









论文:HYBGRAG: Hybrid Retrieval-Augmented Generation on Textual and Relational Knowledge Bases
论文大纲
├── 1 研究背景【介绍研究动机】
│ ├── 半结构化知识库(SKB)的特点【定义介绍】
│ │ ├── 包含文本文档【组成部分】
│ │ └── 文档间存在关联关系【关系描述】
│ ├── 现有方法的局限【问题阐述】
│ │ ├── RAG仅检索文本【局限性】
│ │ └── GRAG仅使用结构化知识【局限性】
│ └── 混合问题(HQA)的挑战【研究难点】
│ ├── 需要同时利用文本和关系信息【特征说明】
│ └── 检索过程复杂【技术难点】
│
├── 2 关键发现【实证分析】
│ ├── 挑战一:混合源问题【分析结果】
│ │ ├── 文本和图谱信息互补【特征发现】
│ │ └── 需要协同检索策略【解决方向】
│ └── 挑战二:精炼需求问题【分析结果】
│ ├── LLM难以区分文本和关系信息【问题表现】
│ └── 需要多轮迭代优化【解决方向】
│
├── 3 HYBGRAG方法【技术方案】
│ ├── 检索器组件【核心模块】
│ │ ├── 文本检索模块【功能单元】
│ │ ├── 混合检索模块【功能单元】
│ │ └── 路由器【控制单元】
│ └── 评论模块【辅助模块】
│ ├── 验证器【功能单元】
│ └── 评论器【功能单元】
│
└── 4 实验验证【效果评估】
├── 在STARK基准上的表现【评估结果】
│ ├── Hit@1提升51%【性能指标】
│ └── 优于现有方法【对比结果】
└── 方法优势【方案特点】
├── 主动性:自动精炼输出【特征优势】
├── 适应性:处理多类问题【特征优势】
├── 可解释性:决策路径清晰【特征优势】
└── 有效性:性能显著提升【特征优势】
理解
- 背景与问题:
- 大类问题:解决检索增强生成(RAG)在复杂知识库中的局限性
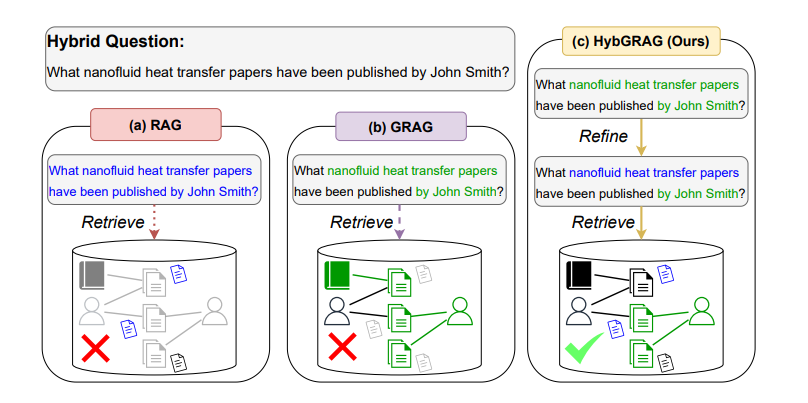
- 具体问题:现有方法无法同时处理文本和关系型信息,导致在回答混合问题时效果不佳。比如查询"约翰史密斯发表的纳米流体热传递论文"时,需要同时理解作者关系和论文主题
- 概念性质:
- 性质:HYBGRAG是一个混合检索增强生成系统
- 形成原因:由于半结构化知识库同时包含文本和关系信息,传统单一检索方法无法满足需求
- 案例对比:
- 正例:查询"2012年某机构发表的光学论文",HYBGRAG可以同时处理机构关系和论文主题
- 反例:单纯的文本RAG只能检索文本内容,无法理解机构与论文的关联关系
- 类比理解:
HYBGRAG就像一个精明的图书管理员:
- 不仅知道每本书的内容(文本信息)
- 还了解书籍之间的关联(关系信息)
- 当读者需要查找特定主题和作者的书时,可以同时运用这两种知识
- 概念介绍与总结:
HYBGRAG是一个智能检索系统,主要包含:
- 检索器组件:负责文本和关系信息的检索
- 评论模块:负责验证和优化检索结果
核心创新在于实现了文本和关系信息的协同检索
-
概念重组:
"混合检索增强生成"可以重组为:“混合多种检索方式,增强生成效果” -
上下文关联:
本文是对传统RAG方法的突破性改进,解决了半结构化知识库检索的难题 -
关键规律:
主要矛盾:文本信息与关系信息的协同处理
次要矛盾:
- 检索效率问题
- 结果准确性问题
- 系统复杂度问题
- 功能分析:
核心功能:实现混合问题的精确回答
具体表现:
- 定量:Hit@1提升51%
- 定性:主动性、适应性、可解释性、有效性
- 来龙去脉:
- 起因:传统RAG无法处理混合问题
- 发展:提出HYBGRAG解决方案
- 结果:显著提升了检索效果
- 创新点:
- 技术创新:提出检索器组件和评论模块的双模块架构
- 方法创新:实现文本和关系信息的协同检索
- 应用创新:在混合问题答案检索中取得突破性进展
1. 确认目标
主要目标:如何在半结构化知识库中实现高效的混合信息检索?
2. 分析过程
层层分解问题:
- 如何处理混合信息检索?
- 问题:传统方法要么只关注文本,要么只关注关系
- 解决:设计检索器组件,包含文本检索模块和混合检索模块
- 效果:能够同时处理文本和关系信息
- 如何确保检索准确性?
- 问题:LLM容易混淆文本和关系信息
- 解决:引入评论模块进行验证和反馈
- 效果:通过多轮迭代提升准确性
- 如何优化检索结果?
- 问题:第一次检索可能不够准确
- 解决:设计自反思机制,根据反馈调整策略
- 效果:逐步提升检索质量
3. 实现步骤
- 检索阶段:
- 输入:混合问题
- 路由器判断使用何种检索模块
- 执行检索获取候选结果
- 验证阶段:
- 评论模块验证结果
- 若不满足要求,生成反馈
- 重新进行检索
- 优化阶段:
- 根据反馈调整检索策略
- 迭代改进直到满足要求
4. 效果展示
目标:提升混合问题检索性能
过程:采用双模块架构(检索器+评论模块)
问题:解决文本和关系信息协同检索难题
方法:HYBGRAG框架
结果:在STARK基准测试中性能显著提升
数字:Hit@1提升51%
5. 领域金手指
本文的金手指是"自反思机制",具体表现在:
- 案例一:论文作者查询
- 问题:查找特定作者的特定主题论文
- 应用金手指:通过反馈迭代提升检索准确性
- 案例二:机构出版物查询
- 问题:查找特定机构的特定年份论文
- 应用金手指:根据反馈调整实体识别和关系抽取
- 案例三:多条件组合查询
- 问题:多个约束条件下的文献检索
- 应用金手指:通过反馈优化检索策略
这个金手指的关键在于:
- 能够自动识别错误
- 生成有针对性的反馈
- 指导检索策略调整
- 持续优化直到达到目标
结构分析
1. 层级结构分析
叠加形态(从底层到高层)
顶层 - 智能混合检索(高级功能)
↑
中层 - 自反思验证(优化功能)
↑
底层 - 基础检索(基本功能)
构成形态(部分到整体)
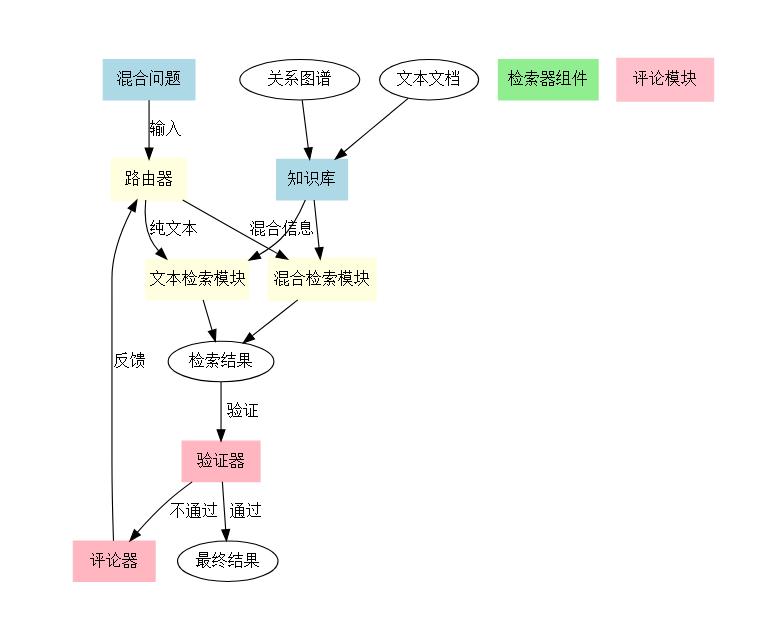
HYBGRAG系统
├── 检索器组件
│ ├── 文本检索模块
│ │ └── 相似度搜索
│ ├── 混合检索模块
│ │ ├── 图检索器
│ │ └── VSS排序器
│ └── 路由器
│ ├── 实体识别
│ └── 关系抽取
└── 评论模块
├── 验证器
│ └── 验证上下文
└── 评论器
└── 纠正反馈
分化形态(从整体到部分)
混合问题
├── 文本信息需求
│ ├── 主题识别
│ └── 内容匹配
└── 关系信息需求
├── 实体关联
└── 路径推理
2. 线性结构分析(处理流程)
问题输入 → 路由决策 → 检索执行 → 结果验证 → 反馈生成 → 策略调整 → 结果输出
3. 矩阵结构分析(问题-方法映射)
文本检索 混合检索 自反思
简单问题 √ × ×
混合问题 × √ √
复杂问题 × √ √√
4. 系统动力学分析
关键变量:
- 输入:问题复杂度
- 中间变量:检索策略、验证结果、反馈质量
- 输出:检索准确性
反馈环路:
问题输入 → 检索策略选择
↑ ↓
反馈调整 ← 结果验证
组合分析结论
- 系统特点:
- 层级性:从基础检索到智能混合检索的进阶
- 模块化:检索和评论模块的清晰分工
- 适应性:能根据问题类型选择策略
- 迭代性:通过反馈不断优化结果
- 关键创新:
- 构成形态上:实现了文本和关系检索的有机结合
- 动力学上:建立了有效的自我优化机制
- 系统优势:
- 结构完整:覆盖检索全流程
- 反馈闭环:保证结果质量
- 灵活适应:满足不同需求
这种多维度的结构分析帮助我们更深入地理解HYBGRAG系统的设计理念和工作机制,展示了其如何通过不同层次和模块的协同工作来解决混合问题检索的挑战。
观察和假设
一、关键观察
- 不寻常现象:
- 现有方法在混合问题上表现差
- 文本检索和关系检索各自效果好,但组合效果不理想
- LLM在处理混合问题时经常混淆不同类型的信息
- 变量分析:
- 改变检索方式:单一检索 vs 混合检索
- 改变问题类型:纯文本、纯关系、混合问题
- 改变迭代次数:单次检索 vs 多轮优化
二、提出假设
- 主要假设:
- H1:混合问题需要同时利用文本和关系信息才能得到最佳答案
- H2:LLM需要多轮反馈才能准确区分文本和关系信息
- H3:通过自反思机制可以提升检索质量
- 假设依据:
观察现象:单一检索方法效果差
推理过程:
- 文本检索忽略了关系信息
- 关系检索忽略了文本内容
- 两种信息都必要且互补
得出假设:需要协同检索策略
三、验证过程
- 实验验证:
- 在STARK基准测试上进行评估
- 对比不同检索策略的效果
- 分析迭代优化的影响
- 结果分析:
验证H1:
- 方法:比较单一检索和混合检索效果
- 结果:混合检索Hit@1提升47.4%
- 结论:假设成立
验证H2:
- 方法:分析LLM的多轮表现
- 结果:正确率从67.69%提升到92.31%
- 结论:假设成立
验证H3:
- 方法:对比有无自反思机制的效果
- 结果:Hit@1总体提升51%
- 结论:假设成立
四、发现规律
- 信息协同原则:
- 文本和关系信息相互补充
- 协同检索优于单一检索
- 迭代优化原则:
- 多轮反馈效果优于单轮
- 反馈质量影响优化效果
- 系统集成原则:
- 模块化设计提升灵活性
- 闭环反馈保证性能
这种观察-假设-验证的分析方法帮助我们:
- 准确识别问题本质
- 提出合理的解决方案
- 验证方案的有效性
- 总结普遍规律
通过这个过程,作者不仅解决了具体的混合问题检索难题,还提供了一个可推广的解决框架。
解法拆解
1. 逻辑拆解
HYBGRAG解法拆解:
HYBGRAG = 检索器组件(处理混合信息) + 评论模块(优化结果)
子解法1:检索器组件
原因:需要同时处理文本和关系信息
├── 文本检索模块(处理纯文本信息)
│ └── 因为:部分问题只需文本匹配
├── 混合检索模块(协同处理)
│ └── 因为:复杂问题需要关联信息
└── 路由器(决策模块)
└── 因为:需要智能选择检索策略
子解法2:评论模块
原因:需要保证检索质量并持续优化
├── 验证器(结果验证)
│ └── 因为:需要评估检索结果质量
└── 评论器(反馈生成)
└── 因为:需要指导检索策略调整
例子:
查询"约翰史密斯发表的纳米流体热传递论文"
- 检索器:识别作者实体和论文主题
- 评论模块:验证检索结果是否符合两个条件
2. 逻辑链分析
决策树形式:
问题输入
├── 路由决策
│ ├── 纯文本问题 → 文本检索
│ └── 混合问题 → 混合检索
├── 检索执行
│ ├── 实体抽取
│ ├── 关系识别
│ └── 文本匹配
└── 结果优化
├── 质量验证
└── 策略调整
3. 隐性方法分析
发现的隐性关键步骤:
- 自适应路由机制
- 动态调整检索策略
- 根据问题特征选择模块
- 验证上下文构建
- 收集推理路径
- 构建验证依据
- 反馈优化策略
- 错误类型识别
- 纠正建议生成
4. 隐性特征分析
发现的隐性特征:
- 问题复杂度评估
- 特征:需要判断问题涉及的信息类型
- 方法:设计专门的问题路由机制
- 检索质量度量
- 特征:需要评估检索结果的完整性
- 方法:引入验证上下文机制
5. 潜在局限性
- 计算资源消耗
- 多轮迭代增加计算开销
- API调用次数较多
- 依赖性问题
- 依赖LLM的性能
- 需要高质量的知识库
- 扩展性限制
- 特定领域的知识迁移困难
- 新类型问题需要重新训练
- 时效性问题
- 知识库需要定期更新
- 实时性要求高的场景可能不适用
全流程
1. 什么是混合检索问题?
答:需要同时利用文本内容和关系结构来找答案的问题。例如"查找约翰史密斯发表的纳米流体论文",既需要理解作者关系,又需要理解论文主题。
2. 为什么现有方法无法很好地解决混合检索问题?
答:因为传统RAG只关注文本检索,GRAG只关注关系检索,无法有效协同两种信息。实验表明,单独使用任一方法的效果都显著低于协同使用。
3. HYBGRAG如何处理文本和关系信息的协同?
答:通过检索器组件中的混合检索模块,先用图检索获取相关实体,再用向量相似度对相关文档排序,实现两种信息的协同增强。
4. 为什么需要评论模块?
答:因为LLM在第一次尝试时常常难以准确区分文本和关系信息。评论模块通过验证和反馈来指导检索策略的调整,提升检索质量。
5. HYBGRAG的自反思机制是如何工作的?
答:通过验证器评估检索结果,若不满意,评论器生成具体的纠正建议(如"实体识别错误"),指导路由器调整检索策略。
观察到:
LLM反馈 → 检索准确率
- 无反馈:67.69%
- 简单反馈:79.14%
- 纠正反馈:92.31%
推断出:
反馈质量与检索效果呈正相关
6. HYBGRAG相比现有方法的主要优势是什么?
答:四大优势:
- 主动性:能自动优化检索策略
- 适应性:可处理多类型问题
- 可解释性:决策路径清晰
- 有效性:性能显著提升
7. HYBGRAG在实验中取得了什么效果?
答:在STARK基准测试中,Hit@1平均提升51%。具体表现为:
- STARK-MAG:从0.4436提升到0.6540
- STARK-PRIME:从0.1844提升到0.2856
8. HYBGRAG存在哪些局限性?
答:主要局限:
- 计算开销大(需要多轮迭代)
- 依赖LLM质量
- 领域迁移困难
- 实时性要求高的场景可能不适用
9. HYBGRAG的核心创新是什么?
答:创新在于提出了"检索器组件+评论模块"的双模块架构,实现了:
- 文本和关系信息的协同检索
- 基于自反思的迭代优化
- 可解释的决策路径
10. HYBGRAG如何保证检索质量?
答:通过三重保障机制:
- 路由器智能选择检索策略
- 验证器评估检索结果
- 评论器指导策略调整
这些问答涵盖了HYBGRAG的核心概念、工作机制、创新点、优势和局限性,有助于全面理解这个框架。
提示词
检索反馈提示词
检索的文档不正确。
反馈:<<<{对提取的实体和关系的反馈}>>>
问题:<<<{问题}>>>
检索的文档不正确。请基于新提取的主题实体和有用关系重新回答。知识图谱或文本文档哪个更有助于缩小搜索范围?你必须用不超过两个词回答其中之一。
验证器提示词
你是一个有帮助的、遵循模式的助手。
<<<{检索验证示例,每种实体类型2个}>>>
### 问题:<<<{问题}>>>
### 文档:<<<{文档内容和推理路径}>>>
### 任务:该文档是否符合问题的要求?仅回答是或否。
评论器提示词
你是一个有帮助的、遵循模式的助手。
<<<{30个行动和反馈对示例}>>>
问题:<<<{问题}>>>
主题实体:<<<{提取的实体}>>>
有用关系:<<<{提取的关系}>>>
请指出从问题中提取的错误实体或关系(如果有的话)。
主要问题处理提示词
你是一个有帮助的、遵循模式的助手。
给定以下问题,按要求提取信息。规则:1. 每个实体必须在括号中恰好有一个类别。2. 严格按照示例执行。
<<<{实体和关系提取示例,每个域5个}>>>
### 问题类型:简单、带条件的简单、集合、比较、聚合、多跳、后处理、错误前提。
### 问题:<<<{问题}>>>
### 任务:这是哪种类型的问题?答案必须是其中之一。
### 动态性:实时、快速变化、缓慢变化、静态。
### 问题:<<<{问题}>>>
### 任务:这个问题属于哪种动态性类别?用一个词回答,答案必须是其中之一。
### 领域:音乐、电影、金融、体育、百科。
### 问题:<<<{问题}>>>
### 任务:这个问题来自哪个领域?用一个词回答,答案必须是其中之一。
根据实体类型和关系类型,从问题中提取主题实体和有用关系。
实体类型:<<<{实体类型}>>>
关系类型:<<<{关系类型}>>>
问题:<<<{问题}>>>
### 参考来源:知识图谱、文本文档。
### 问题:<<<{问题}>>>
### 任务:基于提取的实体,哪个参考来源有助于回答问题?必须选择其中之一并且回答不超过两个词。
错误检查提示词
你是一个有帮助的、遵循模式的助手。
<<<{5个行动和反馈对示例}>>>
### 参考来源:<<<{来源}>>>
### 问题:<<<{问题}>>>
### 查询时间:<<<{问题时间}>>>
### 查询类型:<<<{问题类型}>>>
### 查询动态性:<<<{动态性}>>>
### 查询领域:<<<{领域}>>>
### 任务:如果存在,请指出关于问题的错误信息(参考来源、查询类型、查询动态性、查询领域)。答案必须是其中之一。
生成器提示词
你是一个有帮助的、遵循模式的助手。
<<<{1个思维链提示示例}>>>
### 参考:<<<{参考}>>>
### 参考来源:<<<{来源}>>>
### 问题:<<<{问题}>>>
### 查询时间:<<<{问题时间}>>>
### 查询类型:<<<{问题类型}>>>
### 查询动态性:<<<{动态性}>>>
### 查询领域:<<<{领域}>>>
### 任务:你将获得一个问题、参考资料以及在太平洋时区(PT)提出问题的时间,称为查询时间。
查询时间的格式为 mm/dd/yyyy, hh:mm:ss PT。参考资料可能有助于回答问题。如果问题包含错误前提或假设,回答"无效问题"。首先,系统地详细列出在到达正确答案之前需要解决的所有问题。然后,使用前面问题的答案解决每个子问题,得出最终解决方案。
最终答案是什么?
评估器提示词
### 问题:<<<{问题}>>>
### 真实答案:<<<{标准答案}>>>
### 预测答案:<<<{生成器输出}>>>
### 任务:基于问题和真实答案,预测答案是准确的、不正确的还是缺失的?答案必须是其中之一且用一个词回答。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









