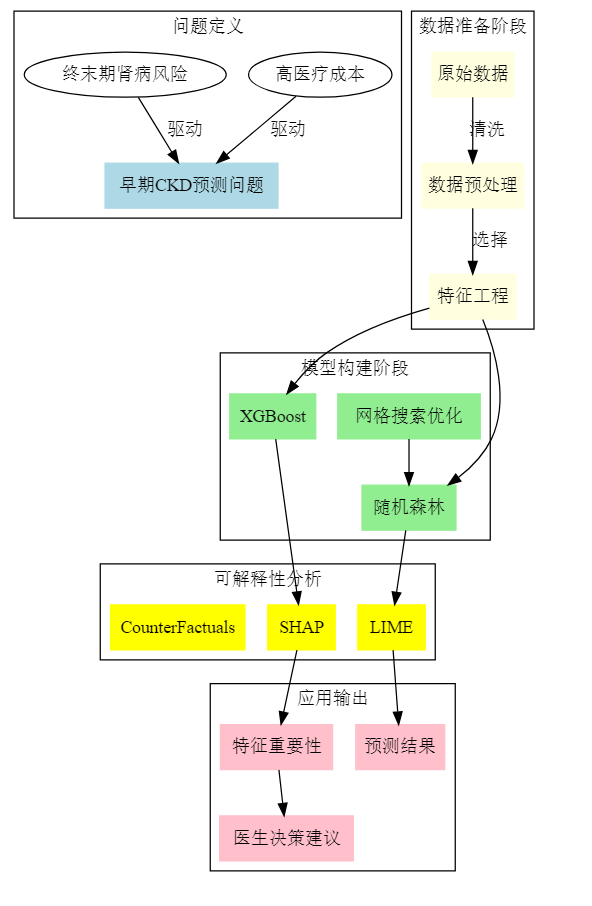
├── 1 研究背景【整体框架】
│ ├── 慢性肾病现状【问题描述】
│ │ ├── 无已知根本治愈方法【特征】
│ │ ├── 发病率高且影响广泛【现状】
│ │ └── 早期诊断困难【挑战】
│ │
│ ├── 研究目标【研究意图】
│ │ ├── 可视化主导特征【目标1】
│ │ ├── 展示特征得分【目标2】
│ │ └── 支持早期预测【目标3】
│ │
│ └── 技术路线【方法论】
│ ├── 集成学习模型【技术选择】
│ └── 可解释AI应用【技术选择】
│
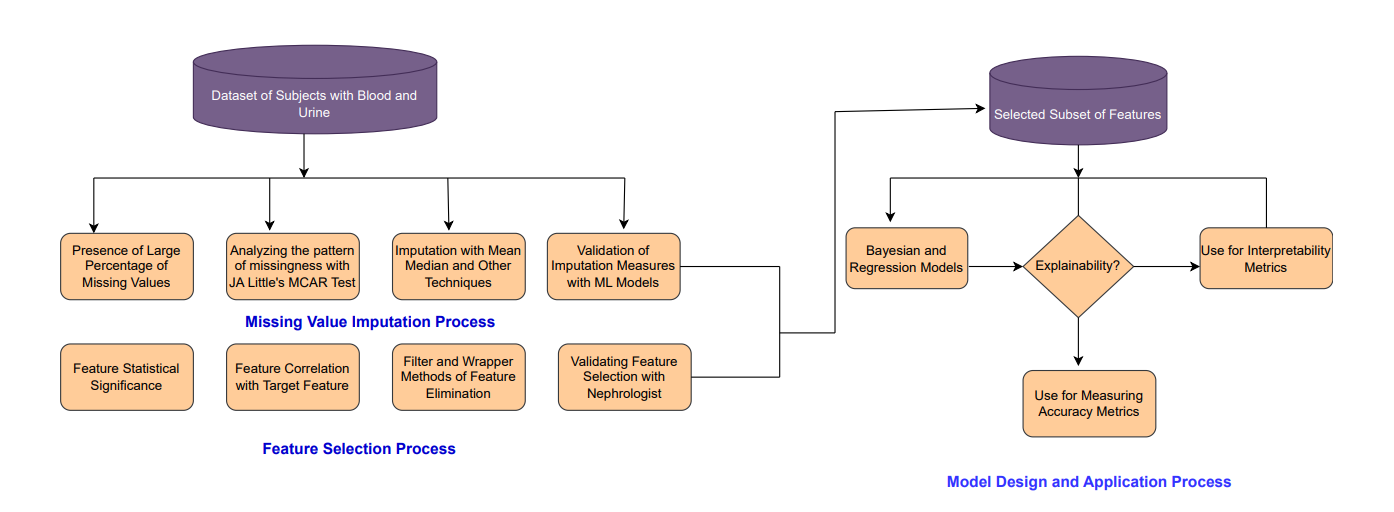
├── 2 数据预处理【方法详述】
│ ├── 缺失值处理【数据清洗】
│ │ ├── MCAR测试【验证方法】
│ │ └── 均值填充【处理方法】
│ │
│ └── 特征工程【特征处理】
│ ├── 特征相关性分析【分析方法】
│ ├── 特征筛选【处理步骤】
│ └── 专家验证【验证环节】
│
└── 3 模型应用【结果呈现】
├── 模型评估【效果评价】
│ ├── 准确率指标【评估指标】
│ └── 解释性指标【评估指标】
│
└── 模型解释【模型解读】
├── 特征重要性【分析维度】
├── 特征交互【分析维度】
└── 案例解释【分析维度】
理解要点
- 提出背景和具体问题:
背景:慢性肾病(CKD)是一种常见的慢性病,目前没有根治方法,且发病率高。在发展中国家,CKD往往到了终末期才被发现,此时只能通过透析治疗。
具体问题:需要一个能够及早预测和诊断CKD的AI驱动的预测分析方法,帮助医生为患者制定个性化的生活方式改善建议,减缓疾病进展。
- 研究的主要特点:
- 使用集成学习和可解释AI方法
- 基于患者的体征数据建模
- 通过血液和尿液检测结果进行预测
- 研究结果经过肾脏科医生的验证
-
正反例对比:
正例:使用随机森林模型,准确率达到99%,且能解释预测结果。
反例:单纯使用统计模型,无法解释预测原因,医生难以理解和采纳。 -
类比理解:
这就像一个经验丰富的医生,不仅能准确诊断出患者是否患有CKD,还能详细解释诊断依据,让患者明白自己的身体状况。 -
研究核心:
利用机器学习技术,建立一个既准确又可解释的CKD预测模型,帮助医生及早发现潜在的CKD患者并制定干预措施。 -
功能分析:
主要功能:早期预测CKD风险
次要功能:
- 提供可解释的预测结果
- 识别重要的影响因素
- 为医生提供决策支持
- 帮助制定个性化干预措施
-
与上文的关联:
本研究基于前人对CKD的研究基础,但创新性地结合了可解释AI技术。不同于以往单纯追求预测准确率的研究,本文更注重模型的可解释性,让医生能理解和信任AI的预测结果。 -
关键规律和矛盾:
主要矛盾:模型的准确性与可解释性之间的平衡
次要矛盾:
- 数据质量与数据缺失的处理
- 特征选择的科学性与临床实用性
- 模型复杂度与计算效率的权衡
- 预测结果与医生经验的融合
- 论文逻辑梳理:
第一部分:问题提出
- 介绍CKD的严重性和早期诊断的重要性
- 指出现有研究的局限性
第二部分:数据处理
- 数据收集:400名受试者的血液和尿液检测结果
- 数据预处理:处理缺失值、特征选择等
- 与肾脏科医生讨论确定关键特征
第三部分:模型建立
- 应用多种机器学习模型
- 重点使用随机森林和XGBoost
- 引入可解释AI工具(LIME、SHAP等)
第四部分:结果验证
- 模型性能评估
- 可解释性分析
- 与现有研究对比
- 临床专家验证
1. 确认目标
如何建立一个准确且可解释的AI系统来实现CKD的早期预测?
2. 分析过程
主要问题拆解:
- 数据层面
- 如何获取有效的患者数据?
- 收集400名受试者的血液和尿液检测结果
- 与Apollo医院合作获取临床数据
- 如何处理数据质量问题?
- 使用MCAR测试分析缺失值模式
- 采用均值插补等方法处理缺失值
- 验证数据预处理的有效性
- 建模层面
- 哪些特征最重要?
- 应用特征选择方法筛选
- 与肾脏科医生验证
- 最终确定14个关键特征
- 如何选择最佳模型?
- 对比多种机器学习模型性能
- 重点评估集成学习模型
- 采用交叉验证确保模型稳定性
- 可解释性层面
- 如何让预测结果可解释?
- 使用LIME解释单个预测
- 使用SHAP分析特征重要性
- 采用对比解释模型(CEM)展示特征变化影响
3. 实现步骤
- 数据准备阶段
- 特征工程阶段
- 模型训练阶段
- 可解释性分析阶段
- 临床验证阶段
4. 效果展示
- 目标:早期预测CKD风险
- 过程:从数据处理到模型训练再到可解释性分析
- 问题:数据质量、模型选择、可解释性实现
- 方法:集成学习+可解释AI
- 结果:随机森林模型准确率99%
- 数字:14个关键特征,400名受试者数据
金手指
本研究的"金手指"是将集成学习与可解释AI相结合的方法,这个方法可以应用于:
- 其他慢性病预测
- 医疗风险评估
- 个性化治疗方案制定
- 临床决策支持
- 患者健康管理
这个框架不仅解决了CKD预测问题,还为其他医疗AI应用提供了可复制的解决方案。
解法拆解
1. 逻辑关系拆解
目的:构建准确且可解释的CKD早期预测模型
问题:
- 数据质量问题:存在大量缺失值
- 特征选择问题:需要识别关键预测因子
- 模型可解释性问题:需要让医生理解预测依据
解法:
-
数据预处理解法
- 子解法1:缺失值分析(因为数据完整性特征)
- 使用MCAR测试识别缺失模式
- 子解法2:数据插补(因为数据质量特征)
- 使用均值、中位数等多种插补方法
- 子解法3:插补验证(因为数据可靠性特征)
- 使用ML模型验证插补效果
- 子解法1:缺失值分析(因为数据完整性特征)
-
特征工程解法
- 子解法1:统计分析(因为特征显著性特征)
- 进行特征统计显著性检验
- 子解法2:相关性分析(因为特征相关性特征)
- 分析特征与目标变量的关系
- 子解法3:专家验证(因为医学专业性特征)
- 与肾病专家确认特征选择合理性
- 子解法1:统计分析(因为特征显著性特征)
-
模型构建解法
- 子解法1:模型训练(因为预测准确性特征)
- 使用贝叶斯和回归模型
- 子解法2:可解释性分析(因为模型透明度特征)
- 应用XAI工具解释模型决策
- 子解法3:性能评估(因为模型可靠性特征)
- 使用多维度评估指标
- 子解法1:模型训练(因为预测准确性特征)
2. 逻辑链分析
这是一个混合型的逻辑网络,可以表示为:
数据预处理
├── 缺失值分析
│ ├── MCAR测试
│ └── 缺失模式识别
├── 数据插补
│ ├── 均值插补
│ ├── 中位数插补
│ └── 其他技术
└── 插补验证
└── ML模型验证
特征工程
├── 统计分析
├── 相关性分析
└── 专家验证
模型构建
├── 模型训练
├── 可解释性分析
└── 性能评估
3. 隐性特征分析
识别出的隐性特征包括:
- 数据质量评估标准:未明确定义,但贯穿整个预处理过程
- 特征重要性阈值:在特征选择过程中未明确说明
- 模型可解释性与准确性的平衡点:在模型选择中隐含
- 医学专家知识的整合方式:在特征验证过程中未详细说明
4. 潜在局限性
-
数据局限:
- 样本量可能不足
- 数据来源单一(仅来自一家医院)
- 缺乏多样性(未考虑不同人群特征)
-
方法局限:
- 插补方法可能引入偏差
- 特征选择可能过度依赖专家主观判断
- 模型可能过度拟合特定数据集
-
应用局限:
- 可能需要大量计算资源
- 实时性可能不足
- 可能需要专业人员操作维护
-
验证局限:
- 缺乏外部独立数据集验证
- 缺乏长期随访数据支持
- 未在真实临床环境中测试
全流程
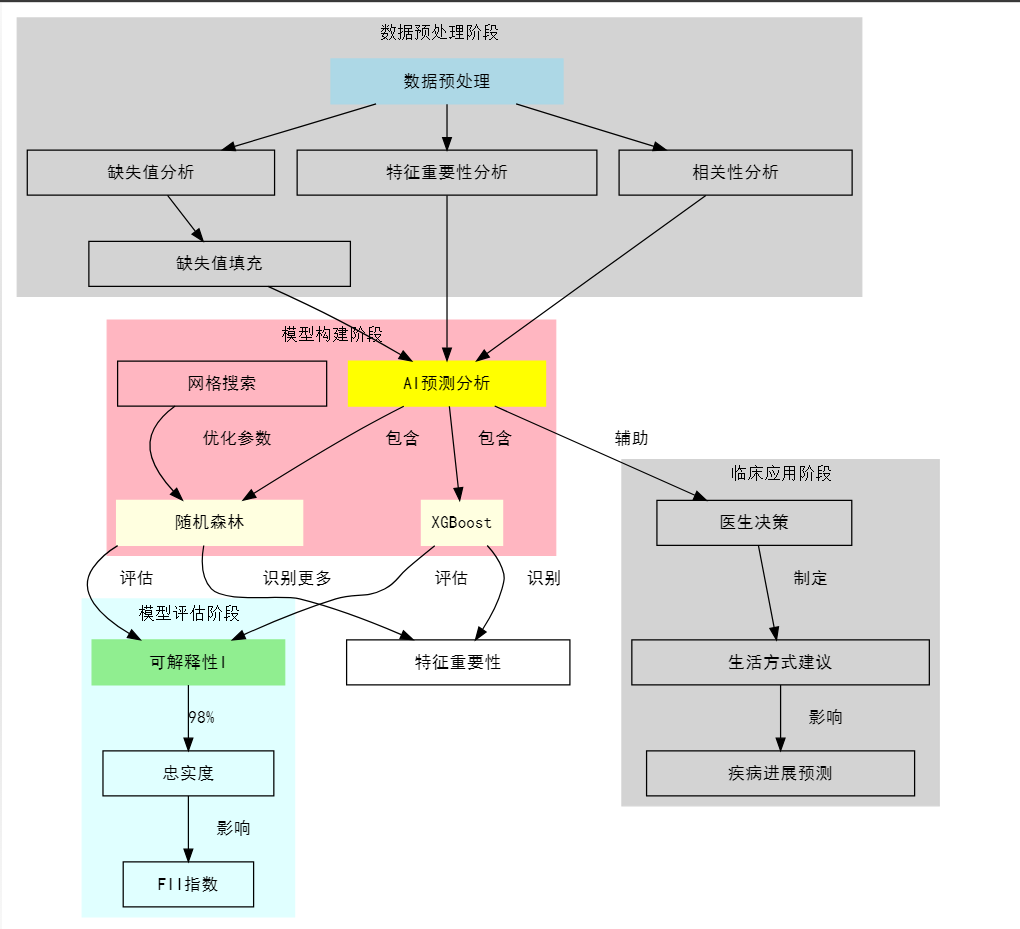
数据
- 数据收集:
- 数据来源于 UCI 机器学习存储库:
- 总共400个样本(250名 CKD 患者,150名健康个体)
- 25个特征指标来自血液和尿液检测(14个名义型变量,11个数值型变量)
- 数据收集自印度阿波罗医院
- 数据处理发现规律:
- 缺失值分析:
- 多个特征存在显著缺失数据(如红细胞计数37.81%,红细胞比容32.58%)
- 分析显示缺失模式并非完全随机
- 使用均值填充和K近邻方法处理缺失值
- 关联性分析:
- 发现与 CKD 存在强相关的特征:
- 血红蛋白(相关系数: 0.73)
- 比重(0.69)
- 红细胞压积(0.68)
- 红细胞计数(0.63)
- 白蛋白(0.59)
- 高血压(0.58)
- 数学模型构建:
- 测试了多个机器学习模型:
- 随机森林表现最好:
- 准确率 99%
- 精确率 98%
- 召回率 100%
- F1 值 99%
- 模型识别出的关键预测特征:
- 血红蛋白水平
- 红细胞压积
- 血清肌酐
- 白蛋白
- 红细胞计数
- 随机森林表现最好:
该研究成功开发了一个可解释的 AI 模型,可以:
- 高精度预测 CKD
- 识别关键生物标志物
- 提供医疗专业人员可以理解和信任的可解释结果
- 帮助 CKD 的早期检测和干预

















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









