









官方文档:
- https://langchain-ai.github.io/langgraph/tutorials/introduction/
本文版本:
-
langgraph-0.3.19
-
langchain-0.3.3
pip install langgraph==0.3.19 langchain==0.3.3StateGraph
智能体开发的核心是,你的工作流要理清楚。
LangGraph 把将工作流程建模为 图结构:
-
节点 代表操作或步骤(如调用 LLM、访问数据库、搜索网页、反思评估、调用 DIY 工具等)
-
边 表示步骤之间的关系
当一个节点完成后,会沿着一个 或 多个边 向其他节点发信息,边告诉下一步做什么。
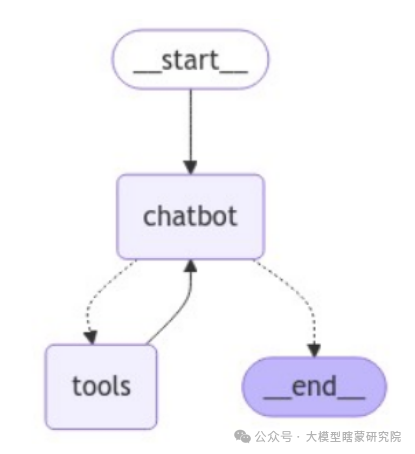
上图的边有实线边、虚线边:
-
实线边:自动触发的边
-
虚线边:满足设定才触发的边
状态图 StateGraph = 图结构 Graph (节点、边)+ 状态 State,每一个节点的运行都要接收并更新当前状态。
-
状态
State是一个数据结构,可以是任何 Python 类型,默认是TypeDict类型
StateGraph 的强大之处在于它能够表达复杂的非线性执行流程,特别适合AI应用中的多步骤推理和决策过程。
一、基本图结构和节点
掌握如何创建基本的 LangGraph 图结构,定义节点和连接它们。
在 LangGraph 中,一切始于 StateGraph 对象,它是你构建应用的基础:
这就像是在一张白纸上画下第一笔,你正在创建一个框架,稍后会在这个框架中添加各种功能。
注意我们使用了 TypedDict 来定义状态的结构。这不仅让代码更加清晰,也让 Python 的类型检查器能够帮助你避免错误。
它允许你:
-
定义一系列节点(代表工作流中的处理步骤)
-
建立节点之间的连接关系(简单边和条件边)
-
管理状态在节点间的传递和转换
-
执行复杂的基于条件的路由逻辑
简而言之,StateGraph使你能够创建复杂的、非线性的工作流程,特别适合需要动态决策的AI应用,如对话系统、多步骤推理、决策树等。
1. 创建基本图结构
from langgraph.graph import StateGraph
# 导入 LangGraph 的 StateGraph 类
from typing import TypedDict, Annotated
# 提供类型安全的字典结构,TypedDict在大型、复杂项目中的优势尤为明显,比 普通的dict 好
class GraphState(TypedDict):
# 创建一个继承自 TypedDict 的类,用于定义状态结构
input: str
# 输入字段,存储用户的原始输入
output: str
# 输出字段,存储最终结果
graph = StateGraph(GraphState)
# 创建状态图 StateGraph 实例,传入我们定义的状态类型参数说明:
-
StateGraph(state_type)- 接收定义状态结构的 TypedDict 类
2. 添加节点
节点是图中执行实际工作的部分。
每个节点都是一个函数,接收当前状态并返回更新:
def greeting_node(state: GraphState) -> dict:
"""一个简单的问候节点"""
user_input = state["input"]
# 从状态中获取用户输入
return {"output": f"你好!你说的是:{user_input}"}
# 返回包含问候消息的字典
# 将节点添加到图中,add_node(name, function) - 接收节点名称和处理函数
graph.add_node("greeting", greeting_node) # 将问候函数添加为名为"greeting"的节点想象节点就像是流水线上的工作站,每个工作站负责特定的任务。
在这个例子中,greeting_node 接收用户输入并生成一个问候语。
每个节点函数应接收当前状态并返回状态更新。
3. 添加简单边
定义了节点后,需要指定它们之间的连接。
这就像是在节点之间画箭头,告诉系统数据应该如何流动。
set_entry_point 定义了图的起点,而 add_edge 则指定了从一个节点到另一个节点的路径。
# 设置入口节点
graph.set_entry_point("greeting") # 将greeting节点设为工作流的起点
# 添加响应节点
graph.add_node("response", response_node) # 假设 response_node 已定义
# add_edge(start, end) - 接收起始和结束节点名称
graph.add_edge("greeting", "response") # 创建从greeting到response的流动路径
# 添加结束边
from langgraph.graph.graph import START, END # 导入END常量
graph.add_edge("answer_reasoning", END) # END: 特殊常量,表示图的结束点4. 添加条件边
条件边允许你根据当前状态动态决定数据应该流向哪个节点,实现智能路由。
基本用法分为两步:
-
定义路由函数:一个接收状态并返回路由决策的函数
-
添加条件边:使用
add_conditional_edges方法连接节点
# 定义条件路由函数
def complex_router(state: dict):
text_length = len(state["content"]) # 获取内容长度作为分支依据
# 根据返回值,系统查找映射字典中的对应关系(分流到不同节点做事)
if text_length < 10:
return "short" # 返回"short"标识符
elif text_length < 50:
return "medium" # 返回"medium"标识符
else:
return "long" # 返回"long"标识符
# 添加条件边的方法 add_conditional_edges
graph.add_conditional_edges(
"input_processor",
# 源节点,当 input_processor 节点处理完成后,调用 complex_router 函数
complex_router,
{
"short": "short_handler", # router返回"short"时,流向short_handler节点(简短回复)
"medium": "medium_handler", # router返回"medium"时,流向medium_handler节点(中等回复)
"long": "long_handler" # router返回"long"时,流向long_handler节点(长篇回复)
}
)add_conditional_edges 参数说明:
-
node:源节点名称 -
condition:条件函数,该函数接收状态并返回下一个节点的名称 -
default_node:(可选) 当条件函数未返回匹配节点时的默认节点
返回符合图的输出状态类型的结果。
5. 编译图
# 编译图:将定义好的图结构转换为可执行的形式
# 编译后的图才能被invoke方法调用
langgraph = langgraph.compile()6. 执行图
编译步骤将你定义的逻辑转换为可执行的形式,就像是将蓝图变成实际的建筑。
# 执行图:传入符合InputState格式的问题,开始执行整个工作流
# 返回符合OutputState格式的结果
result = langgraph.invoke({"question": "李白作了多少首诗?"})invoke 方法则启动图的执行,从入口点开始,按照定义的路径流经各个节点。
参数说明:
- input:符合图的输入状态类型的数据
返回符合图的输出状态类型的结果。
7. 创建多节点图
用户输入首先经过 process_node 处理,然后结果传递给 respond_node 生成最终输出。
from langgraph.graph import StateGraph
from typing import TypedDict
class ChatState(TypedDict):
input: str
intermediate: str
output: str
# 创建状态图
graph = StateGraph(ChatState)
# 定义节点
def process_node(state: ChatState) -> dict:
return {"intermediate": f"处理: {state['input']}"}
def respond_node(state: ChatState) -> dict:
return {"output": f"响应: {state['intermediate']}"}
# 添加节点
graph.add_node("process", process_node)
graph.add_node("respond", respond_node)
# 连接节点
graph.set_entry_point("process")
graph.add_edge("process", "respond")
# 编译和运行
compiled_graph = graph.compile()
result = compiled_graph.invoke({"input": "如何使用 LangGraph?"})
print(result) # 包含完整的状态输出:
{'input': '如何使用 LangGraph?',
'intermediate': '处理: 如何使用 LangGraph?',
'output': '响应: 处理: 如何使用 LangGraph?'}8.流式输出
def stream_graph_updates(user_input: str):
# 使用 LangGraph 的流式处理功能
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
# 打印 AI 助手的回复
print("Assistant:", value["messages"][-1].content)
# 创建一个无限循环来接收用户输入
while True:
try:
# 获取用户输入
user_input = input("User: ")
# 检查用户是否想要退出对话 (输入 quit、exit、q 退出)
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 处理用户输入并流式输出回复
stream_graph_updates(user_input)
except:
# 如果 input() 函数不可用的回退方案
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break和 Qwen 结合:
-
think节点:执行深度问题分析,包括问题分解、知识调用等
-
respond节点:基于思考过程生成结构化、清晰的最终回答
-
debug节点,显示中间思考过程,便于开发和调试
from langgraph.graph import StateGraph
from typing import TypedDict, List, Dict, Any
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
import os
# 设置环境变量
os.environ["OPENAI_API_KEY"] = "sk-f80c..."
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 创建 LangChain ChatOpenAI 实例
model = ChatOpenAI(
model="qwen-max", # 使用通义千问模型
temperature=0.7 # 添加适当的温度参数,平衡创新性和一致性
)
# 定义状态类型
class ChatState(TypedDict):
messages: List[Dict[str, Any]] # 存储对话历史
intermediate_thoughts: str # 存储中间思考过程
# 创建状态图
graph = StateGraph(ChatState)
# 定义思考节点 - 进行深度分析和推理
def think(state: ChatState) -> Dict:
"""思考节点:分析用户消息,分解问题,查找相关信息,形成推理过程"""
# 从状态中获取最后一条用户消息和历史
user_message = state["messages"][-1]["content"]
history = state["messages"][:-1] # 排除最后一条用户消息
# 构建详细的思考提示词
system_prompt = """
你现在处于思考模式。分析用户的问题并执行以下步骤:
1. 问题分解:将复杂问题分解为更小的子问题
2. 知识调用:确定回答每个子问题所需的知识领域
3. 推理链:逐步推理,从已知信息推导出结论
4. 考虑替代观点:思考不同角度或方法
5. 识别假设:明确你的答案所基于的假设
6. 评估证据:评估支持你结论的证据强度
只输出你的思考过程,格式如下:
问题分解:
[将问题分解为几个子问题]
相关知识:
[列出回答所需的关键知识点]
推理过程:
[详细阐述你的推理步骤]
可能的误区:
[指出用户可能存在的误解或常见错误]
结论准备:
[总结你的发现,为最终回答做准备]
"""
# 构建上下文,包括历史对话
context = "对话历史:\n"
for msg in history:
role = "用户" if msg["role"] == "user" else "助手"
context += f"{role}: {msg['content']}\n"
context += f"\n当前问题: {user_message}"
# 调用模型进行深度思考
response = model.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=context)
])
# 返回更新的状态
return {"intermediate_thoughts": response.content}
# 定义回应节点 - 生成最终回答
def respond(state: ChatState) -> Dict:
"""响应节点:基于中间思考生成结构化、全面的最终回答"""
# 获取用户问题和思考过程
user_message = state["messages"][-1]["content"]
thoughts = state["intermediate_thoughts"]
history = state["messages"][:-1]
# 构建详细的回答提示词
system_prompt = """
你是一个优秀的助手。基于你的思考过程,提供一个清晰、结构化、全面的回答。
遵循以下原则:
1. 直接回答:先给出直接清晰的答案
2. 解释原理:解释背后的原理或概念
3. 提供例子:用具体例子说明
4. 考虑上下文:考虑用户的背景和需求
5. 平衡深度和简洁:提供足够深度但避免过于冗长
不要在回答中提及或引用你的思考过程,它只是你的内部分析。
最终回答应该自然流畅,就像你直接思考出来的一样。
"""
# 构建上下文
context = "对话历史:\n"
for msg in history:
role = "用户" if msg["role"] == "user" else "助手"
context += f"{role}: {msg['content']}\n"
context += f"\n当前问题: {user_message}\n\n你的思考过程:\n{thoughts}"
# 调用模型生成最终回答
response = model.invoke([
SystemMessage(content=system_prompt),
HumanMessage(content=context)
])
# 构建助手消息并更新状态
assistant_message = {"role": "assistant", "content": response.content}
return {"messages": state["messages"] + [assistant_message]}
# 添加调试节点 - 在控制台显示中间思考过程(可选)
def debug(state: ChatState) -> Dict:
"""调试节点:显示中间思考过程,不修改状态"""
thoughts = state["intermediate_thoughts"]
print("\n---------------------- 思考过程 ----------------------")
print(thoughts)
print("------------------------------------------------------\n")
return {} # 不修改状态
# 添加节点到图中
graph.add_node("think", think) # 思考节点
graph.add_node("debug", debug) # 调试节点(可选)
graph.add_node("respond", respond) # 回应节点
# 连接节点
graph.set_entry_point("think")
graph.add_edge("think", "debug") # 思考后进行调试(可选)
graph.add_edge("debug", "respond") # 调试后进行回应
graph.set_finish_point("respond")
# 编译图
compiled_graph = graph.compile()
# 创建格式化输出函数
def format_message(role, content):
"""格式化消息,使控制台输出更清晰"""
if role == "user":
return f"\n👤 用户: {content}"
else:
return f"\n🤖 助手: {content}"
# 创建对话管理函数
def chat(user_input: str, history: List[Dict[str, str]] = None):
"""处理用户输入并返回助手回复"""
if history is None:
history = []
# 准备状态
messages = history + [{"role": "user", "content": user_input}]
state = {"messages": messages, "intermediate_thoughts": ""}
# 运行图
result = compiled_graph.invoke(state)
# 返回最终消息和更新的历史
return result["messages"][-1]["content"], result["messages"]
# 主程序
if __name__ == "__main__":
print("🤖 通义千问 + LangGraph 思考-回答系统启动")
print("输入'exit'、'quit'或'q'退出\n")
history = []
while True:
user_input = input("\n👤 用户: ")
if user_input.lower() in ["exit", "quit", "q"]:
print("\n🤖 助手: 再见!")
break
# 显示思考中提示
print("\n🤖 助手: (思考中...)")
# 处理用户输入
response, history = chat(user_input, history)
# 显示回答
print(f"\n🤖 助手: {response}")
# 增加流式输出支持(可选功能)
def stream_chat(user_input: str, history: List[Dict[str, str]] = None):
"""带流式输出的对话处理"""
if history is None:
history = []
# 准备状态
messages = history + [{"role": "user", "content": user_input}]
state = {"messages": messages, "intermediate_thoughts": ""}
# 使用流式输出
for event in graph.stream(state):
if "respond" in event:
last_message = event["respond"]["messages"][-1]["content"]
yield last_message
# 返回完整历史记录
result = compiled_graph.invoke(state)
return result["messages"]编程秘籍 1
对于小白来说,快速培养代码感,遇到不熟悉的模块,就用 模块三问:
- 这个模块是用来做什么的?(功能/作用)
- 这个模块最常用的方法有哪些?(常用方法)
- 这些方法的参数是什么?(参数说明)也就是说,当学完了 StateGraph,脑海中得有 TA 的【知识晶体】。
1. 这个模块是用来做什么的?
StateGraph 是 LangGraph 库中用于构建基于状态的工作流图的核心模块,允许你:
-
定义包含多个处理节点的工作流
-
在节点之间传递状态数据
-
设置条件分支和动态路由
-
构建复杂的多步骤 AI 应用
2. 这个模块最常用的方法有哪些?
StateGraph 最常用的方法包括:
-
add_node()- 添加处理节点 -
add_edge()- 添加从一个节点到另一个节点的边 -
add_conditional_edges()- 添加条件分支 -
set_entry_point()- 设置图的入口节点 -
compile()- 编译图为可执行工作流
3. 这些函数、方法的参数是什么?
-
add_node(name, function)-
name: 节点的唯一名称(字符串) -
function: 处理函数,接收状态并返回更新
-
-
add_edge(start_node, end_node)-
start_node: 起始节点名称 -
end_node: 目标节点名称
-
-
add_conditional_edges(source, router, destination_map)-
source: 源节点名称 -
router: 路由函数,返回下一个节点的名称 -
destination_map: 路由返回值到目标节点的映射
-
-
set_entry_point(node_name)-
node_name: 入口节点的名称
-
-
compile()-
无参数,返回编译后的工作流对象
-
实践检测题(由易到难)
-
在 LangGraph 中,什么是状态图(StateGraph)?
-
如何在 LangGraph 中定义状态结构?
-
编写一个简单的节点函数,它接收状态并返回更新。
-
如何将节点添加到图中?使用什么方法?
-
什么是图的入口点?如何设置它?
-
如何定义节点之间的连接?
-
在运行图之前为什么需要编译它?
-
创建一个包含三个节点的图,分别负责处理输入、分析内容和生成回复。
-
如何确保图中的数据流动符合你的期望?设计一个简单的测试方法。
-
设计一个更复杂的图,包含条件分支,根据输入内容选择不同的处理路径。
二、状态管理
深入理解 LangGraph 中的状态管理,学习如何有效地定义、更新和利用状态。
在 LangGraph 中,状态是整个图执行过程中传递的数据。
它就像是一个包裹,从一个节点传递到另一个节点,逐渐被丰富和更新。
想象你正在进行一场对话:每次交流都基于之前的对话内容。
状态就像是这个对话的记忆,它保存了所有重要的信息,让整个过程连贯有序。
定义结构化状态
想象你正在管理一个在线购物系统,系统状态包含:商品列表、总价、用户信息和折扣信息。
from typing import TypedDict, List
from langgraph.graph import StateGraph
# 使用 TypedDict
class CartState(TypedDict):
items: List[Dict] # 购物车中的商品列表
total: float # 总价
user_id: str # 用户ID
discount: float # 折扣率
graph = StateGraph(CartState)就像是为数据创建一个模板,确保所有节点(员工)都知道,它们可以期望哪些数据字段,以及每个字段的类型。
状态更新模式
在 LangGraph 中,节点可以通过两种方式更新状态。
方法一:返回部分更新,只返回需要更改的字段(写便条,默认模式)
假设我们正在构建一个简单的购物车应用,要处理商品添加和计算总价。
每个处理节点就像商场的不同部门员工,他们只关注自己负责的信息,通过便条传递更新。
-
添加商品节点(电子部门员工): "我只负责添加商品。顾客要购买一台笔记本电脑,价格5000元。请将此商品添加到购物清单。我不需要管总价、用户信息或折扣,那是其他部门的工作。"
-
计算总价节点(收银部门员工): "我只负责计算总价。根据当前购物清单和折扣率,计算出折后总价是4500元。我不需要修改商品清单或用户信息,只更新总价这一项。"
在这种方式下,每个员工只提供自己的专业领域信息,系统自动整合所有信息。
def add_item_node(state: CartState) -> dict:
"""添加商品到购物车(部分更新)"""
# 假设新商品信息来自状态中的临时字段
new_item = {"id": "123", "name": "笔记本电脑", "price": 5000}
# 只返回需要更新的字段
return {
"items": state["items"] + [new_item],
# 获取当前状态中的商品列表 + 将新商品(包装在一个列表中)添加到现有列表的末尾
# 结果被赋值给 "items" 键,使其【添加商品】节点的状态更新
}
def calculate_total_node(state: CartState) -> dict:
"""计算总价(部分更新)"""
total = sum(item["price"] for item in state["items"])
# 遍历购物车中的每件商品,获取每件商品的价格,将所有商品价格加起来得到总和
discounted_total = total * (1 - state["discount"])
# 计算折扣后的比例,将总价乘以这个比例,得到折扣后的最终价格
# 只返回需要更新的字段
return {
"total": discounted_total
# 不需要重复其他字段
}
# 添加节点(默认使用部分更新)
graph.add_node("add_item", add_item_node)
graph.add_node("calculate_total", calculate_total_node)方法二:返回完整状态:返回整个更新后的状态(填写完整表格)
只有当你需要完整状态更新(方法二)时,才需要显式设置 update_state=True 参数:
def add_item_node_full(state: CartState) -> CartState:
"""添加商品到购物车(完整状态更新)"""
# 创建状态的副本
new_state = state.copy()
# 新商品信息
new_item = {"id": "123", "name": "笔记本电脑", "price": 5000}
# 更新商品列表字段
new_state["items"] = new_state["items"] + [new_item]
# 返回完整的状态(包括未修改的字段)
return new_state
def calculate_total_node_full(state: CartState) -> CartState:
"""计算总价(完整状态更新)"""
# 创建状态的副本
new_state = state.copy()
# 计算总价
total = sum(item["price"] for item in state["items"])
# 应用折扣并更新总价字段
new_state["total"] = total * (1 - state["discount"])
# 返回完整状态
return new_state
# 添加节点(指定使用完整状态更新)
graph.add_node("add_item_full", add_item_node_full, update_state=True)
graph.add_node("calculate_total_full", calculate_total_node_full, update_state=True)
# 全部状态更新,必须显示设置 update_state=True 参数,汇报这个节点返回完整状态而非部分更新这种方式就像每个部门员工都必须填写一份包含所有信息的完整表格,即使大部分内容与之前相同。
添加商品节点(电子部门员工): "我需要填写整张表格。
-
顾客信息:张先生,ID为12345;已有商品:手机和耳机;新添加商品:笔记本电脑,价格5000元;原折扣率:10%;当前总价:尚未计算(保留原值8000元)。"
计算总价节点(收银部门员工): "我也需要填写整张表格。
-
顾客信息:张先生,ID为12345;所有商品:手机、耳机和笔记本电脑;折扣率:10%;更新后的总价:13000元乘以90%等于11700元。"
在这种方式下,每个员工都必须处理并返回整个状态,包括他们没有直接修改的部分。
应用场景:
-
第一种方式更加简洁(默认模式),适合只需更新少量字段的情况;
-
第二种方式给予你更多控制权,适合需要复杂更新逻辑的场景。
在大多数情况下,部分更新(便条方式)更高效、更安全,而完整更新(表格方式)则适用于需要复杂、相互关联更新的特殊情况。
记忆功能
LangGraph 实现记忆功能逻辑:
-
第一次对话时,我们用"对话1"作为ID
-
聊天内容被保存在记忆保存器中
-
第二次对话时,我们用相同的ID"对话1"
-
系统找到之前的对话记录,机器人就能"记住"用户的名字
# 第1步:导入记忆存储器
from langgraph.checkpoint.memory import MemorySaver
# 第2步:创建记忆存储器实例
memory = MemorySaver() # 这是一个内存中的存储器,所有状态都存在内存中
# 第3步:在编译图时指定使用这个记忆存储器
graph = graph_builder.compile(checkpointer=memory)
# 第4步:创建对话标识符配置
config = {"configurable": {"thread_id": "conversation_1"}}
# "conversation_1"是这个对话的唯一ID
# 第5步:使用相同的标识符进行多次对话
# 第一次对话
response1 = graph.invoke(
{"messages": [{"role": "user", "content": "你好,我叫小明"}]},
config # 使用前面定义的配置,包含thread_id
)
# 第二次对话(使用相同的thread_id,所以机器人会记得之前的对话)
response2 = graph.invoke(
{"messages": [{"role": "user", "content": "你还记得我的名字吗?"}]},
config # 使用相同的配置,确保是同一个对话线程
)要同时维护多个不同的对话,只需使用不同的 thread_id:
# 用户A的对话
config_user_a = {"configurable": {"thread_id": "user_a"}}
response_a = graph.invoke(
{"messages": [{"role": "user", "content": "我是用户A"}]},
config_user_a
)
# 用户B的对话
config_user_b = {"configurable": {"thread_id": "user_b"}}
response_b = graph.invoke(
{"messages": [{"role": "user", "content": "我是用户B"}]},
config_user_b
)
# 继续与用户A对话
response_a2 = graph.invoke(
{"messages": [{"role": "user", "content": "你知道我是谁吗?"}]},
config_user_a # 使用用户A的thread_id
)
# 机器人会回答知道用户A是谁
# 继续与用户B对话
response_b2 = graph.invoke(
{"messages": [{"role": "user", "content": "你知道我是谁吗?"}]},
config_user_b # 使用用户B的thread_id
)
# 机器人会回答知道用户B是谁记忆存储的选择
对于不同场景,LangGraph提供了三种存储选项:
# 选项1:内存存储(适合测试,重启后数据丢失)
from langgraph.checkpoint.memory import MemorySaver
memory_saver = MemorySaver()
# 选项2:SQLite存储(适合小型应用,数据存在本地文件中)
from langgraph.checkpoint.sqlite import SqliteSaver
sqlite_saver = SqliteSaver("chatbot.db") # 数据存在chatbot.db文件中
# 选项3:PostgreSQL存储(适合生产环境,数据存在数据库中)
from langgraph.checkpoint.postgres import PostgresSaver
postgres_saver = PostgresSaver(
connection_string="postgresql://username:password@localhost/dbname"
)完整例子:
import os
from typing import Annotated, List, Dict, Any
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
# 设置千问 API 密钥和基础 URL
os.environ["OPENAI_API_KEY"] = "sk-f80c"
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 创建千问模型实例
model = ChatOpenAI(
model="qwen-max", # 使用通义千问模型
temperature=0.7 # 添加适当的温度参数,平衡创新性和一致性
)
# 定义图的状态结构
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
# 创建记忆存储器(内存版本)
memory = MemorySaver()
# 定义聊天机器人处理函数
def chatbot(state: State) -> Dict[str, Any]:
"""处理用户消息并生成回复"""
# 获取当前的消息历史
messages = state["messages"]
# 使用千问模型生成回复
ai_message = model.invoke(messages)
# 返回更新后的消息列表
return {"messages": [ai_message]}
# 创建图构建器
graph_builder = StateGraph(State)
# 添加聊天机器人节点
graph_builder.add_node("chatbot", chatbot)
# 定义图的边
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 编译图并添加记忆功能
graph = graph_builder.compile(checkpointer=memory)
# 示例函数:与特定用户进行对话
def chat_with_user(user_id: str, message: str) -> str:
"""与指定用户ID的用户进行对话,并返回回复"""
# 创建配置,指定对话线程ID
config = {"configurable": {"thread_id": user_id}}
# 调用图进行对话
response = graph.invoke(
{"messages": [HumanMessage(content=message)]},
config
)
# 返回AI的回复内容
return response["messages"][-1].content
# 示例:如何使用
if __name__ == "__main__":
# 用户A的第一轮对话
response_a1 = chat_with_user("user_a", "你好,我叫张三")
print("用户A的对话1:")
print(f"用户A: 你好,我叫张三")
print(f"机器人: {response_a1}")
# 用户B的第一轮对话
response_b1 = chat_with_user("user_b", "你好,我叫李四")
print("\n用户B的对话1:")
print(f"用户B: 你好,我叫李四")
print(f"机器人: {response_b1}")
# 用户A的第二轮对话
response_a2 = chat_with_user("user_a", "你还记得我叫什么名字吗?")
print("\n用户A的对话2:")
print(f"用户A: 你还记得我叫什么名字吗?")
print(f"机器人: {response_a2}")
# 用户B的第二轮对话
response_b2 = chat_with_user("user_b", "你还记得我叫什么名字吗?")
print("\n用户B的对话2:")
print(f"用户B: 你还记得我叫什么名字吗?")
print(f"机器人: {response_b2}")输出:
用户A的对话1:
用户A: 你好,我叫张三
机器人: 你好,张三!很高兴认识你。有什么我可以帮助你的吗?
用户B的对话1:
用户B: 你好,我叫李四
机器人: 你好,李四!很高兴认识你。有什么我可以帮助你的吗?
用户A的对话2:
用户A: 你还记得我叫什么名字吗?
机器人: 你叫张三。如果还有其他问题或需要帮助的地方,尽管告诉我哦!
用户B的对话2:
用户B: 你还记得我叫什么名字吗?
机器人: 你叫李四。如果还有其他问题或需要帮助的地方,请告诉我!多用户支持:通过为每个用户分配唯一的 user_id,系统可以同时维护多个独立的对话。
任意轮对话:每次调用 chat_with_user 函数时,只要使用相同的 user_id,系统就会自动加载之前的对话历史。
扩展方法:
-
如果需要持久化存储对话历史,可以将
MemorySaver替换为SqliteSaver或PostgresSaver。 -
如果需要添加工具调用能力,可以使用
llm.bind_tools()和ToolNode。
实际应用:在实际应用中,你可能需要创建一个API或Web界面,将 chat_with_user 函数作为后端逻辑。
记忆管理:如果需要清除特定用户的记忆,可以实现一个函数从存储器中删除对应的线程ID。
编程秘籍 2
目标 == 可被分析过程,分析清楚即可被实现。
层层分解问题【核心】
-
-
将大问题分解为一系列小问题
-
人做事情的过程,确保每个小问题都有对应解决手段( 项目层->任务层->事件层->操作层 )
项目层,定义问题与愿望(完全不可操作)
任务层,设定具体目标与方向(不可操作)
事件层,详细描述任务的时空、交互与情景(部分可操作)
操作层,制定实际操作步骤与流程(完全可操作)
-
3.使用模块 4 问,介绍每个子模块(函数、对象)
-
为什么要导入这个库? 或者说,我要实现某个函数功能,AI 搜索是否有这样的官方库实现
-
这个模块是用来做什么的?(功能/作用)
-
这个模块最常用的方法有哪些?(常用方法)
-
这些方法的参数是什么?(参数说明)
4. 再把每个子模块,拆分为一步步的逻辑链
5. 每一步都提供对应的代码、行级注释、同步理论解说
这样你就能全流程精细分析和优化,出错能瞬间定位到精细部位上,实现快速 + 针对性改错
实践检测题(由易到难)
-
什么是 LangGraph 中的"状态"?它在图执行中扮演什么角色?
-
如何使用 TypedDict 定义一个包含用户问题和助手回答的状态结构?
-
描述节点更新状态的两种主要方式,并说明它们各自的优缺点。
-
编写一个节点函数,它只更新状态中的 "response" 字段。
-
如何创建一个节点,使其更新整个状态而不仅仅是部分字段?
三、节点间通信
掌握节点之间的通信机制,学习如何在 LangGraph 中传递数据和控制流。
基本通信模式
节点之间通过共享状态进行"通信",每个节点只需关注自己的处理逻辑。
一个节点对状态的更新会传递给下一个节点。
这就像是一个接力赛跑,每个选手(节点)接过接力棒(状态),做一些事情,然后传给下一个选手。
from typing import TypedDict
from langgraph.graph import StateGraph
class MessageState(TypedDict):
# 定义了一个包含两个字段的状态:content(消息内容)和processed(是否已处理)。
content: str
processed: bool
def node_A(state: MessageState) -> dict:
# 节点接收原始状态,修改content字段(添加"处理后的:"前缀),并将processed标记为True。
# 处理内容
processed_content = f"处理后的: {state['content']}"
# 更新状态
return {"content": processed_content, "processed": True}
def node_B(state: MessageState) -> dict:
# 节点检查processed标志 - 如果内容已处理,就在内容前添加"节点B回应:";如果未处理,则返回错误信息。
# 检查内容是否已处理
if state["processed"]:
# 使用处理后的内容
return {"content": f"节点B回应: {state['content']}"}
else:
# 内容未处理
return {"content": "需要先处理内容"}
# 创建图并连接节点
graph = StateGraph(MessageState)
graph.add_node("process", node_A)
graph.add_node("respond", node_B)
graph.set_entry_point("process")
graph.add_edge("process", "respond")通过参数传递额外信息
有时,你可能需要向节点传递额外的信息。
这可以通过在调用 invoke 时提供额外参数实现:
def enhanced_node(state: MessageState, config: dict) -> dict:
# state: 正常的状态对象,使用额外的配置参数 config: 额外的配置字典
template = config.get("template", "默认回复: {}")
# 如果没有提供模板,则使用"默认回复: {}"作为默认模板。
return {"content": template.format(state["content"])}
# 在编译时配置,所有调用都会使用这些参数
graph.add_node("enhanced", enhanced_node, config={"template": "定制回复: {}"})
# 这里在添加节点时提供了默认配置,这个配置会在每次调用该节点时使用,除非被覆盖。
# 或者在调用时传递
compiled_graph = graph.compile()
result = compiled_graph.invoke(
{"content": "测试消息", "processed": False},
config={"template": "调用时的模板: {}"}
# 在调用图时提供了特定的配置,它会覆盖添加节点时设置的默认配置。
# 当"enhanced"节点执行时,它使用的是调用时传递的配置,而不是添加节点时的默认配置
)输出:
初始状态: {"content": "测试消息", "processed": False}
调用时配置: {"template": "调用时的模板: {}"}
节点运行后,返回: {"content": "调用时的模板: 测试消息"}这种机制非常有用,因为它允许:
-
设置一致的默认行为(添加节点时的配置)
-
在需要时灵活覆盖这些默认值(调用时的配置)
这样你可以在不修改节点代码的情况下,让同一个节点在不同情况下有不同的行为,大大提高了代码的灵活性和可重用性。
条件通信
在某些情况下,你可能希望根据状态内容决定数据的流向。
这就像是一个交通指挥员,根据情况决定数据应该走哪条路。
条件路由让你的应用能够做出智能决策,处理各种不同的情况。
from typing import TypedDict, Literal
from langgraph.graph import StateGraph
class RoutingState(TypedDict):
content: str
sentiment: Literal["positive", "negative", "neutral"]
response: str
def analyze_sentiment(state: RoutingState) -> dict:
# 简单情感分析(实际应用中可能使用NLP模型)
text = state["content"].lower()
if "好" in text or "喜欢" in text:
return {"sentiment": "positive"}
elif "不" in text or "讨厌" in text:
return {"sentiment": "negative"}
else:
return {"sentiment": "neutral"}
def positive_response(state: RoutingState) -> dict:
return {"response": "我很高兴听到您的积极反馈!"}
def negative_response(state: RoutingState) -> dict:
return {"response": "我很抱歉听到您的负面体验,我们会努力改进。"}
def neutral_response(state: RoutingState) -> dict:
return {"response": "感谢您的反馈。"}
# 创建图
graph = StateGraph(RoutingState)
# 添加节点
graph.add_node("analyze", analyze_sentiment)
graph.add_node("positive", positive_response)
graph.add_node("negative", negative_response)
graph.add_node("neutral", neutral_response)
# 设置入口点
graph.set_entry_point("analyze")
# 定义条件路由
def router(state: RoutingState):
return state["sentiment"]
# 添加条件边
graph.add_conditional_edges(
"analyze",
router,
{
"positive": "positive",
"negative": "negative",
"neutral": "neutral"
}
)实践检测(由易到难)
-
节点间通信的主要方式是什么?简单描述这一机制。
-
如何让一个节点能够接收额外的配置参数?
-
编写一个简单的节点函数,它检查状态中的"validated"字段,并根据结果返回不同的消息。
-
在 LangGraph 中,如何向节点传递运行时配置?
-
什么是条件路由?它解决了什么问题?
-
编写一个简单的路由函数,根据输入消息的长度将其分类为"短"、"中"或"长"。
-
使用
add_conditional_edges方法,创建一个基于消息类型进行路由的图结构。 -
设计一个使用中间节点进行数据转换的简单系统,包括数据验证。
-
如何确保节点按正确的顺序处理数据?描述一种防止数据未经预处理就被处理的策略。
-
设计一个完整的对话系统,使用条件边根据用户意图(问候、查询、投诉)路由到不同的处理节点。
四、条件分支和循环
条件分支和循环模块是 LangGraph 中用于控制数据流向的核心功能,它们让你的图不再是简单的线性流程,而是能够:
-
根据不同条件选择不同处理路径(条件分支)
-
重复执行某些操作直到满足特定条件(循环)
-
构建能够自我迭代改进的系统(自我改进)
条件分支
条件分支是构建智能系统的基础,它让你的应用能够做出决策。
创建条件分支,最基本的条件分支包含三个部分:
-
一个源节点
-
一个路由函数
-
多个可能的目标节点
想象你在开发一个客服机器人,它需要根据用户的意图提供不同的服务:
-
问候 → 回复欢迎信息
-
产品问题 → 查询产品数据库
-
售后服务 → 连接到服务系统
条件分支让这种智能路由成为可能。
from typing import TypedDict, Literal
from langgraph.graph import StateGraph
# 定义状态
class QueryState(TypedDict):
query: str
query_type: Literal["greeting", "question", "command"]
response: str
# 路由函数
def query_router(state: QueryState) -> str:
"""根据查询类型路由到不同节点"""
return state["query_type"] # 返回字符串作为路由决策
# 处理节点
def handle_greeting(state: QueryState) -> dict:
return {"response": "你好!有什么我可以帮助你的?"}
def handle_question(state: QueryState) -> dict:
return {"response": f"对于问题 '{state['query']}',我的回答是..."}
def handle_command(state: QueryState) -> dict:
return {"response": f"正在执行命令: {state['query']}"}
# 创建图
graph = StateGraph(QueryState)
# 添加节点
graph.add_node("greeting_handler", handle_greeting)
graph.add_node("question_handler", handle_question)
graph.add_node("command_handler", handle_command)
# 添加条件边
graph.add_conditional_edges(
"query_classifier", # 源节点
query_router, # 路由函数
{
"greeting": "greeting_handler", # 如果返回"greeting",回复欢迎信息
"question": "question_handler", # 如果返回"question",查询产品数据库
"command": "command_handler" # 如果返回"command",连接到服务系统
}
)循环结构
想象你在做一道菜:
-
你先准备好原料(初始数据)
-
然后你开始烹饪(处理数据)
-
每隔几分钟,你尝一尝味道(检查完成条件)
-
如果味道不够好,你继续烹饪(继续循环)
-
如果味道满意了,你停止烹饪(结束循环)
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
# 定义状态结构
class IterativeState(TypedDict):
iterations: int # 记录已经迭代了多少次
max_iterations: int # 最多允许迭代多少次
data: List[float] # 要处理的数据
result: float # 处理结果
# 处理数据的函数
def process_data(state: IterativeState) -> dict:
"""处理一轮数据"""
current_data = state["data"]
# 简单示例:每轮将所有数据乘以0.9
new_data = [x * 0.9 for x in current_data]
# 计算新的结果(例如平均值)
new_result = sum(new_data) / len(new_data)
# 增加迭代计数
new_iterations = state["iterations"] + 1
# 返回更新后的状态
return {
"data": new_data,
"result": new_result,
"iterations": new_iterations
}
# 检查是否完成迭代的函数
def check_completion(state: IterativeState) -> str:
# 如果已达到最大迭代次数,返回"complete"
if state["iterations"] >= state["max_iterations"]:
return "complete"
else: # 否则返回"continue"
return "continue"
# 创建图
graph = StateGraph(IterativeState)
graph.add_node("process", process_data)
# 设置入口点
graph.set_entry_point("process")
# 添加条件边实现循环
graph.add_conditional_edges(
"process", # 源节点
check_completion, # 使用check_completion函数检查是否继续循环
{
"continue": "process", # 如果返回"continue",继续循环
"complete": END # 如果返回"complete",结束执行
}
)实践检测题(由易到难)
-
在 LangGraph 中,如何实现一个简单的条件分支?
-
什么是复杂路由?它与简单条件分支有何不同?
-
如何在 LangGraph 中创建一个基于多个条件的路由函数?
-
在 LangGraph 中,如何实现一个简单的循环结构?
-
设计一个迭代计算图,计算斐波那契数列的前 N 项。
-
什么情况下你会选择使用循环而不是简单的顺序执行?
-
自我改进系统的核心组件有哪些?它们如何协同工作?
-
设计一个自我改进的文本摘要系统,能够生成初步摘要,评价其质量,并进行多轮改进。
-
如何防止循环结构中的无限循环?讨论几种可能的策略。
-
创建一个复杂的对话系统,结合条件分支和循环,能够处理多轮对话,并在需要时优化其回复。
五、与外部工具集成
调用 Qwen
# 导入必要的库
from openai import OpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, List, Dict, Any
# 创建千问API客户端
def create_qwen_client(api_key):
return OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 调用千问API生成回复
def generate_with_qwen(client, prompt, model_name="qwen-max", temperature=0.7):
try:
# 创建消息格式
messages = [{"role": "user", "content": prompt}]
# 调用API
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature
)
# 返回生成的内容
return response.choices[0].message.content
except Exception as e:
print(f"调用千问API时发生错误: {str(e)}")
return "发生错误,请稍后再试。"
# 创建千问客户端
client = create_qwen_client(api_key="sk-.....")
# 定义状态类型
class ChatState(TypedDict):
messages: List
# 定义节点函数
def call_model(state: ChatState) -> Dict[str, Any]:
# 获取消息列表
messages = state["messages"]
# 获取最后一条消息的内容
prompt = messages[-1].content
# 调用千问生成回复
response = generate_with_qwen(client, prompt)
# 返回更新后的状态
return {"messages": messages + [AIMessage(content=response)]}
# 创建状态图
workflow = StateGraph(ChatState)
# 添加节点
workflow.add_node("call_model", call_model)
# 添加边,定义流程
workflow.add_edge(START, "call_model")
workflow.add_edge("call_model", END)
# 编译图
chain = workflow.compile()
# 创建初始状态并调用
messages = [HumanMessage(content="介绍一下LangGraph的主要特点")]
result = chain.invoke({"messages": messages})
print(result)输出:
{'messages':
[HumanMessage(content='介绍一下LangGraph的主要特点', additional_kwargs={}, response_metadata={}),
AIMessage(content='LangGraph是阿里巴巴推出的一种多模态预训练模型,它在处理语言和图像信息方面具有显著的优势。以下是LangGraph的一些主要特点:\n\n1. **多模态融合能力**:LangGraph能够同时理解和处理文本与图像信息,实现跨模态的信息理解与生成。这意味着它可以基于给有的文字描述生成相应的图片,或者根据提供的图片生成相关的文字说明。\n\n2. **强大的预训练基础**:通过大规模的数据集进行预训练,使得LangGraph具备了广泛的知识背景,能够更好地适应各种应用场景下的需求。这种广泛的预训练不仅限于中文或英文单一语种,而是覆盖了多种语言,增强了其在全球范围内的适用性。\n\n3. **高效灵活的应用接口**:为了方便开发者使用,LangGraph提供了易于集成的API接口。这些接口允许用户轻松地将该模型应用于自己的项目中,无论是网页应用、移动应用程序还是其他类型的软件开发,都能够快速接入并利用到LangGraph的强大功能。\n\n4. **支持多样化任务场景**:除了基本的文字生成图片、图片识别文字等功能外,LangGraph还支持更复杂的任务如视觉问答(VQA)、图像标题生成等。这使得它能够在多个领域发挥作用,比如教育、娱乐、广告创意设计等领域都有潜在的应用价值。\n\n5. **持续迭代优化**:作为一款前沿的技术产品,阿里巴巴团队会不断地对LangGraph进行更新和改进,以确保其性能始终保持领先,并且能够满足市场上日益增长的需求变化和技术挑战。\n\n总之,LangGraph以其独特的多模态处理能力和丰富的应用场景,为用户提供了一个强大而灵活的工具,有助于推动人工智能技术在更多领域的创新发展。请注意,具体功能可能会随着版本更新而有所调整,请参考官方文档获取最新信息。', additional_kwargs={}, response_metadata={})]}编排多个语言模型
如根据医学指南,生成建议:
-
第一个模型 (qwen-turbo) - 提供快速、简洁的基本回答
-
第二个模型 (qwen-plus) - 基于第一个模型的回答提供补充信息
-
第三个模型 (qwen-max) - 作为评审者,检查前两个模型的回答,纠正错误,并提供最终整合的回答
# 导入必要的库
from openai import OpenAI
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, List, Dict, Any
# 创建千问API客户端
def create_qwen_client(api_key):
"""创建千问API客户端"""
return OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 调用千问API生成回复
def generate_with_qwen(client, messages, model_name, temperature=0.7):
try:
# 转换消息格式
api_messages = []
for message in messages:
if isinstance(message, dict):
api_messages.append(message)
else:
role = "system" if message.type == "system" else ("assistant" if message.type == "ai" else "user")
api_messages.append({"role": role, "content": message.content})
# 调用API
response = client.chat.completions.create(
model=model_name,
messages=api_messages,
temperature=temperature
)
# 返回生成的内容
return response.choices[0].message.content
except Exception as e:
print(f"调用千问API时发生错误: {str(e)}")
return "发生错误,请稍后再试。"
# 创建千问客户端
client = create_qwen_client(api_key="sk-f80c7ef16508....") # 替换为你的实际密钥
# 定义状态类型
class ChatState(TypedDict):
messages: List # 用户消息
answer: str # 第一个模型的回答
supplement: str # 第二个模型的补充
final_answer: str # 第三个模型的检查结果
# 定义第一个模型节点 - 提供基本回答
def first_model(state: ChatState) -> Dict[str, Any]:
"""使用第一个模型(qwen-turbo)生成基本回答"""
messages = state["messages"]
# 创建系统提示,指导模型提供基本回答
system_message = SystemMessage(content="你是一个助手,请提供对问题的基本回答。保持简洁明了。")
# 组合消息
prompt_messages = [system_message] + messages
# 调用千问turbo模型
response = generate_with_qwen(client, prompt_messages, "qwen-turbo")
# 返回更新后的状态
return {"answer": response}
# 定义第二个模型节点 - 提供补充信息
def second_model(state: ChatState) -> Dict[str, Any]:
"""使用第二个模型(qwen-plus)补充信息"""
messages = state["messages"]
answer = state["answer"]
# 创建系统提示,指导模型补充信息
system_message = SystemMessage(content=f"""
你是一个信息补充专家。以下是用户的问题以及已有的基本回答:
已有回答: {answer}
请补充更多相关信息、例子或细节,使回答更加完整。不要重复已有内容。
""")
# 组合消息
prompt_messages = [system_message] + messages
# 调用千问plus模型
response = generate_with_qwen(client, prompt_messages, "qwen-plus")
# 返回更新后的状态
return {"supplement": response}
# 定义第三个模型节点 - 检查和合并
def third_model(state: ChatState) -> Dict[str, Any]:
"""使用第三个模型(qwen-max)检查并整合前两个模型的回答"""
messages = state["messages"]
answer = state["answer"]
supplement = state["supplement"]
# 创建系统提示,指导模型进行检查和整合
system_message = SystemMessage(content=f"""
你是一个质量检查专家。以下是用户的问题、基本回答和补充信息:
基本回答: {answer}
补充信息: {supplement}
请完成以下任务:
1. 检查基本回答和补充信息的准确性
2. 纠正任何错误或不准确的信息
3. 整合两部分内容,确保逻辑连贯
4. 确保最终回答全面、准确且易于理解
请提供最终的完整回答。
""")
# 组合消息
prompt_messages = [system_message] + messages
# 调用千问max模型
response = generate_with_qwen(client, prompt_messages, "qwen-max")
# 返回更新后的状态,包括最终回答和AI消息
return {
"final_answer": response,
"messages": messages + [AIMessage(content=response)]
}
# 创建状态图
workflow = StateGraph(ChatState)
# 添加节点
workflow.add_node("first_model", first_model)
workflow.add_node("second_model", second_model)
workflow.add_node("third_model", third_model)
# 添加边,定义顺序流程
workflow.add_edge(START, "first_model")
workflow.add_edge("first_model", "second_model")
workflow.add_edge("second_model", "third_model")
workflow.add_edge("third_model", END)
# 编译图
chain = workflow.compile()
# 创建初始状态并调用
initial_state = {
"messages": [HumanMessage(content="什么是LangGraph以及它的主要特点?")],
"answer": "",
"supplement": "",
"final_answer": ""
}
# 运行工作流
result = chain.invoke(initial_state)
# 打印结果
print("=== 第一个模型的基本回答 ===")
print(result["answer"])
print("\n=== 第二个模型的补充信息 ===")
print(result["supplement"])
print("\n=== 第三个模型的最终回答 ===")
print(result["final_answer"])输出:(等了很久,大概几分钟)
=== 第一个模型的基本回答 ===
LangGraph 是一种基于图结构的语言表示方法,主要用于自然语言处理和语义分析任务。其主要特点是将语言中的词汇、短语或句子以节点的形式表示,并通过边来连接具有语义关系的元素,从而形成一个图结构。这种表示方式能够更好地捕捉语言中的复杂语义关联。
### 主要特点:
1. **图结构建模**:利用图论的方法建模语言数据,可以灵活表达复杂的语义关系。
2. **语义丰富性**:能够更直观地表示词汇之间的同义、反义、上下位等语义关系。
3. **可扩展性**:适合处理大规模文本数据,支持多种语言任务(如问答、文本生成等)。
4. **动态性**:可以根据不同应用场景调整图的构建规则和特征。
总之,LangGraph 提供了一种强大的工具来建模语言的语义网络,适用于需要深入理解语言内在关系的任务。
=== 第二个模型的补充信息 ===
LangGraph 是一种创新的语言表示方法,通过将自然语言中的词汇、短语和句子建模为图结构(graph structure),从而更好地捕捉语言中的复杂语义关系。它结合了图论与自然语言处理技术的优势,为解决多种语言任务提供了强大的工具支持。
### 补充信息及特点:
#### 1. **多模态融合能力**
LangGraph 不仅可以用于纯文本数据的建模,还能够与其他模态(如图像、音频)的数据进行融合。例如,在视觉问答(Visual Question Answering, VQA)任务中,可以通过构建联合图结构来同时表示文本和图像中的信息,从而更准确地理解问题和场景之间的关联。
#### 2. **动态知识图谱集成**
在实际应用中,LangGraph 可以与现有的知识图谱(Knowledge Graphs)相结合。通过引入外部知识(如维基百科或Freebase中的实体关系),LangGraph 能够增强对文本的理解能力。例如,在命名实体识别(NER)任务中,LangGraph 可以利用知识图谱中的实体类型和关系来提高识别精度。
#### 3. **上下文敏感性**
传统词嵌入方法(如Word2Vec或GloVe)通常无法区分同一词语在不同上下文中的含义,而LangGraph 通过节点和边的动态调整,能够灵活地捕捉词语在具体语境中的意义。例如,在句子“*银行是河流的一部分*”和“*银行提供贷款服务*”中,“银行”具有完全不同的含义,LangGraph 可以通过图结构中的上下文依赖关系区分这些差异。
#### 4. **高效推理机制**
LangGraph 支持基于图的推理算法(如随机游走、图卷积网络GCN等),这使得模型能够在复杂的语义网络中进行高效推理。例如,在逻辑推理任务中,LangGraph 可以通过分析句子间的因果关系或条件关系,推导出隐含的信息。
#### 5. **实际应用场景**
- **机器翻译**:通过构建源语言和目标语言之间的映射图,LangGraph 可以帮助捕捉两种语言之间的深层语义对应关系。
- **情感分析**:通过对句子中的情感词汇及其关系进行建模,LangGraph 能够更精确地判断文本的情感倾向。
- **对话系统**:在多轮对话中,LangGraph 可以跟踪历史对话内容并建立长期记忆图,从而生成更加连贯和自然的回复。
#### 6. **技术实现细节**
- **图的构建方式**:LangGraph 的图结构通常由句法分析器(如依存句法树)或语义角色标注工具生成。节点可以代表单词、短语甚至整个句子,而边则表示它们之间的语法或语义关系。
- **特征表示**:每个节点和边都可以附带丰富的特征向量,这些特征可能来源于预训练的语言模型(如BERT)、词嵌入或其他特征提取方法。
- **优化方法**:为了提升性能,LangGraph 常常与深度学习框架结合使用,例如通过图神经网络(Graph Neural Networks, GNNs)对图结构进行端到端训练。
#### 示例:
假设我们有一段文本:“猫喜欢追着老鼠跑。”
- 在LangGraph 中,这句话可以被建模为一个图,其中“猫”、“喜欢”、“追着”、“老鼠”和“跑”作为节点。
- 边可以表示它们之间的关系,例如:
- “猫” → “喜欢”(主谓关系)
- “喜欢” → “追着”(动宾关系)
- “追着” → “老鼠”(宾语关系)
- “老鼠” → “跑”(伴随动作关系)
这种图结构不仅清晰地展示了句子的语法结构,还蕴含了潜在的语义信息,比如“猫”和“老鼠”之间存在捕食关系。
### 总结
LangGraph 是一种功能强大且灵活的语言建模方法,特别适合需要深入理解语言内在关系的任务。通过其独特的图结构设计,LangGraph 能够整合多模态信息、外部知识以及上下文依赖关系,为自然语言处理领域带来了新的研究方向和实践可能性。
=== 第三个模型的最终回答 ===
LangGraph 是一种基于图结构的语言表示方法,主要用于自然语言处理和语义分析任务。它通过将自然语言中的词汇、短语或句子以节点的形式表示,并通过边来连接具有语义关系的元素,从而形成一个图结构。这种表示方式能够更好地捕捉语言中的复杂语义关联。
### 主要特点:
1. **图结构建模**:
- 利用图论的方法建模语言数据,可以灵活表达复杂的语义关系。
- 通过句法分析器(如依存句法树)或语义角色标注工具生成图结构,节点代表单词、短语或句子,边表示它们之间的语法或语义关系。
2. **语义丰富性**:
- 能够更直观地表示词汇之间的同义、反义、上下位等语义关系。
- 每个节点和边都可以附带丰富的特征向量,这些特征可能来源于预训练的语言模型(如BERT)、词嵌入或其他特征提取方法。
3. **可扩展性**:
- 适合处理大规模文本数据,支持多种语言任务(如问答、文本生成等)。
- 可以与其他模态(如图像、音频)的数据进行融合,例如在视觉问答(VQA)任务中,构建联合图结构来同时表示文本和图像中的信息。
4. **动态性**:
- 可以根据不同应用场景调整图的构建规则和特征。
- 通过节点和边的动态调整,能够灵活地捕捉词语在具体语境中的意义,解决传统词嵌入方法无法区分同一词语在不同上下文中的含义的问题。
5. **动态知识图谱集成**:
- 可以与现有的知识图谱(如维基百科或Freebase中的实体关系)相结合,增强对文本的理解能力。
- 在命名实体识别(NER)任务中,利用知识图谱中的实体类型和关系来提高识别精度。
6. **高效推理机制**:
- 支持基于图的推理算法(如随机游走、图卷积网络GCN等),在复杂的语义网络中进行高效推理。
- 例如,在逻辑推理任务中,通过分析句子间的因果关系或条件关系,推导出隐含的信息。
7. **实际应用场景**:
- **机器翻译**:通过构建源语言和目标语言之间的映射图,帮助捕捉两种语言之间的深层语义对应关系。
- **情感分析**:通过对句子中的情感词汇及其关系进行建模,更精确地判断文本的情感倾向。
- **对话系统**:在多轮对话中,跟踪历史对话内容并建立长期记忆图,生成更加连贯和自然的回复。
#### 示例:
假设我们有一段文本:“猫喜欢追着老鼠跑。”
- 在LangGraph 中,这句话可以被建模为一个图,其中“猫”、“喜欢”、“追着”、“老鼠”和“跑”作为节点。
- 边可以表示它们之间的关系,例如:
- “猫” → “喜欢”(主谓关系)
- “喜欢” → “追着”(动宾关系)
- “追着” → “老鼠”(宾语关系)
- “老鼠” → “跑”(伴随动作关系)
这种图结构不仅清晰地展示了句子的语法结构,还蕴含了潜在的语义信息,比如“猫”和“老鼠”之间存在捕食关系。
### 总结
LangGraph 是一种功能强大且灵活的语言建模方法,特别适合需要深入理解语言内在关系的任务。通过其独特的图结构设计,LangGraph 能够整合多模态信息、外部知识以及上下文依赖关系,为自然语言处理领域带来了新的研究方向和实践可能性。六、高级图控制
并行执行 - 让多个任务同时进行,提高效率
在LangGraph中,通常任务是按顺序执行的:A完成后才开始B,B完成后才开始C。
但有了并行执行,A完成后,B和C可以同时开始。
-
分解任务:把大任务拆分成小任务(地图/Map)
-
并行处理:同时处理所有小任务
-
合并结果:把所有小任务的结果合并起来(归约/Reduce)
模块三问:Send API
这个模块是用来做什么的?(功能/作用)
Send API 是 LangGraph 中用于实现并行处理的核心工具。
它允许你将一个任务分解成多个小任务,然后将这些小任务同时发送到同一个处理节点的多个实例上。
这样,每个实例可以独立处理一部分数据,最后再将结果合并起来。
简单来说,Send 让你的 AI 应用能够"一次做多件事",而不是一件一件顺序处理。
这个模块最常用的方法有哪些?(常用方法)
Send 类主要用于创建发送指令,常见用法包括:
-
创建 Send 对象:
Send(node_name, state) # `node_name`:字符串,指定要发送数据的目标节点名称 # `state`:字典,包含要发送给目标节点的数据(这个数据可以与主图的状态结构完全不同)2. 在条件边中使用:
def map_to_nodes(state):
# 函数作用:将状态中的每个项目映射到处理节点,实现并行处理
# 输入参数state是当前图的状态,包含items列表
# 返回一个Send对象列表,每个对象指向process_node节点但携带不同的item数据
return [Send("process_node", {"item": item}) for item in state["items"]]
# 这行代码使用列表推导式,对state["items"]中的每个item创建一个Send对象
# Send对象包含两个参数:目标节点名称"process_node"和要发送的状态数据{"item": item}
# 这样可以让同一个节点的多个实例并行处理不同的数据项
graph.add_conditional_edges("start_node", map_to_nodes, ["process_node"])
# 这行代码向图中添加条件边,连接"start_node"和"process_node"
# 第一个参数"start_node"是源节点,表示边的起点
# 第二个参数map_to_nodes是条件函数,它决定如何从源节点分发数据到目标节点
# 第三个参数["process_node"]是可能的目标节点列表,这里只有一个目标节点
# 当图执行到"start_node"后,会调用map_to_nodes函数,根据返回的Send对象列表创建多个并行任务步骤 1:定义主状态和子任务状态
# 主状态包含所有数据
class MainState(TypedDict):
items: List[str] # 需要处理的项目列表
results: Annotated[List[str], operator.add] # 用 add 操作符合并所有结果
# 子任务状态只包含单个项目
class ItemState(TypedDict):
item: str # 单个需要处理的项目步骤 2:创建映射函数(这是实现并行的核心)
# 映射函数:将列表中的每个项目分发到处理节点
def map_to_items(state: MainState):
# 为每个项目创建一个 Send 对象
# 每个 Send 对象都指向 "process_item" 节点,但携带不同的项目数据
return [Send("process_item", {"item": item}) for item in state["items"]]步骤 3:定义处理节点的函数
# 主列表生成函数
def generate_items(state: MainState):
# 生成或获取项目列表
items = ["项目1", "项目2", "项目3"]
return {"items": items}
# 单个项目处理函数
def process_item(state: ItemState):
# 处理单个项目
result = f"处理结果: {state['item']}"
return {"results": [result]} # 注意返回列表,便于后续合并
# 结果汇总函数
def summarize_results(state: MainState):
# 对所有处理结果进行汇总或选择
summary = "最终结果基于: " + ", ".join(state["results"])
return {"summary": summary}完整代码:
# 导入必要的库
import os # 导入os模块以设置环境变量
from typing import Annotated, List # 导入类型注解工具
from typing_extensions import TypedDict # 导入TypedDict用于定义状态结构
import operator # 导入operator用于定义合并操作
from langchain_openai import ChatOpenAI # 导入ChatOpenAI(将使用千问配置)
from langgraph.types import Send # 导入Send类,用于实现并行处理
from langgraph.graph import END, StateGraph, START # 导入图的基本组件
from pydantic import BaseModel # 导入Pydantic模型用于结构化输出
# 设置千问 API 环境变量
os.environ["OPENAI_API_KEY"] = "sk-f80c7...." # 设置API密钥
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1" # 设置API基础URL
# 初始化千问语言模型
model = ChatOpenAI(model="qwen-max", temperature=0.7) # 创建一个千问模型实例
# 定义结构化数据模型
class CategoryItems(BaseModel): # 定义类别物品的结构
items: List[str] # 物品列表字段
class BestDeal(BaseModel): # 定义最佳交易的结构
item_id: int # 最佳物品的ID
# 定义图的主状态结构
class ShoppingState(TypedDict): # 定义购物状态的结构
categories: List[str] # 购物类别列表
items: Annotated[List[str], operator.add] # 物品列表,使用operator.add合并并行节点的结果
best_deal: str # 最佳优惠物品
# 定义单个类别处理的状态结构
class CategoryState(TypedDict): # 定义单个类别处理的状态
category: str # 类别名称
# 生成购物类别的函数
def generate_categories(state: ShoppingState): # 生成购物类别的函数
prompt = f"列出3个常见的购物类别(如食品、日用品等),请只返回类别名称,用逗号分隔" # 创建提示文本
response = model.invoke(prompt) # 调用模型获取回复
# 解析响应,假设返回逗号分隔的类别
categories = [cat.strip() for cat in response.content.split(',')] # 处理响应,分割成类别列表
return {"categories": categories} # 返回类别列表结果
# 查找单个类别下商品的函数
def find_category_items(state: CategoryState): # 查找特定类别商品的函数
prompt = f"推荐2个{state['category']}类别下的具体商品,请只返回商品名称,用逗号分隔" # 创建针对特定类别的提示
response = model.invoke(prompt) # 调用模型获取商品推荐
# 解析响应,假设返回逗号分隔的商品
items = [item.strip() for item in response.content.split(',')] # 处理响应,分割成商品列表
return {"items": items} # 返回该类别的商品列表
# 找出最佳优惠的函数
def find_best_deal(state: ShoppingState): # 找出最佳优惠商品的函数
# 创建带编号的商品列表文本
items_list = "\n".join([f"{i}: {item}" for i, item in enumerate(state["items"])]) # 生成带编号的商品列表
prompt = f"从以下商品中选出最值得购买的一个,请只返回商品的编号(0到{len(state['items'])-1}):\n{items_list}" # 创建选择最佳商品的提示
response = model.invoke(prompt) # 调用模型获取最佳选择
# 解析响应,尝试获取商品编号
try:
# 提取数字,处理可能的文本回复
for word in response.content.split():
if word.isdigit():
best_id = int(word)
if 0 <= best_id < len(state["items"]): # 检查编号是否有效
return {"best_deal": state["items"][best_id]} # 返回对应的最佳商品
return {"best_deal": state["items"][0]} # 未找到有效编号时返回第一个商品
except:
return {"best_deal": state["items"][0]} # 解析失败时返回第一个商品作为默认值
# 地图函数 - 将类别映射到处理节点(并行处理的核心)
def map_to_categories(state: ShoppingState): # 创建并行处理映射的函数
# 这是并行处理的关键:为每个类别创建一个Send对象
# 每个Send对象都指向"find_items"节点,但携带不同的类别数据
return [Send("find_items", {"category": category}) for category in state["categories"]] # 为每个类别创建Send对象
# 创建图结构
graph = StateGraph(ShoppingState) # 使用ShoppingState创建图
graph.add_node("generate_categories", generate_categories) # 添加生成类别的节点
graph.add_node("find_items", find_category_items) # 添加查找商品的节点
graph.add_node("find_best_deal", find_best_deal) # 添加查找最佳优惠的节点
# 添加边连接节点
graph.add_edge(START, "generate_categories") # 从开始到生成类别节点
graph.add_conditional_edges("generate_categories", map_to_categories, ["find_items"]) # 添加条件边,使用map_to_categories函数将类别分发到多个find_items节点实例
graph.add_edge("find_items", "find_best_deal") # 从查找商品到查找最佳优惠
graph.add_edge("find_best_deal", END) # 从查找最佳优惠到结束
# 编译图
app = graph.compile() # 编译图,生成可执行的应用
# 执行图的函数
def run_shopping_assistant(): # 运行购物助手的函数
print("启动购物助手...") # 打印启动消息
results = [] # 初始化结果列表
# 流式处理图的执行步骤
for step in app.stream({}): # 使用空状态开始执行图
results.append(step) # 保存每个步骤的结果
print(step) # 打印每个步骤的结果
# 打印最终总结
print("\n购物总结:") # 打印总结标题
if results: # 如果有结果
all_items = [] # 存储所有商品的列表
best_deal = None # 存储最佳优惠商品
# 提取所有商品和最佳优惠
for step in results:
for node, data in step.items():
if node == "find_items" and "items" in data:
all_items.extend(data["items"]) # 收集所有商品
if node == "find_best_deal" and "best_deal" in data:
best_deal = data["best_deal"] # 获取最佳优惠
# 打印结果
if all_items:
print(f"所有推荐商品: {', '.join(all_items)}") # 打印所有推荐商品
if best_deal:
print(f"最佳优惠商品: {best_deal}") # 打印最佳优惠商品
# 运行购物助手
if __name__ == "__main__": # 如果直接运行此脚本
run_shopping_assistant() # 调用购物助手函数输出:
启动购物助手...
{'generate_categories': {'categories': ['食品', '日用品', '电子产品']}}
{'find_items': {'items': ['牛奶', '巧克力']}}
{'find_items': {'items': ['电动牙刷', '洗衣凝珠']}}
{'find_items': {'items': ['Apple iPhone 15', 'Sony WH-1000XM5']}}
{'find_best_deal': {'best_deal': 'Apple iPhone 15'}}
购物总结:
所有推荐商品: 牛奶, 巧克力, 电动牙刷, 洗衣凝珠, Apple iPhone 15, Sony WH-1000XM5
最佳优惠商品: Apple iPhone 15递归控制 - 调用自己,处理嵌套问题:自我修正的RAG系统
展示一个自我修正的RAG系统,TA 会检查生成的答案质量,如果不满意,会重新检索和生成,直到得到满意的结果或达到递归限制。
# 定义决策函数,决定流程的下一步走向
def decide_next_step(state):
# 检查迭代次数是否达到上限(3次),如果达到则结束流程
if state["iterations"] >= 3: # 限制递归次数
return END
# 检查文档是否相关,如果不相关则需要重写查询
if not state["is_relevant"]: # 文档不相关时重写查询
return "rewrite_query"
# 如果以上条件都不满足(文档相关且未达到迭代上限),仍然结束流程
return END # 文档相关时结束流程
# 添加条件边,将check_quality节点连接到不同的目标节点
# 根据decide_next_step函数的返回值决定下一步去向
graph.add_conditional_edges("check_quality", decide_next_step,
{"rewrite_query": "rewrite_query", END: END})
# 添加从rewrite_query节点到retrieve节点的边,形成循环
# 这使得系统可以多次迭代:检查→重写→检索→检查...
graph.add_edge("rewrite_query", "retrieve") # 形成循环-
每次相似度评估,是设计的随机真或假(教学演示)
from typing import List, Literal
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.errors import GraphRecursionError # 正确导入错误类
# 定义RAG状态
class RAGState(TypedDict):
question: str # 用户问题
documents: List[str] # 检索到的文档
generation: str # 生成的答案
query: str # 检索查询
is_relevant: bool # 文档是否相关
is_hallucination: bool # 答案是否存在幻觉
is_useful: bool # 答案是否有用
iterations: int # 跟踪迭代次数,用于限制递归
# 检索文档的节点
def retrieve(state: RAGState):
"""根据查询检索文档"""
# 在实际应用中,这会调用向量数据库进行检索
query = state.get("query", state["question"])
print(f"检索:'{query}'")
# 模拟检索结果
docs = [f"关于'{query}'的文档1", f"关于'{query}'的文档2"]
iterations = state.get("iterations", 0) + 1
return {"documents": docs, "query": query, "iterations": iterations}
# 评估文档相关性的节点
def grade_documents(state: RAGState):
"""评估检索到的文档是否相关"""
print(f"评估文档相关性")
import random
is_relevant = random.choice([True, False]) # 随机决定是否相关
return {"is_relevant": is_relevant}
# 生成答案的节点
def generate(state: RAGState):
"""根据文档生成答案"""
question = state["question"]
print(f"生成答案")
answer = f"基于检索到的文档,对于问题'{question}'的回答是..."
return {"generation": answer}
# 检查答案质量的节点
def check_quality(state: RAGState):
"""检查生成的答案是否存在幻觉,是否有用"""
print(f"检查答案质量")
import random
is_hallucination = False # 假设没有幻觉
is_useful = random.choice([True, False]) # 随机决定是否有用
return {
"is_hallucination": is_hallucination,
"is_useful": is_useful
}
# 重写查询的节点
def rewrite_query(state: RAGState):
"""重写查询以获得更好的检索结果"""
question = state["question"]
print(f"重写查询")
new_query = f"详细信息: {question}"
return {"query": new_query}
# 定义路由函数
def decide_next_step(state: RAGState) -> Literal["rewrite_query", "END"]:
"""决定下一步操作"""
# 添加迭代次数限制,防止无限循环
if state.get("iterations", 0) >= 3:
print("达到最大迭代次数,结束流程")
return END
# 如果文档不相关,重写查询并重新检索
if not state.get("is_relevant", False):
print("文档不相关,重写查询")
return "rewrite_query"
# 如果存在幻觉,重写查询并重新检索
if state.get("is_hallucination", False):
print("答案存在幻觉,重写查询")
return "rewrite_query"
# 如果答案不够有用,重写查询并重新检索
if not state.get("is_useful", False):
print("答案不够有用,重写查询")
return "rewrite_query"
# 一切正常,结束流程
print("答案质量良好,完成")
return END
# 创建图
rag_graph = StateGraph(RAGState)
# 添加节点
rag_graph.add_node("retrieve", retrieve)
rag_graph.add_node("grade_documents", grade_documents)
rag_graph.add_node("generate", generate)
rag_graph.add_node("check_quality", check_quality)
rag_graph.add_node("rewrite_query", rewrite_query)
# 添加边
rag_graph.add_edge(START, "retrieve")
rag_graph.add_edge("retrieve", "grade_documents")
rag_graph.add_edge("grade_documents", "generate")
rag_graph.add_edge("generate", "check_quality")
rag_graph.add_conditional_edges("check_quality", decide_next_step, {
"rewrite_query": "rewrite_query",
END: END
})
rag_graph.add_edge("rewrite_query", "retrieve") # 形成循环
# 编译图
rag_app = rag_graph.compile()
# 运行图,设置递归限制
try:
result = rag_app.invoke(
{"question": "什么是递归控制?", "iterations": 0},
{"recursion_limit": 10} # 设置递归限制
)
print("最终结果:", result)
except GraphRecursionError as e:
print(f"达到递归限制,未能找到满意的答案: {e}")输出:
检索:'什么是递归控制?'
评估文档相关性
生成答案
检查答案质量
答案不够有用,重写查询
检索:'详细信息: 什么是递归控制?'
评估文档相关性
生成答案
检查答案质量
答案质量良好,完成
最终结果: {'question': '什么是递归控制?', 'documents':
["关于'详细信息: 什么是递归控制?'的文档1", "关于'详细信息: 什么是递归控制?'的文档2"],
'generation': "基于检索到的文档,对于问题'什么是递归控制?'的回答是...",
'query': '详细信息: 什么是递归控制?', 'is_relevant': True, 'is_hallucination': False, 'is_useful': True, 'iterations': 2}七、持久化和状态管理
大模型上下文:通常仅限于当前对话的范围,一旦对话结束或超出上下文窗口(如4K-128K tokens),之前的信息就会丢失。
假设你和一个 AI 聊天,它记不住你之前说了什么,每次都像新认识你一样,这种体验会让人崩溃。
持久化通过数据库(如 Postgres)保存状态,避免这种问题。
pip install -U psycopg psycopg-pool langgraph langgraph-checkpoint-postgresLangGraph 线程持久化:信息可以存储在独立的持久层中,即使在会话结束、应用重启后依然存在。
应用场景如,长期知识积累:需要随时间积累和改进信息的应用,如个性化学习助手、长期项目管理助手等。
Checkpointer 是它的持久化组件。
from langgraph.graph import StateGraph
# StateGraph 是 LangGraph 的核心类,用于定义代理的工作流程
builder = StateGraph(...) # 创建一个工作流程
# Checkpointer 将状态保存到数据库
checkpointer = ... # 稍后详细配置
graph = builder.compile(checkpointer=checkpointer) # 编译时加入检查点而连接池是 Checkpointer 与数据库交互的一种实现方式。
具体来说:
-
Checkpointer 的作用:Checkpointer 负责将 LangGraph 代理的运行状态(如消息历史、任务状态)保存到数据库,并在需要时恢复这些状态。它需要与数据库频繁通信以实现持久化。
本质上是一个“状态管理器”,需要频繁与数据库交互。
-
连接池的作用:连接池为 Checkpointer 提供了一种高效的数据库访问机制。Checkpointer 通过连接池获取数据库连接,将状态数据写入 Postgres 数据库,或者从中读取已有状态。
连接池是 Checkpointer 与数据库通信的“桥梁”。
Checkpointer 可以选择使用【连接池】或【单一连接】来完成状态的读写操作。在高并发或大规模应用中,连接池的优势尤为明显,能够显著提升 Checkpointer 的效率。
为什么用连接池:如果图书馆每天有成百上千的读者(高并发请求),单一窗口会让管理员忙不过来。而多个窗口(连接池)可以并行处理请求,大幅提升效率。
管理员(Checkpointer)的职责是管理借书记录(代理状态),包括记录谁借了哪本书(保存状态)和根据记录找回借书历史(恢复状态)。
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
with ConnectionPool(conninfo="postgresql://postgres:postgres@localhost:5442/mydb") as pool:
checkpointer = PostgresSaver(pool)
# Checkpointer 使用连接池访问数据库
# 后续通过 checkpointer 保存状态管理员需要频繁访问书库(数据库)来完成这些任务。
如果图书馆只有一个窗口(单一连接),所有读者(Checkpointer 的操作)都必须排队等待,效率较低,尤其在高峰期(高并发场景)会造成拥堵。
图书馆有多个借书窗口(连接池中的连接),读者(Checkpointer)可以通过这些窗口快速借书或还书,而不需要每次都去书库深处取书(创建新连接)。
窗口数量有限(最大20个)但可重复使用(连接池的最大连接数),提高了借书效率。
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.prebuilt import create_react_agent # 把 LLM 变成推理+执行智能体
from langchain_openai import ChatOpenAI
# 定义数据库连接字符串(书库的地址)
DB_URI = "postgresql://postgres:postgres@localhost:5442/mydb?sslmode=disable"
# 创建连接池(多个借书窗口)
with ConnectionPool(conninfo=DB_URI, max_size=20) as pool:
# 初始化 Checkpointer(图书馆管理员)
checkpointer = PostgresSaver(pool)
checkpointer.setup() # 管理员准备记录表格
# 创建代理(读者借书流程)
model = ChatOpenAI(model_name="gpt-4o-mini")
graph = create_react_agent(model, tools=[], checkpointer=checkpointer)
# 运行代理并保存状态(借书并记录)
config = {"configurable": {"thread_id": "1"}}
res = graph.invoke({"messages": [("human", "hello")]}, config)
# 获取保存的状态(查看借书记录)
checkpoint = checkpointer.get(config)
print(checkpoint["channel_values"]["messages"])
# ConnectionPool 是借书窗口,提供与书库的连接。
# PostgresSaver 是管理员,负责记录和管理状态。
# graph.invoke 是借书过程,生成需要保存的状态。
# checkpointer.get 是查看借书记录,恢复之前的状态。Checkpointer (管理员) 模块三问
问题 1:这个模块是用来做什么的?(功能/作用)
-
回答:PostgresSaver 是 langgraph.checkpoint.postgres 模块中的核心类,用于在 LangGraph 框架中实现代理状态的持久化存储。
-
它通过 Postgres 数据库保存和恢复代理的运行状态(如消息、任务版本等),确保代理可以在中断后继续之前的工作。
-
作用:
-
保存状态:将代理的每次运行结果存储到数据库。
-
恢复状态:从数据库读取历史状态,支持连续对话或任务。
-
支持分布式系统:允许多个实例共享状态。
-
问题 2:这个模块最常用的方法有哪些?(常用方法)
-
回答:PostgresSaver 提供了几个关键方法,用于管理检查点(checkpoint)数据。
以下是最常用的方法:
-
setup():
-
功能:初始化数据库表结构,首次使用时必须调用。
-
用法:checkpointer.setup()。
-
-
get(config):
-
功能:根据配置(如线程 ID)获取最新的检查点状态。
-
返回:字典形式的检查点数据。
-
用法:checkpoint = checkpointer.get({"configurable": {"thread_id": "1"}})。
-
-
get_tuple(config):
-
功能:获取检查点的完整元组(包括配置、检查点数据和元数据)。
-
返回:CheckpointTuple 对象。
-
用法:checkpoint_tuple = checkpointer.get_tuple(config)。
-
-
put(config, checkpoint):
-
功能:将新的检查点数据写入数据库。
-
用法:通常由 LangGraph 内部调用,用户无需直接使用。
-
-
list(config):
-
功能:列出与指定配置相关的所有检查点历史。
-
返回:检查点元组的迭代器。
-
用法:checkpoints = list(checkpointer.list(config))。
-
-
问题 3:这些函数、方法的参数是什么?(参数说明)
-
回答:以下是常用方法的参数说明:
-
setup():
-
无参数。
-
作用:在数据库中创建必要的表结构(如 checkpoints 表)。
-
-
get(config):
-
config:字典,指定检查点的配置。
-
常用键:"configurable"(子字典),包含 "thread_id"(线程标识符,用于区分不同会话)。
-
示例:{"configurable": {"thread_id": "1"}}。
-
-
返回:检查点状态字典(如 channel_values、versions_seen)。
-
-
get_tuple(config):
-
config:同上,用于标识检查点。
-
返回:CheckpointTuple 对象,包含 config、checkpoint 和 metadata。
-
-
put(config, checkpoint):
-
config:检查点的配置字典。
-
checkpoint:检查点数据字典,包含状态信息(如 channel_values)。
-
作用:保存新的检查点,通常由 LangGraph 自动调用。
-
-
list(config):
-
config:检查点的配置字典。
-
返回:历史检查点的迭代器,用于调试或回溯。
-
-
异步版 AsyncPostgresSaver
补充:异步版本 AsyncPostgresSaver 提供对应的异步方法,如 aget()、asetup() 等。
AsyncPostgresSaver 是 langgraph.checkpoint.postgres 模块中的异步检查点保存器类,与同步版本 PostgresSaver 功能相同,但专为异步编程设计。
它通过非阻塞的方式与 PostgreSQL 数据库交互,适用于高并发或需要同时处理多个任务的场景。
异步方法以 a 开头(如 aget()、asetup()),需要搭配 Python 的 asyncio 库使用,并使用 await 关键字调用。
1. asetup() - 异步初始化数据库
-
功能:在数据库中创建必要的表结构,用于存储检查点数据。首次使用 AsyncPostgresSaver 时必须调用。
-
用法:
-
无参数。
-
需要使用 await 调用 --
await checkpointer.asetup()
-
from langgraph.checkpoint.postgres import AsyncPostgresSaver
# 从 langgraph.checkpoint.postgres 模块导入 AsyncPostgresSaver 类,用于异步保存和恢复检查点状态
from psycopg_pool import AsyncConnectionPool
# 从 psycopg_pool 模块导入 AsyncConnectionPool 类,用于创建异步数据库连接池
async def setup_checkpointer():
# 定义一个异步函数 setup_checkpointer,用于初始化检查点保存器
DB_URI = "postgresql://postgres:postgres@localhost:5442/mydb?sslmode=disable"
# 定义数据库连接字符串,指定用户名为 postgres,密码为 postgres,主机为 localhost,端口为 5442,数据库名为 mydb,并禁用 SSL
async with AsyncConnectionPool(conninfo=DB_URI, max_size=20) as pool:
# 使用异步上下文管理器创建连接池,conninfo 指定数据库连接信息,max_size 设置最大连接数为 20,pool 是连接池对象
checkpointer = AsyncPostgresSaver(pool)
# 创建异步检查点保存器实例,使用连接池 pool 与数据库交互
# 创建异步检查点保存器
await checkpointer.asetup()
# 异步调用 asetup 方法,初始化数据库中的检查点表结构,等待操作完成
# 异步初始化数据库表
print("数据库表已初始化完成")
# 输出提示信息,表示数据库表初始化成功
import asyncio
# 导入 asyncio 模块,提供异步编程支持,用于运行异步函数
asyncio.run(setup_checkpointer())
# 调用 asyncio.run 方法,运行 setup_checkpointer 异步函数,启动初始化流程2. aget(config) - 异步获取检查点
-
功能:根据配置从数据库中获取最新的检查点状态。
-
参数:
-
config:字典,指定检查点的标识,通常包含 "configurable": {"thread_id": "xxx"}。
-
-
返回值:检查点状态字典,包含 channel_values(消息历史等)和 versions_seen(版本信息)。
-
用法:
checkpoint = await checkpointer.aget(config)
from langgraph.checkpoint.postgres import AsyncPostgresSaver
from psycopg_pool import AsyncConnectionPool
async def get_checkpoint():
DB_URI = "postgresql://postgres:postgres@localhost:5442/mydb?sslmode=disable"
async with AsyncConnectionPool(conninfo=DB_URI, max_size=20) as pool:
checkpointer = AsyncPostgresSaver(pool)
config = {"configurable": {"thread_id": "4"}} # 指定线程 ID
checkpoint = await checkpointer.aget(config) # 异步获取检查点
print("检查点状态:", checkpoint)
import asyncio
asyncio.run(get_checkpoint())3. aput(config, checkpoint) - 异步保存检查点
-
功能:将新的检查点数据异步写入数据库。
-
参数:
-
config:字典,指定检查点的标识。
-
checkpoint:字典,包含要保存的状态数据。
-
-
用法:通常由 LangGraph 内部自动调用,但也可以手动使用。
-
await checkpointer.aput(config, checkpoint)
async def save_checkpoint():
DB_URI = "postgresql://postgres:postgres@localhost:5442/mydb?sslmode=disable"
async with AsyncConnectionPool(conninfo=DB_URI, max_size=20) as pool:
checkpointer = AsyncPostgresSaver(pool)
config = {"configurable": {"thread_id": "5"}}
checkpoint = {
"channel_values": {"messages": ["hello"]},
"versions_seen": {}
}
await checkpointer.aput(config, checkpoint) # 异步将数据写入数据库。
print("检查点已保存")
import asyncio
asyncio.run(save_checkpoint())4. alist(config) - 异步列出检查点历史
-
功能:列出与指定配置相关的所有检查点历史。
-
参数:
-
config:字典,指定检查点的标识。
-
-
返回值:异步迭代器,生成 CheckpointTuple 对象。
-
用法:
async for checkpoint in checkpointer.alist(config)
完整代码:
from langgraph.checkpoint.postgres import AsyncPostgresSaver
# 从 langgraph.checkpoint.postgres 模块导入 AsyncPostgresSaver 类,用于异步保存和恢复检查点状态
from langgraph.prebuilt import create_react_agent
# 从 langgraph.prebuilt 模块导入 create_react_agent 函数,用于快速创建反应式代理
from langchain_openai import ChatOpenAI
# 从 langchain_openai 模块导入 ChatOpenAI 类,用于调用 OpenAI 的语言模型
from psycopg_pool import AsyncConnectionPool
# 从 psycopg_pool 模块导入 AsyncConnectionPool 类,用于创建异步数据库连接池
async def main(): # 定义一个异步函数 main,作为程序的主入口,包含所有核心逻辑
# 定义数据库连接
DB_URI = "postgresql://postgres:postgres@localhost:5442/mydb?sslmode=disable"
# 定义数据库连接字符串,用户名为 postgres,密码为 postgres,主机为 localhost,端口为 5442,数据库名为 mydb,禁用 SSL
async with AsyncConnectionPool(conninfo=DB_URI, max_size=20) as pool:
# 使用异步上下文管理器创建连接池,conninfo 指定连接信息,max_size 设置最大连接数为 20,pool 是连接池对象
# 初始化检查点保存器
checkpointer = AsyncPostgresSaver(pool)
# 创建异步检查点保存器实例,使用连接池 pool 与数据库交互
await checkpointer.asetup()
# 异步调用 asetup 方法,初始化数据库中的检查点表结构,等待操作完成
# 创建代理
model = ChatOpenAI(model_name="gpt-4o-mini")
# 创建 ChatOpenAI 实例,使用 OpenAI 的 gpt-4o-mini 模型作为语言模型
tools = []
# 定义一个空工具列表,可在此添加工具函数,目前未使用任何工具
graph = create_react_agent(model, tools, checkpointer=checkpointer)
# 创建反应式代理,传入语言模型、工具列表和检查点保存器
# 运行代理
config = {"configurable": {"thread_id": "4"}}
# 定义配置字典,thread_id 为 "4",用于标识会话线程并关联检查点
res = await graph.ainvoke(
# 异步调用代理的 ainvoke 方法,处理输入并返回结果
{"messages": [("human", "what's the weather in nyc")]},
# 输入消息,模拟用户询问 NYC 的天气
config
# 传递配置,确保状态与 thread_id "4" 关联
)
print("代理响应:", res["messages"][-1].content)
# 输出代理的最终响应,从结果的消息列表中获取最后一条消息的内容
# 获取检查点
checkpoint = await checkpointer.aget(config)
# 异步调用 aget 方法,从数据库获取 thread_id "4" 的检查点状态
print("检查点消息:", checkpoint["channel_values"]["messages"])
# 输出检查点中的消息历史,显示保存的状态
import asyncio
# 导入 asyncio 模块,提供异步编程支持,用于运行异步函数
asyncio.run(main())
# 调用 asyncio.run 方法,运行 main 异步函数,启动整个程序八、允许人类在自动化流程中适时干预
人在环中功能允许人类在自动化流程中适时干预,主要适用于:
-
审批敏感操作:当AI要执行敏感操作前(如发送邮件、进行支付、删除文件)需要人类确认。
-
内容审核:生成营销文案、客户回复或重要文档时,由人类审核并确保内容合规、准确。
-
错误校正:发现AI推理或决策中的错误,人类可以及时纠正,防止错误进一步传播。
-
处理极端案例:对于AI无法准确处理的边缘情况,转由人类处理。
-
知识填补:当AI面临知识缺口时,允许人类提供必要信息或指导。
人机协作的核心逻辑
-
设置中断点: 在工具函数中使用
interrupt()创建中断点,暂停执行并等待人类输入。
# "AI说:我要暂停了,我有个问题要问人类"
human_response = interrupt({"query": "我需要人类专家的建议"})-
暂停执行: 执行到中断点时,图的执行暂停,当前状态被保存到检查点中。
-
状态检查: 通过
graph.get_state(config).next可以检查图是否暂停在中断点(会显示为("tools",))。 -
恢复执行: 使用
Command(resume=data)对象传入人类的输入继续执行,然后通过graph.invoke()或graph.stream()继续执行。
# "人类说:这是我的回答,你可以继续了"
resume_command = Command(resume={"data": "人类的回答内容"})-
继续处理: 图从暂停点继续执行,使用人类提供的输入数据完成剩余流程。
完整代码(状态图 + qwen + 记忆 + 人机协作):
import os
from typing import Annotated, List
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, SystemMessage, HumanMessage
from langchain_core.tools import tool
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import MemorySaver
# 设置API
os.environ["OPENAI_API_KEY"] = "sk-f80...."
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 定义状态结构
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
# 创建"请教专家"工具
@tool
def ask_expert(question: str) -> str:
"""当遇到专业或复杂问题时,请暂停并询问人类专家。这是首选的获取专业知识的方法。"""
print(f"\n[系统] AI请求人类协助,问题是: {question}\n")
expert_answer = interrupt({"question": question})
return expert_answer["data"]
# 创建检查点存储
memory = MemorySaver()
# 创建聊天机器人
model = ChatOpenAI(model="qwen-max", temperature=0.7)
# 添加系统提示,鼓励使用ask_expert工具
system_message = SystemMessage(content="""
你是一个医疗助手。当用户询问专业医疗建议时,你应该使用ask_expert工具咨询人类医生,
而不是自己回答。这样可以确保提供最准确的医疗建议。记住,对于任何专业医疗问题,
都应该首先考虑使用ask_expert工具。
""")
# 绑定工具到模型
model_with_tools = model.bind_tools([ask_expert])
# 创建状态图
graph_builder = StateGraph(State)
# 定义聊天节点处理函数
def chatbot(state):
# 确保系统消息在最前面
messages = state["messages"]
if not any(isinstance(msg, SystemMessage) for msg in messages):
messages = [system_message] + messages
# 调用模型
response = model_with_tools.invoke(messages)
return {"messages": [response]}
# 添加节点
graph_builder.add_node("chat", chatbot)
graph_builder.add_node("tools", ToolNode(tools=[ask_expert]))
# 添加边
graph_builder.add_edge(START, "chat")
graph_builder.add_conditional_edges("chat", tools_condition)
graph_builder.add_edge("tools", "chat")
# 编译图
graph = graph_builder.compile(checkpointer=memory)
# 设置会话ID
config = {"configurable": {"thread_id": "test_session"}}
# 发送更有可能触发专家咨询的问题
print("用户: 我最近被诊断出有心房颤动,应该如何管理这种情况?")
events = graph.stream(
{"messages": [HumanMessage(content="我最近被诊断出有心房颤动,应该如何管理这种情况?")]},
config,
stream_mode="values"
)
# 处理事件
for event in events:
if "messages" in event:
print(f"AI: {event['messages'][-1].content}")
# 检查是否暂停
snapshot = graph.get_state(config)
if snapshot.next == ("tools",):
print("\n[系统] 执行已暂停,等待人类专家输入。\n")
# 模拟专家输入
expert_input = """
作为一名心脏科医生,我建议心房颤动患者应该:
1. 严格遵循医生处方的抗凝血药物治疗,防止血栓形成
2. 考虑接受心律控制药物或心率控制药物
3. 在某些情况下,可能需要考虑电复律、消融术等手术干预
4. 定期随访监测心脏功能和药物疗效
5. 避免过度饮酒和咖啡因摄入,这些可能会触发心房颤动
6. 管理压力,保持充分休息
请记住,每位患者的情况都不同,需要个性化的治疗方案。
"""
# 创建恢复命令
resume_command = Command(resume={"data": expert_input})
# 继续执行
continue_events = graph.stream(resume_command, config, stream_mode="values")
# 处理继续执行的事件
for event in continue_events:
if "messages" in event:
print(f"AI: {event['messages'][-1].content}")输出:
用户: 我最近被诊断出有心房颤动,应该如何管理这种情况?
AI: 我最近被诊断出有心房颤动,应该如何管理这种情况?
AI:
[系统] AI请求人类协助,问题是: 我最近被诊断出有心房颤动,应该如何管理这种情况?
[系统] 执行已暂停,等待人类专家输入。
[系统] AI请求人类协助,问题是: 我最近被诊断出有心房颤动,应该如何管理这种情况?
模拟专家输入:
作为一名心脏科医生,我建议心房颤动患者应该:
1. 严格遵循医生处方的抗凝血药物治疗,防止血栓形成
2. 考虑接受心律控制药物或心率控制药物
3. 在某些情况下,可能需要考虑电复律、消融术等手术干预
4. 定期随访监测心脏功能和药物疗效
5. 避免过度饮酒和咖啡因摄入,这些可能会触发心房颤动
6. 管理压力,保持充分休息
请记住,每位患者的情况都不同,需要个性化的治疗方案。
AI: 根据心脏科医生的建议,对于心房颤动的管理应该包括以下几个方面:
1. 严格遵循医生处方的抗凝血药物治疗,以防止血栓形成。
2. 考虑使用心律控制药物或心率控制药物。
3. 在某些情况下,可能需要考虑电复律、消融术等手术干预措施。
4. 定期随访监测您的心脏功能和药物疗效。
5. 避免过度饮酒和咖啡因摄入,因为这些可能会触发心房颤动。
6. 学会管理压力,并确保充分休息。
请记住,每位患者的情况都是独特的,所以您需要一个个性化的治疗方案。
务必与您的医生紧密合作,确定最适合您的治疗方法。时间旅行功能:回到过去,探索新可能
简单来说,时间旅行功能让你可以:
-
回到对话的任何一个历史时刻
-
从那个时刻重新开始对话
-
探索不同的对话分支和结果
就像电子游戏中的"存档点",你可以读取之前的存档,尝试不同的选择。
适用于:
-
分析决策过程:探究AI为何做出特定决策,追踪导致错误的关键点。
-
比较解决方案:从同一起点创建多个解决方案分支,比较不同方法的效果。
-
调试与修复:识别问题发生的确切时刻,从该点重新启动而不必从头开始。
-
版本控制:保存不同版本的解决方案,类似代码版本控制,便于回退或选择最佳方案。
-
教育培训:展示不同决策路径的后果,作为团队培训或教育工具。
-
性能优化:通过尝试不同的执行路径,识别流程中的瓶颈并进行优化。
修正错误、探索不同方案、比较结果、教学演示 等。
1. get_state_history 模块
get_state_history 是 LangGraph 的核心方法,允许你获取聊天对话的完整历史状态记录。
这些状态可以用来回到对话的任何历史时刻,实现"时间旅行"功能。
实际上 get_state_history 是 StateGraph 对象的一个方法,而不是独立模块:
# 获取特定对话的所有历史状态
historical_states = graph.get_state_history(config)-
config: 包含thread_id的配置字典,用于指定要获取哪个对话的历史状态-
格式:
{"configurable": {"thread_id": "对话ID"}}
-
使用前:
传统聊天机器人只能沿着单一路径前进,无法返回到之前的状态。
用户: 你能推荐一些科幻书籍吗?
AI: [推荐了几本科幻书]
用户: 介绍下第一本
AI: [介绍了第一本]一旦继续对话,无法回到之前的状态再探索不同路径。
使用后:
用户: 你能推荐一些科幻书籍吗?
AI: [推荐了几本科幻书]
用户: 介绍下第一本
AI: [介绍了第一本]
[用户回到第一次回复后]
用户: 我更喜欢奇幻类的,能换些推荐吗?
AI: [推荐奇幻书籍]2. 使用历史状态的 config 继续对话
每个历史状态都包含一个 config 属性,其中包含了 checkpoint_id。
使用这个配置可以从特定历史时刻继续对话。
# 从历史状态继续对话
response = graph.invoke(new_input, historical_state.config)-
new_input: 新的输入消息,如果从特定状态恢复而不需要新输入,可以传入None -
historical_state.config: 历史状态的配置,包含checkpoint_id和thread_id
import os
from typing import Annotated, List
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.messages import BaseMessage, HumanMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
# 设置千问 API
os.environ["OPENAI_API_KEY"] = "sk-f80c7ef1....."
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 定义状态结构
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
# 创建模型和图
model = ChatOpenAI(model="qwen-max", temperature=0.7)
def chatbot(state: State):
"""聊天机器人节点处理函数"""
return {"messages": [model.invoke(state["messages"])]}
# 创建图
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 创建记忆存储并编译图
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
# 演示时间旅行功能
def demonstrate_time_travel():
"""演示时间旅行功能"""
# 设置对话ID
config = {"configurable": {"thread_id": "time_travel_demo"}}
print("=== 第一轮对话 ===")
user_message1 = "你能推荐三本科幻小说吗?"
print(f"用户: {user_message1}")
# 第一轮对话
response1 = graph.invoke(
{"messages": [HumanMessage(content=user_message1)]},
config
)
print(f"AI: {response1['messages'][-1].content}\n")
print("=== 第二轮对话 ===")
user_message2 = "这些看起来不错,你能更详细地介绍第一本吗?"
print(f"用户: {user_message2}")
# 第二轮对话
response2 = graph.invoke(
{"messages": [HumanMessage(content=user_message2)]},
config
)
print(f"AI: {response2['messages'][-1].content}\n")
# 获取历史状态
print("获取历史状态...")
history = list(graph.get_state_history(config))
print(f"共有 {len(history)} 个历史状态点\n")
# 打印每个状态的基本信息
for i, state in enumerate(history):
msg_count = len(state.values["messages"]) if "messages" in state.values else 0
print(f"状态 {i}: 消息数量 = {msg_count}, 下一步 = {state.next}")
# 选择第一轮对话后的状态(一般是倒数第三个,但需要根据实际情况调整)
# 这里我们从消息数量来判断
first_response_state = None
for state in history:
if len(state.values["messages"]) == 2: # 用户问题 + AI回复
first_response_state = state
break
if first_response_state:
print("\n=== 时间旅行:回到第一轮对话后 ===")
print(f"从状态点继续,消息数量: {len(first_response_state.values['messages'])}\n")
# 从第一轮对话后继续,但提出不同的问题
alt_message = "我更喜欢奇幻类的小说,能换些推荐吗?"
print(f"用户: {alt_message}")
# 使用历史状态的配置继续对话
alt_response = graph.invoke(
{"messages": [HumanMessage(content=alt_message)]},
first_response_state.config # 关键:使用历史状态的配置
)
print(f"AI(新分支): {alt_response['messages'][-1].content}\n")
# 获取并显示新的历史状态
new_history = list(graph.get_state_history(config))
print(f"时间旅行后,总共有 {len(new_history)} 个历史状态点")
else:
print("找不到合适的历史状态点")
# 运行演示
if __name__ == "__main__":
demonstrate_time_travel()-
状态记录:
-
每次聊天都会创建新的状态点
-
状态点包含当时的消息历史、下一步操作和配置信息
-
-
获取历史:
-
graph.get_state_history(config)获取特定对话的所有历史状态 -
返回一个可迭代对象,包含所有保存的状态点
-
-
选择历史点:
-
基于消息数量或其他特征选择要回到的状态点
-
每个状态点都有唯一的
checkpoint_id
-
-
时间旅行:
-
使用
historical_state.config从选定状态点继续 -
这会创建一个新的对话分支,原始对话历史仍然保留
-
输出:
=== 第一轮对话 ===
用户: 你能推荐三本科幻小说吗?
AI: 当然可以。科幻小说以其丰富的想象力和对未来世界的探索而深受读者喜爱。这里有三本不同风格的科幻小说推荐给你:
1. **《三体》- 刘慈欣**:这是一部中国硬科幻作品,也是刘慈欣最著名的作品之一。它不仅在中国,在国际上也获得了极高的评价,赢得了包括雨果奖在内的多个奖项。《三体》通过讲述地球与外星文明“三体”之间的故事,探讨了人类文明、科学哲学以及宇宙法则等深刻主题。
2. **《基地系列》- 艾萨克·阿西莫夫**:这是美国作家艾萨克·阿西莫夫创作的一系列科幻小说,首次出版于1951年。该系列构建了一个庞大的银河帝国背景下的未来世界,并围绕着“心理史学”这一虚构学科展开叙述,讲述了如何利用数学预测社会发展趋势来挽救即将崩溃的帝国的故事。《基地》以其宏大的世界观设定及对未来社会发展的独特见解而闻名。
3. **《雪崩》- 尼尔·斯蒂芬森**:尼尔·斯蒂芬森是当代著名的美国科幻小说家,《雪崩》是他1992年的作品。这本书描绘了一个虚拟现实技术高度发达的近未来世界,在这个名为“Metaverse”的网络空间里,人们可以通过数字化身进行交流互动。《雪崩》被认为是赛博朋克文学的重要代表作之一,对后来许多关于互联网和虚拟现实的作品产生了影响。
这三本书各自展现了科幻小说中不同的魅力,从宇宙探险到社会学理论再到虚拟现实技术的应用,相信能够为你带来不一样的阅读体验。
=== 第二轮对话 ===
用户: 这些看起来不错,你能更详细地介绍第一本吗?
AI: 当然可以。《三体》是刘慈欣所著的一部硬科幻小说,也是他的“地球往事”三部曲中的第一部。这部作品不仅在中国,在全球范围内都获得了极高的评价,并且赢得了包括雨果奖在内的多个国际奖项。下面我将为你详细介绍这本书的内容和特色:
### 故事背景
- **地球的危机**:故事开始于20世纪70年代的文化大革命时期,当时中国的一位天文学家叶文洁在一次意外中与一个外星文明——三体人取得了联系。由于对人类社会现状感到失望,她向三体世界发送了信息,邀请他们来改造地球。
- **三体世界的困境**:三体人居住在一个条件极其恶劣、环境变化无常的星球上,他们的文明面临着周期性的毁灭性灾难。因此,当得知地球上存在适合生存的条件时,三体人决定入侵地球。
### 主要情节
- **红岸基地**:通过叶文洁的故事线,介绍了红岸基地这一秘密科研项目,它是人类首次尝试与其他智慧生命进行交流的地方。
- **三体游戏**:书中通过一款名为“三体”的虚拟现实游戏,向读者展示了三体人的历史及其文化特点。这个游戏成为连接现实与虚拟世界的重要桥梁。
- **ETO(地球三体组织)**:随着三体人计划入侵的消息逐渐泄露,地球上出现了一批支持三体人统治的人类群体,他们组成了ETO,试图协助三体人实现其目标。
- **面壁者计划**:面对即将到来的威胁,联合国启动了一个名为“面壁者”的特殊项目,选出四位具有非凡智慧和勇气的人士作为对抗三体人的关键人物。其中最引人注目的是罗辑博士,他通过自己独特的思维方式发现了可能阻止三体人入侵的方法。
### 特色
- **科学与哲学思考**:《三体》不仅仅是一部简单的科幻冒险故事,它还深入探讨了许多关于宇宙学、物理学以及人类命运等深层次问题。
- **丰富的想象力**:作者通过对未来科技发展的大胆设想,构建了一个既令人着迷又充满挑战的新世界。
- **深刻的社会批判**:通过描述不同文明之间的冲突与合作,反映了作者对于现实社会某些现象的看法。
《三体》以其独特的视角、深刻的内涵以及精彩的情节吸引了无数读者。如果你喜欢探索未知、思考人类未来的可能性,那么这绝对是一本值得一读的好书。
获取历史状态...
共有 6 个历史状态点
状态 0: 消息数量 = 4, 下一步 = ()
状态 1: 消息数量 = 3, 下一步 = ('chatbot',)
状态 2: 消息数量 = 2, 下一步 = ('__start__',)
状态 3: 消息数量 = 2, 下一步 = ()
状态 4: 消息数量 = 1, 下一步 = ('chatbot',)
状态 5: 消息数量 = 0, 下一步 = ('__start__',)
=== 时间旅行:回到第一轮对话后 ===
从状态点继续,消息数量: 2
用户: 我更喜欢奇幻类的小说,能换些推荐吗?
AI(新分支): 当然可以!奇幻小说以其丰富的想象力、独特的世界观和精彩的故事吸引了无数读者。以下是三本非常受欢迎的奇幻小说推荐:
1. **《哈利·波特》系列 - J.K.罗琳**:
这是一套风靡全球的奇幻小说,讲述了年轻的巫师哈利·波特在霍格沃茨魔法学校的冒险经历。书中构建了一个充满魔法的世界,充满了友情、勇气以及对抗黑暗势力的主题。《哈利·波特》系列不仅适合青少年阅读,也深受成年读者的喜爱。
2. **《指环王》三部曲 - J.R.R. 托尔金**:
作为现代奇幻文学的经典之作,《指环王》创造了一个庞大而详尽的中土世界。故事围绕着一枚拥有强大力量的魔戒展开,主人公弗罗多和他的伙伴们踏上了摧毁魔戒以拯救世界的旅程。这本书不仅有精彩的冒险情节,还蕴含了深刻的人性探讨和社会意义。
3. **《冰与火之歌》系列(又名《权力的游戏》)- 乔治·R·R·马丁**:
这是一部史诗般的奇幻小说,其复杂的人物关系、出人意料的情节转折以及对权力斗争的真实描绘让这部作品成为当代最受欢迎的奇幻小说之一。故事发生在一个虚构的中世纪风格世界里,各个家族为了争夺铁王座而展开了激烈的争斗。尽管原作尚未完结,但已出版的部分已经赢得了广泛赞誉,并被改编成了同样受欢迎的电视剧集。
这三本书都是奇幻文学领域中的杰出代表,无论是从故事情节还是世界观构建方面都极具魅力,希望你会喜欢!
时间旅行后,总共有 9 个历史状态点九、子图设计
子图是一个完整的、独立的图,可以被整合到另一个图(父图)中作为一个节点。
这就像是在一个大型团队中有小型专业团队一样 - 每个小团队可以独立完成特定任务,同时与大团队协同工作。
有一个主系统(主图)接收问题:
-
系统能够判断问题属于哪个领域(数学或历史)
-
然后将问题转发给相应的专家子系统(子图)处理
-
最后整合专家的回答,提供最终答案
子图的两种使用场景
-
共享状态键的场景:父图和子图有共同的状态字段
-
不同状态结构的场景:父图和子图有完全不同的状态结构
场景一:共享状态键的子图
当父图和子图需要共享部分状态信息时,可以直接将编译好的子图作为节点添加到父图中。
代码实现步骤:
-
定义并编译子图
-
将编译好的子图作为节点添加到父图中
# 定义子图状态结构
class SubgraphState(TypedDict):
foo: str # 与父图共享的状态键
bar: str # 子图特有的状态键
# 定义子图节点函数
def subgraph_node_1(state: SubgraphState):
return {"bar": "bar"}
def subgraph_node_2(state: SubgraphState):
# 使用子图特有的状态键并更新共享状态键
return {"foo": state["foo"] + state["bar"]}
# 构建并编译子图
subgraph_builder = StateGraph(SubgraphState)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 定义父图状态结构
class ParentState(TypedDict):
foo: str # 与子图共享的状态键
# 定义父图节点函数
def node_1(state: ParentState):
return {"foo": "hi! " + state["foo"]}
# 构建父图
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
# 将编译好的子图作为节点添加
builder.add_node("node_2", subgraph)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()执行流程:
-
父图的
node_1处理状态,更新foo -
状态传递给子图
-
子图内部处理:先执行
subgraph_node_1,再执行subgraph_node_2 -
子图的最终状态更新返回给父图
场景二:不同状态结构的子图
当父图和子图有完全不同的状态结构时,需要在节点函数中手动调用子图并进行状态转换。
代码实现步骤:
-
定义并编译子图
-
创建一个父图节点函数,在其中调用子图并处理状态转换
# 定义子图状态结构
class SubgraphState(TypedDict):
# 完全不同于父图的状态结构
bar: str
baz: str
# 定义子图节点函数
def subgraph_node_1(state: SubgraphState):
return {"baz": "baz"}
def subgraph_node_2(state: SubgraphState):
return {"bar": state["bar"] + state["baz"]}
# 构建并编译子图
subgraph_builder = StateGraph(SubgraphState)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 定义父图状态结构
class ParentState(TypedDict):
foo: str # 完全不同于子图的状态结构
# 定义父图节点函数
def node_1(state: ParentState):
return {"foo": "hi! " + state["foo"]}
# 定义调用子图的节点函数
def node_2(state: ParentState):
# 将父图状态转换为子图状态
response = subgraph.invoke({"bar": state["foo"]})
# 将子图结果转换回父图状态
return {"foo": response["bar"]}
# 构建父图
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
# 添加调用子图的节点函数
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()执行流程:
-
父图的
node_1处理状态,更新foo -
node_2函数将父图状态转换为子图需要的格式 -
调用子图并等待子图执行完成
-
node_2函数将子图结果转换回父图状态格式 -
更新后的状态返回给父图
查看子图执行过程
使用stream方法并设置subgraphs=True可以查看子图的执行过程:
# 使用 graph.stream() 方法执行图并以流式方式返回执行过程中的每个状态更新
# {"foo": "foo"} 是初始状态,提供了开始执行所需的数据
# subgraphs=True 参数表示要显示子图的执行细节,而不仅仅是顶层图的结果
for chunk in graph.stream({"foo": "foo"}, subgraphs=True):
# 遍历每个执行步骤产生的状态块
# 每个 chunk 包含了节点执行的信息和状态更新
# 当 subgraphs=True 时,chunk 是一个元组,包含路径和状态更新:
# - 第一个元素:表示执行路径,空元组表示主图,非空表示子图路径
# - 第二个元素:包含节点名称和对应的状态更新
print(chunk)完整子图例子:
from typing import TypedDict, List, Literal, Annotated
from operator import add
import uuid
import time
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# 定义专家子图状态
class ExpertState(TypedDict):
question: str
thoughts: str
answer: str
expertise: str
logs: Annotated[List[str], add]
# 创建专家节点函数
def expert_think(state: ExpertState):
"""专家思考问题的节点"""
expertise = state["expertise"]
question = state["question"]
# 模拟专家思考过程
thoughts = f"作为{expertise}专家,我需要考虑{question}..."
time.sleep(1) # 模拟思考时间
return {
"thoughts": thoughts,
"logs": [f"专家({expertise})正在思考: {time.ctime()}"]
}
def expert_answer(state: ExpertState):
"""专家提供答案的节点"""
expertise = state["expertise"]
question = state["question"]
thoughts = state["thoughts"]
# 模拟专家回答
if expertise == "数学":
answer = f"从数学角度: {question}的答案是基于数学原理..."
elif expertise == "历史":
answer = f"从历史角度: {question}可以追溯到历史事件..."
else:
answer = f"从{expertise}角度: {question}的答案是..."
return {
"answer": answer,
"logs": [f"专家({expertise})提供答案: {time.ctime()}"]
}
# 构建专家子图
def build_expert_graph(expertise_type: str):
"""创建特定领域的专家子图"""
expert_builder = StateGraph(ExpertState)
# 添加节点
expert_builder.add_node("思考", expert_think)
expert_builder.add_node("回答", expert_answer)
# 添加边
expert_builder.add_edge(START, "思考")
expert_builder.add_edge("思考", "回答")
expert_builder.add_edge("回答", END)
# 编译专家子图
memory_saver = MemorySaver()
return expert_builder.compile(checkpointer=memory_saver)
# 创建各领域的专家子图
math_expert = build_expert_graph("数学")
history_expert = build_expert_graph("历史")
# 定义主图状态
class MainState(TypedDict):
query: str
expert_type: Literal["数学", "历史", "其他"]
expert_answer: str # 添加字段用于存储专家回答
final_answer: str
all_logs: Annotated[List[str], add]
# 主图节点函数
def classify_query(state: MainState):
"""分类查询类型的节点"""
query = state["query"]
# 简单分类逻辑
if "数学" in query or "计算" in query or "三角形" in query or "勾股定理" in query:
expert_type = "数学"
elif "历史" in query or "古代" in query or "发明" in query:
expert_type = "历史"
else:
expert_type = "其他"
return {
"expert_type": expert_type,
"all_logs": [f"查询已分类为: {expert_type} - {time.ctime()}"]
}
def call_math_expert(state: MainState):
"""调用数学专家子图"""
# 准备子图输入 - 确保包含所有必要字段
subgraph_input = {
"question": state["query"],
"expertise": "数学", # 显式提供expertise字段
"thoughts": "",
"answer": "",
"logs": []
}
# 调用子图
result = math_expert.invoke(subgraph_input)
# 处理子图输出
return {
"expert_answer": result["answer"],
"all_logs": result["logs"] # 添加子图的日志到主图
}
def call_history_expert(state: MainState):
"""调用历史专家子图"""
# 准备子图输入 - 确保包含所有必要字段
subgraph_input = {
"question": state["query"],
"expertise": "历史", # 显式提供expertise字段
"thoughts": "",
"answer": "",
"logs": []
}
# 调用子图
result = history_expert.invoke(subgraph_input)
# 处理子图输出
return {
"expert_answer": result["answer"],
"all_logs": result["logs"]
}
def route_to_expert(state: MainState) -> str:
"""根据专家类型路由的函数"""
expert_type = state["expert_type"]
if expert_type == "数学":
return "math_expert"
elif expert_type == "历史":
return "history_expert"
else:
return "general_answer"
def general_answer(state: MainState):
"""当没有特定专家时的回答节点"""
return {
"final_answer": "这个问题需要综合知识,我建议查阅更多资料。",
"all_logs": ["使用通用回答 - " + time.ctime()]
}
def process_expert_answer(state: MainState):
"""处理专家回答的节点"""
expert_type = state["expert_type"]
expert_answer = state["expert_answer"]
return {
"final_answer": f"根据{expert_type}专家的意见: {expert_answer}",
"all_logs": [f"处理了{expert_type}专家的回答 - {time.ctime()}"]
}
# 构建主图
builder = StateGraph(MainState)
# 添加节点
builder.add_node("分类", classify_query)
builder.add_node("数学专家", call_math_expert)
builder.add_node("历史专家", call_history_expert)
builder.add_node("通用回答", general_answer)
builder.add_node("处理回答", process_expert_answer)
# 添加边
builder.add_edge(START, "分类")
builder.add_conditional_edges("分类", route_to_expert, {
"math_expert": "数学专家",
"history_expert": "历史专家",
"general_answer": "通用回答"
})
builder.add_edge("数学专家", "处理回答")
builder.add_edge("历史专家", "处理回答")
builder.add_edge("通用回答", END)
builder.add_edge("处理回答", END)
# 编译主图
memory_saver = MemorySaver()
main_graph = builder.compile(checkpointer=memory_saver)
# 创建线程ID
thread_id = str(uuid.uuid4())
print(f"线程ID: {thread_id}")
# 配置
config = {"configurable": {"thread_id": thread_id}}
# 执行图 - 数学问题
result1 = main_graph.invoke(
{"query": "如何计算三角形的面积?", "all_logs": []},
config
)
print("\n--- 数学问题结果 ---")
print(f"查询: {result1['query']}")
print(f"专家类型: {result1['expert_type']}")
print(f"最终答案: {result1['final_answer']}")
print("日志:")
for log in result1['all_logs']:
print(f" - {log}")
# 执行图 - 历史问题
# 使用相同的线程ID续接状态
result2 = main_graph.invoke(
{"query": "古代中国的四大发明是什么?", "all_logs": []},
config
)
print("\n--- 历史问题结果 ---")
print(f"查询: {result2['query']}")
print(f"专家类型: {result2['expert_type']}")
print(f"最终答案: {result2['final_answer']}")
print("日志:")
for log in result2['all_logs']:
print(f" - {log}")
# 查看子图的工作
print("\n--- 子图执行流 ---")
for chunk in main_graph.stream(
{"query": "什么是勾股定理?", "all_logs": []},
config,
stream_mode="values",
subgraphs=True
):
# 打印每个步骤的输出
print(chunk)输出:
线程ID: 8c94e1da-0741-4ff5-889a-b42d4f55443a
--- 数学问题结果 ---
查询: 如何计算三角形的面积?
专家类型: 数学
最终答案: 根据数学专家的意见: 从数学角度: 如何计算三角形的面积?的答案是基于数学原理...
日志:
- 查询已分类为: 数学 - Tue Mar 25 16:13:19 2025
- 专家(数学)正在思考: Tue Mar 25 16:13:20 2025
- 专家(数学)提供答案: Tue Mar 25 16:13:20 2025
- 处理了数学专家的回答 - Tue Mar 25 16:13:20 2025
--- 历史问题结果 ---
查询: 古代中国的四大发明是什么?
专家类型: 历史
最终答案: 根据历史专家的意见: 从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...
日志:
- 查询已分类为: 数学 - Tue Mar 25 16:13:19 2025
- 专家(数学)正在思考: Tue Mar 25 16:13:20 2025
- 专家(数学)提供答案: Tue Mar 25 16:13:20 2025
- 处理了数学专家的回答 - Tue Mar 25 16:13:20 2025
- 查询已分类为: 历史 - Tue Mar 25 16:13:20 2025
- 专家(历史)正在思考: Tue Mar 25 16:13:21 2025
- 专家(历史)提供答案: Tue Mar 25 16:13:21 2025
- 处理了历史专家的回答 - Tue Mar 25 16:13:21 2025
--- 子图执行流 ---
((), {'query': '什么是勾股定理?', 'expert_type': '历史', 'expert_answer': '从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...', 'final_answer': '根据历史专家的意见: 从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...', 'all_logs': ['查询已分类为: 数学 - Tue Mar 25 16:13:19 2025', '专家(数学)正在思考: Tue Mar 25 16:13:20 2025', '专家(数学)提供答案: Tue Mar 25 16:13:20 2025', '处理了数学专家的回答 - Tue Mar 25 16:13:20 2025', '查询已分类为: 历史 - Tue Mar 25 16:13:20 2025', '专家(历史)正在思考: Tue Mar 25 16:13:21 2025', '专家(历史)提供答案: Tue Mar 25 16:13:21 2025', '处理了历史专家的回答 - Tue Mar 25 16:13:21 2025']})
((), {'query': '什么是勾股定理?', 'expert_type': '数学', 'expert_answer': '从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...', 'final_answer': '根据历史专家的意见: 从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...', 'all_logs': ['查询已分类为: 数学 - Tue Mar 25 16:13:19 2025', '专家(数学)正在思考: Tue Mar 25 16:13:20 2025', '专家(数学)提供答案: Tue Mar 25 16:13:20 2025', '处理了数学专家的回答 - Tue Mar 25 16:13:20 2025', '查询已分类为: 历史 - Tue Mar 25 16:13:20 2025', '专家(历史)正在思考: Tue Mar 25 16:13:21 2025', '专家(历史)提供答案: Tue Mar 25 16:13:21 2025', '处理了历史专家的回答 - Tue Mar 25 16:13:21 2025', '查询已分类为: 数学 - Tue Mar 25 16:13:21 2025']})
(('数学专家:95f084dc-710e-b1ba--',), {'question': '什么是勾股定理?', 'thoughts': '', 'answer': '', 'expertise': '数学', 'logs': []})
(('数学专家:95f084dc-710e-b1ba--',), {'question': '什么是勾股定理?', 'thoughts': '作为数学专家,我需要考虑什么是勾股定理?...', 'answer': '', 'expertise': '数学', 'logs': ['专家(数学)正在思考: Tue Mar 25 16:13:22 2025']})
(('数学专家:95f084dc-710e-b1ba--',), {'question': '什么是勾股定理?', 'thoughts': '作为数学专家,我需要考虑什么是勾股定理?...', 'answer': '从数学角度: 什么是勾股定理?的答案是基于数学原理...', 'expertise': '数学', 'logs': ['专家(数学)正在思考: Tue Mar 25 16:13:22 2025', '专家(数学)提供答案: Tue Mar 25 16:13:22 2025']})
((), {'query': '什么是勾股定理?', 'expert_type': '数学', 'expert_answer': '从数学角度: 什么是勾股定理?的答案是基于数学原理...', 'final_answer': '根据历史专家的意见: 从历史角度: 古代中国的四大发明是什么?可以追溯到历史事件...', 'all_logs': ['查询已分类为: 数学 - Tue Mar 25 16:13:19 2025', '专家(数学)正在思考: Tue Mar 25 16:13:20 2025', '专家(数学)提供答案: Tue Mar 25 16:13:20 2025', '处理了数学专家的回答 - Tue Mar 25 16:13:20 2025', '查询已分类为: 历史 - Tue Mar 25 16:13:20 2025', '专家(历史)正在思考: Tue Mar 25 16:13:21 2025', '专家(历史)提供答案: Tue Mar 25 16:13:21 2025', '处理了历史专家的回答 - Tue Mar 25 16:13:21 2025', '查询已分类为: 数学 - Tue Mar 25 16:13:21 2025', '专家(数学)正在思考: Tue Mar 25 16:13:22 2025', '专家(数学)提供答案: Tue Mar 25 16:13:22 2025']})
((), {'query': '什么是勾股定理?', 'expert_type': '数学', 'expert_answer': '从数学角度: 什么是勾股定理?的答案是基于数学原理...', 'final_answer': '根据数学专家的意见: 从数学角度: 什么是勾股定理?的答案是基于数学原理...', 'all_logs': ['查询已分类为: 数学 - Tue Mar 25 16:13:19 2025', '专家(数学)正在思考: Tue Mar 25 16:13:20 2025', '专家(数学)提供答案: Tue Mar 25 16:13:20 2025', '处理了数学专家的回答 - Tue Mar 25 16:13:20 2025', '查询已分类为: 历史 - Tue Mar 25 16:13:20 2025', '专家(历史)正在思考: Tue Mar 25 16:13:21 2025', '专家(历史)提供答案: Tue Mar 25 16:13:21 2025', '处理了历史专家的回答 - Tue Mar 25 16:13:21 2025', '查询已分类为: 数学 - Tue Mar 25 16:13:21 2025', '专家(数学)正在思考: Tue Mar 25 16:13:22 2025', '专家(数学)提供答案: Tue Mar 25 16:13:22 2025', '处理了数学专家的回答 - Tue Mar 25 16:13:22 2025']})十、多智能体管理器
创建执行特定任务智能体
工作智能体是执行实际任务的智能体,如搜索信息或执行代码。
在这个例子中,我们使用 LangGraph 的预构建函数 create_react_agent 来创建这些智能体。
模块 3 问:create_react_agent
-
功能/作用:
create_react_agent是 LangGraph 的预构建函数,用于创建使用 ReAct(推理+行动)框架的智能体,它能推理并使用工具。 -
常用方法:通过
invoke方法调用智能体处理输入。 -
参数说明:
-
llm:底层的语言模型 -
tools:智能体可以使用的工具列表 -
prompt:可选的提示,用于定制智能体行为
-
-
使用对比:
-
不使用预构建函数:需要手动实现整个 ReAct 循环逻辑
-
使用预构建函数:
agent = create_react_agent(llm, tools=[tool1, tool2])
-
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
@tool
def calculator(expression: str):
"""计算数学表达式"""
return eval(expression)
# 创建能够使用计算器的智能体
math_agent = create_react_agent(
llm,
tools=[calculator],
prompt="你是一个数学助手,专长于解决数学问题。"
)
# 调用智能体
result = math_agent.invoke({"messages": [{"role": "user", "content": "计算 125 * 37"}]})
print(result["messages"][-1].content)监督智能体构建
监督智能体的任务,是决定下一步应该由哪个工作者智能体来处理任务,或者决定任务是否已完成。
监督者节点函数就像一个团队领导,它决定下一步应该让谁来工作 —— 是让研究员去查找信息,还是让程序员去写代码,或者认为任务已经完成了。
想象你有一个问题需要解决,比如"帮我计算42的平方根并在网上查找相关信息"。
整个过程是这样的:
-
接收问题:监督者首先看到你的问题和历史消息
构建消息历史:
messages = [
{"role": "system", "content": system_prompt},
# 添加系统提示作为第一条消息,告诉模型 TA 是一个任务监督者
] + state["messages"]
# 添加当前状态中的所有消息(用户问题和之前的对话)
# 这样模型就能看到完整的对话历史,做出合适的决策-
思考决策:监督者思考"这个问题需要谁来解决?"
-
需要搜索信息吗?那就让研究员来
-
需要计算或编程吗?那就让程序员来
-
已经解决了吗?那就完成任务
-
-
发出指令:监督者说 "这个问题交给程序员处理" 或 "交给研究员处理" 或 "任务已完成"
response = llm.with_structured_output(Router).invoke(messages)
# llm 是前面创建的千问模型实例
# with_structured_output(Router) 告诉模型必须输出符合 Router 结构的JSON
# Router 结构规定返回必须有一个 next 字段,值只能是"researcher"、"coder"或"FINISH"
# invoke(messages) 把所有消息发送给模型,让它思考并回答
# 这行代码的目的是让AI决定下一步应该由谁来处理任务
goto = response["next"]
# 从模型的响应中获取 next 字段的值
# 这个值就是AI决定的下一步去向,可能是"researcher"、"coder"或"FINISH"
if goto == "FINISH":
# 如果AI决定任务已完成(返回"FINISH")
goto = END
# 这样系统就知道不需要再继续处理,可以返回最终结果了 更新记录:记录下一步谁来处理这个问题
return Command(goto=goto, update={"next": goto})
# 创建并返回一个 Command 对象
# goto 参数告诉系统下一步应该执行哪个节点
# update 参数指定要更新的状态,这里是将 next 字段更新为选择的节点
# 这个命令让系统知道接下来该做什么和如何更新状态监督者节点函数 ( supervisor_node) 是多智能体系统的关键控制中心,负责决策下一步应该由哪个智能体来执行任务。
def supervisor_node(state: State) -> Command[Literal["researcher", "coder", "__end__"]]:
# 这个函数接收一个 state 状态图类型参数(包含消息历史和下一步指示)
# 返回 Command 对象,指定下一步到哪个节点(只能"researcher"、"coder"或"end"三者之一)假设用户问:"帮我计算42的平方根",函数执行流程可能是:
-
接收包含用户问题的状态对象
-
构建消息列表,包括系统提示和用户问题
-
发送给千问模型,询问谁应该处理这个问题
-
千问模型分析后返回
{"next": "coder"} -
提取决策结果
goto = "coder" -
由于不是"FINISH",保持
goto不变 -
返回
Command(goto="coder", update={"next": "coder"}) -
系统根据这个命令,将控制权转交给编码者节点
这就是监督者节点函数的完整工作流程。
核心功能就是决策,决定每一步由哪个工作者来处理任务,实现智能体之间的协作。
import os
from typing import Literal
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI # 改为使用 OpenAI 兼容接口
from langgraph.graph import MessagesState, END
from langgraph.types import Command
# 设置千问 API
os.environ["OPENAI_API_KEY"] = "sk-f80..." # 设置 API 密钥
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1" # 设置基础 URL 为千问的兼容模式 API
# 定义团队成员
members = ["researcher", "coder"] # 定义两种工作者角色
# 可选的下一步选项(包括完成)
options = members + ["FINISH"] # 添加任务完成选项
# 为监督者 LLM 设置系统提示
system_prompt = (
"You are a supervisor tasked with managing a conversation between the"
# 你是一个负责管理对话的监督者
f" following workers: {members}. Given the following user request,"
# 需要管理的工作者包括:研究者和编码者
" respond with the worker to act next. Each worker will perform a"
# 根据用户请求,回复下一步应该由哪个工作者行动
" task and respond with their results and status. When finished,"
# 每个工作者将执行任务并返回结果和状态
" respond with FINISH."
# 当任务完成时,回复"FINISH"
)
# 定义监督者返回的类型(下一步去向)
class Router(TypedDict):
"""Worker to route to next. If no workers needed, route to FINISH.""" # 下一步路由到哪个工作者,如果不需要则完成
next: Literal["researcher", "coder", "FINISH"] # 明确列出所有可能的值
# 创建 LLM 实例,使用千问 API
llm = ChatOpenAI(
model="qwen-max", # 使用千问的模型
temperature=0.0 # 设置低温度以获得更确定性的输出
)
# 扩展消息状态类,添加 next 字段
class State(MessagesState):
next: str # 添加next字段,表示下一步去向
# 定义监督者节点函数
def supervisor_node(state: State) -> Command[Literal["researcher", "coder", "__end__"]]:
# 构建消息列表,包括系统提示和当前状态中的所有消息
messages = [
{"role": "system", "content": system_prompt}, # 添加系统提示作为第一条消息
] + state["messages"] # 添加当前状态中的所有消息
# 使用LLM来决定下一步,要求它输出符合Router类型的结构化输出
response = llm.with_structured_output(Router).invoke(messages)
# 从LLM响应中获取下一步去向
goto = response["next"]
# 如果LLM决定任务完成,将goto设置为END(图的终止节点)
if goto == "FINISH":
goto = END
# 返回一个Command对象,指示下一步去向和状态更新
return Command(goto=goto, update={"next": goto})这段代码做了四件事:
-
准备信息:把你的问题和之前的对话记录整理好,让AI能够理解当前情况
-
询问AI:把整理好的信息发给AI(千问模型),问它"接下来应该让谁工作?"
-
获取决定:AI回答说"让研究员工作"或"让程序员工作"或"任务完成了"
-
发出指令:根据AI的回答,发出指令让对应的人开始工作,或者结束任务
十一、长期记忆 + 有状态Agent
LangGraph 中两种类型的内存(Memory):短期内存(Short-term Memory)和长期内存(Long-term Memory)。
短期内存基于线程(thread)范围,通过检查点(checkpointer)持久化到数据库;
长期内存跨线程共享,通过存储(store)管理。
短期记忆
AI代理中的短期记忆是指在单一对话或“线程”中存储和回忆信息的能力。
可以将其想象为一张临时便笺,仅记录当前聊天的内容,例如用户最近的问题。
短期记忆将交互组织在一个线程中,类似于电子邮件链。
LangGraph通过“状态”管理短期记忆,确保代理根据上下文回应,而不会混淆不同对话。
在LangGraph中,这存储在State对象中。
步骤1:定义对话线程
# 定义一个简单的状态字典,表示对话线程
from typing import TypedDict
class State(TypedDict):
messages: list # 存储消息的列表
# 初始化一个空的对话线程
state = {"messages": []}步骤2:向线程添加消息
消息(例如用户输入、AI回复)被追加到状态中
# 添加用户消息到状态
state["messages"].append("用户:嗨,你好吗?")
state["messages"].append("AI:你好!我很好,谢谢。")
# 查看当前状态
print(state["messages"])
# 输出: ['用户:嗨,你好吗?', 'AI:你好!我很好,谢谢。']步骤3:通过更新管理线程
使用函数更新状态,仅保留最近的消息。
# 定义一个管理消息的函数,保留最后两条消息
def manage_messages(existing: list, update: dict) -> list:
if update.get("type") == "keep_last": # 检查更新类型是否为保留最后部分
return existing[-2:] # 只保留最后两条消息
return existing + [update] # 默认添加新消息
# 更新状态,只保留最后两条
state["messages"] = manage_messages(state["messages"], {"type": "keep_last"})
print(state["messages"])
# 输出: ['用户:嗨,你好吗?', 'AI:你好!我很好,谢谢。']
# 添加新消息后再次管理
state["messages"] = manage_messages(state["messages"], "用户:太好了!")
state["messages"] = manage_messages(state["messages"], {"type": "keep_last"})
print(state["messages"])
# 输出: ['AI:你好!我很好,谢谢。', '用户:太好了!']长期记忆
长期记忆在AI代理中是指能够跨不同对话或线程存储和回忆信息的能力。
与短期记忆仅限于单一线程不同,长期记忆像一个永久的档案柜,可以在任何时间、任何对话中调用。
例如,AI可以记住用户喜欢简短回答,即使在几天后的新对话中也能保持一致。
LangGraph 通过“存储”(Store)机制管理长期记忆,以JSON文档形式保存数据,并按自定义命名空间组织。
长期记忆以键值对形式存储,类似于文件系统中的文件夹和文件。
在LangGraph中,使用 InMemoryStore(内存存储)保存数据。
步骤1:定义长期记忆的基本结构
# 初始化一个简单的内存存储
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # 创建内存存储对象,用于保存长期记忆步骤2:存储长期记忆
使用命名空间(namespace)和键(key)保存数据,命名空间通常包含用户ID或场景。
# 定义用户和应用场景的命名空间
user_id = "用户123"
app_context = "聊天"
namespace = (user_id, app_context) # 元组作为命名空间
# 存储一条长期记忆
store.put(
namespace, # 命名空间
"偏好", # 键名
{"语言": "中文", "风格": "简短"} # 值:用户的偏好信息
)
# 查看存储结果(仅用于演示,实际无此直接方法)
print("已存储:", {"namespace": namespace, "key": "偏好", "value": {"语言": "中文", "风格": "简短"}})
# 输出: 已存储:{'namespace': ('用户123', '聊天'), 'key': '偏好', 'value': {'语言': '中文', '风格': '简短'}}步骤3:检索长期记忆
使用相同的命名空间和键从存储中获取数据。
# 检索长期记忆
memory = store.get(namespace, "偏好") # 获取指定命名空间和键的记忆
print("检索到的记忆:", memory)
# 输出: 检索到的记忆:{'语言': '中文', '风格': '简短'}模块三问:langgraph.store.memory.InMemoryStore
-
功能/作用:提供内存中的键值存储,用于保存和检索长期记忆(生产环境建议使用数据库支持的存储)。
-
常用方法:
-
put(namespace, key, value):存储数据。
-
get(namespace, key):检索数据。
-
search(namespace, filter, query):搜索记忆(支持过滤和查询)。
-
-
参数说明:
-
namespace:元组,表示数据的分类(如用户ID和场景)。
-
key:字符串,数据的唯一标识。
-
value:任意JSON兼容数据,通常为字典。
-
实践检测
-
什么是AI代理中的长期记忆?(回忆定义)
-
长期记忆与短期记忆的主要区别是什么?(比较概念)
-
长期记忆为何需要跨线程存储?(解释目的)
-
在LangGraph中,长期记忆存储在什么结构中?(理解框架)
-
编写一个Python字典,表示用户的长期记忆(如偏好)。(基础应用)
记忆类型与应用
AI代理的长期记忆可分为三种类型:语义记忆、情景记忆和程序记忆,每种类型有独特的应用。
-
语义记忆存储事实,如“用户喜欢中文”;
类比:想象一个学生的笔记本,记录了重要事实,如“数学公式:a² + b² = c²”或“历史事件:1949年中国成立”。这些是静态的知识,不随具体时间改变。
AI应用:语义记忆存储用户的基本信息或偏好,例如“用户喜欢中文”或“用户是程序员”。它像AI的“知识库”,提供稳定的参考。
# 类比:记录用户的“知识笔记本”
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("用户123", "知识")
store.put(namespace, "语义", {"语言": "中文", "职业": "程序员"}) # 存储事实
print("知识笔记本:", store.get(namespace, "语义"))
# 输出: 知识笔记本:{'语言': '中文', '职业': '程序员'}-
情景记忆记录经历,如“用户昨天点了一杯咖啡”;
类比:就像你写日记,记录昨天的经历:“我昨天去咖啡店,点了一杯拿铁,天气很好。”这些记忆与具体事件和时间相关,带有上下文。
AI应用:情景记忆记录用户的具体经历,如“用户昨天点了一杯咖啡”或“用户上周问了天气”。它帮助AI根据过去的行为调整回应。
# 类比:写下用户的“日记本”
store.put(namespace, "情景", {"事件": "昨天点了咖啡", "时间": "2025-03-28"})
# 记录经历
print("日记本:", store.get(namespace, "情景"))
# 输出: 日记本:{'事件': '昨天点了咖啡', '时间': '2025-03-28'}-
程序记忆保存规则,如“总是简短回答”。
类比:类似于你的日常习惯,比如“刷牙时总是先挤牙膏”或“开车时总是系安全带”。这些规则指导行为,无需每次重新思考。
AI应用:程序记忆保存AI的交互规则,如“总是简短回答”或“优先用中文回复”。它像AI的“操作手册”,确保一致性。
# 类比:定义AI的“习惯指南”
store.put(namespace, "程序", {"规则": "总是简短回答"})
# 存储规则
rule = store.get(namespace, "程序")["规则"]
print(f"习惯指南:根据'{rule}',回答:是的。")
# 输出: 习惯指南:根据'总是简短回答',回答:是的。写入记忆
“写入记忆”是指AI代理如何将信息保存到长期记忆中,以供未来使用。
有两种主要方法:“热路径写入”(实时保存,如边聊边记)和“后台写入”(异步保存,如事后整理)。
-
热路径写入适合即时更新,例如在对话中记住用户偏好
-
后台写入则减少实时负担,适合批量处理,例如定期总结对话历史
from langgraph.store.memory import InMemoryStore
# 提供内存键值存储,用于实时或异步保存长期记忆。
put(namespace, key, value) # 写入或更新记忆
get(namespace, key) # 检索记忆
# namespace:元组,分类数据。
# key:字符串,记忆标识。
# value:字典,记忆内容。方法1:热路径写入—实时保存
在对话中立即存储记忆,适用于需要即时反应的场景。
# 热路径写入:实时存储语义记忆
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # 创建内存存储
namespace = ("用户123", "对话")
def hot_path_write(user_input):
# 假设用户输入表示偏好
store.put(namespace, "语义", {"偏好": user_input}) # 实时写入
return store.get(namespace, "语义")
# 模拟对话中的写入
print(hot_path_write("喜欢简短回答"))
# 输出: {'偏好': '喜欢简短回答'}方法2:后台写入—异步保存
在对话后批量处理记忆,降低实时负载。
# 后台写入:异步存储情景记忆
import time
def background_write(event_log):
# 模拟后台任务,延迟写入
time.sleep(1) # 表示异步处理
store.put(namespace, "情景", {"事件": event_log}) # 写入经历
return store.get(namespace, "情景")
# 模拟对话后的写入
print(background_write("点了咖啡"))
# 输出: {'事件': '点了咖啡'}方法三:根据场景选择写入方法
# 结合热路径和后台写入程序记忆
def write_rule(real_time=True):
rule = "总是用中文回答"
if real_time: # 热路径
store.put(namespace, "程序", {"规则": rule})
# put(namespace, key, value):写入记忆。
print("热路径写入:", store.get(namespace, "程序"))
# get(namespace, key):检索记忆。
else: # 后台
time.sleep(1) # 模拟异步
store.put(namespace, "程序", {"规则": rule})
print("后台写入:", store.get(namespace, "程序"))
write_rule(True) # 实时写入
# 输出: 热路径写入:{'规则': '总是用中文回答'}
















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









