







TEXT2EVENT: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction
1 任务介绍
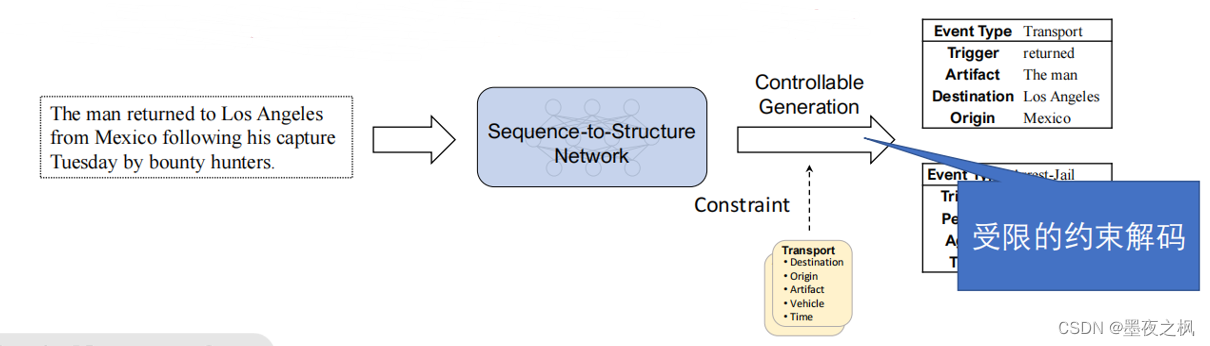
这篇文章主要是介绍提出了一个统一抽取模型,目的是使用单一架构解决不同的信息抽取的任务,所以就提出了这篇文章核心内容:序列到结构网络。对于网络的输出,还提出了按需解码控制特定任务或场景设定下的抽取目标,这一部分就是后面会提到的按需可控生成,使用事件Schema来约束生成空间,这样对于不同的任务不需要改变模型,比如说想要用这个模型训练我们的医疗数据,直接把医疗事件的schema注入进去就可以了。提出该任务还有一个更重要的目的就是想要低成本,也就是低资源学习捕捉信息抽取任务所需的抽取能力,也就是不需要人为花费昂贵的代价去标数据,所以说仅仅需要粗粒度的预料就能完成,比如说对文本事件对直接进行训练。
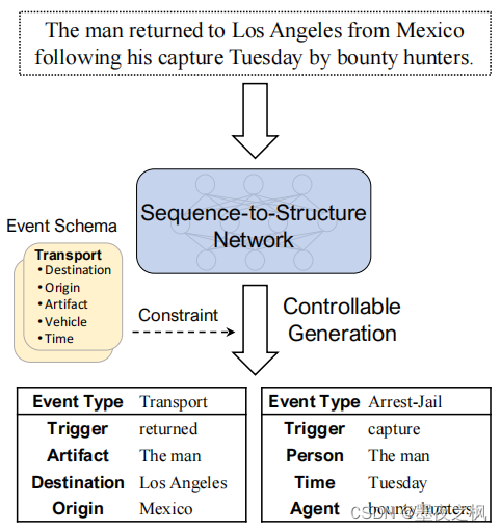
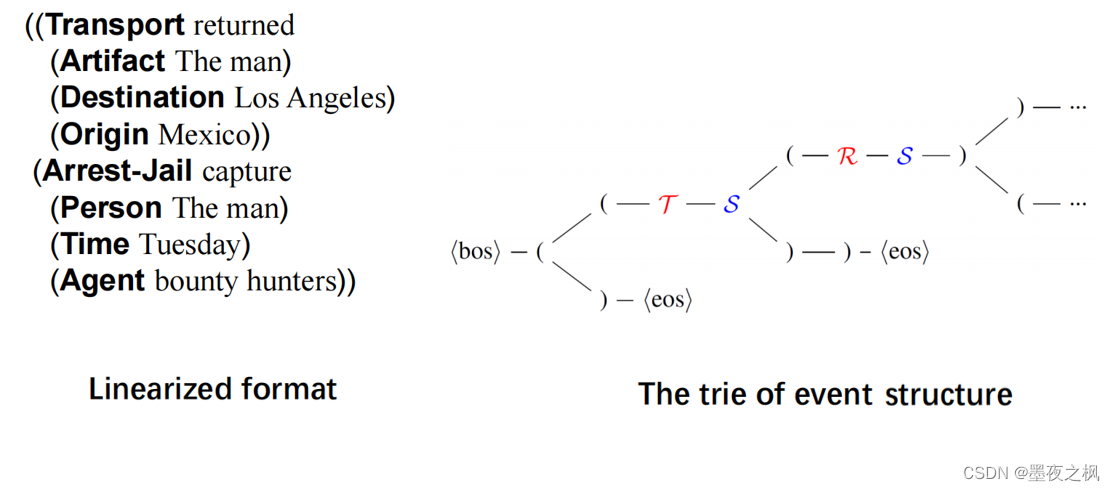
对于每一个事件记录,都包含事件类型、触发器和参数,它们形成了一个类似表的结构。(就像上图中,一个文本通过了神经网络后再经约束和可控生成得到两个表,这两个表每个都包括一个事件类型、一个触发器和三个参数)
生成的结构由框架Frame和Schema决定,所以不同的事件类型有不同的结构。上图中生成两个表Transport和Arrest-Jail,他们的结构完全不同,这是可控生成的结果。这句话其实是由两个部分组成,所以得到两个表。
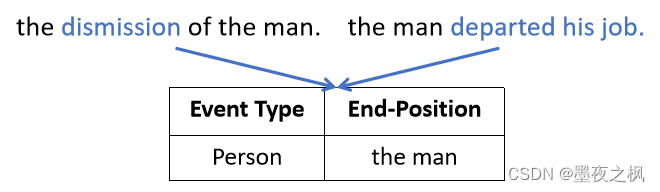
接下来是一个事件可以由不同的话语来表达。下面这个例子两个句子分别表达the man离职。所以它们的事件表达是一致的。第一个部分是:The man returned to Los Angeles from Mexico 他从墨西哥返回洛杉矶。第二个部分是:following his capture Tuesday by bounty hunters. 他在周二被赏金猎人捕获。第一个部分的事件类型是Transport,触发这个事件的是return,后面的Artifact、Destination、Origin全部是参数。第二个部分的事件类型是Arrest-Jail,是由capture触发的,后面的person、time、agent也全都是相应的参数。
2 Text2Event模型
2.1 事件提取作为结构生成
记录格式到线性化格式的转换过程:
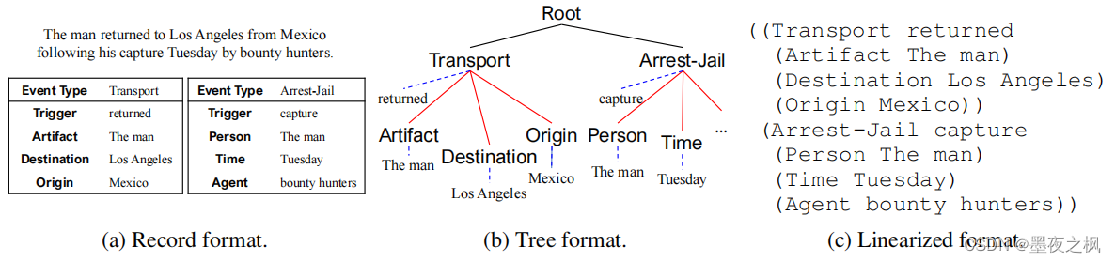
首先将事件记录表(图2a)转换为树的格式(图2b)。其中,每个事件类型对应一个子树,将它的参数和事件类型连接起来。红色实线表示event-role关系;蓝色虚线表示label-span关系,其中头部是标签,尾部为文本跨度。转换后的事件树,我们通过深度优先遍历将事件结构编码为线性序列(图2c),其中“(”和“)”是用于表示线性表达式语义结构的结构指示符。相同深度的遍历顺序是在文本中文本跨度(text spans)出现的顺序。
(role-作用,span-包括的种类)
2.2 序列到结构网络
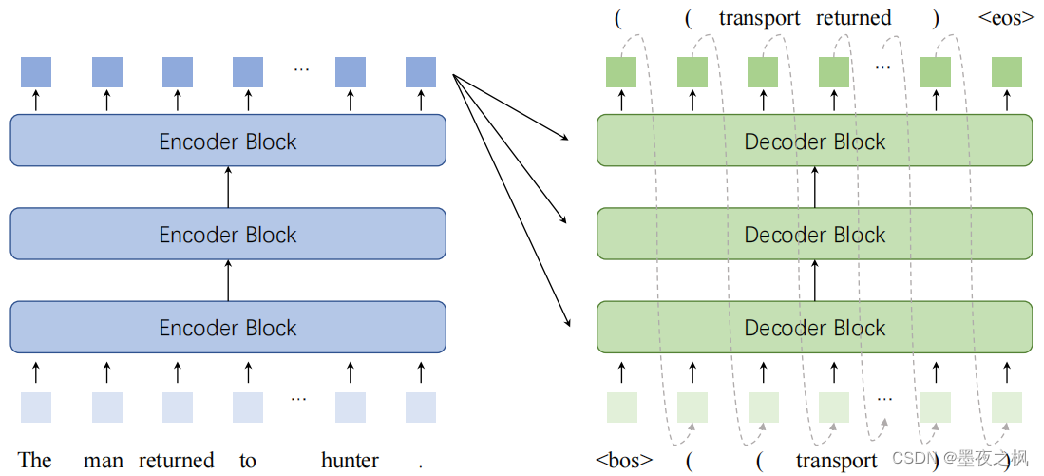
整个任务可以看做是一个文本到结构的生成任务,然后再把结构拍扁成一段文本,也就是将序列结构化表示。这个模型本质上是把T5、BERT直接拿过来用。
给定标记序列x=x1,…,x|x|作为输入,Text2Event首先通过多层转换器编码器计算输入的隐藏向量表示H=h1,…,h|x|:
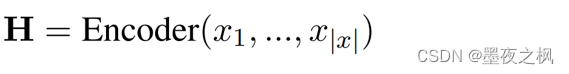
其中,每层Encoder(·)都是一个带有多头注意机制的transformer块。
在对输入的token序列进行编码后,解码器用顺序输入token的隐藏向量预测输出结构token-by-token。在生成的第i步,自注意解码器预测线性化形式的第i个token yi和解码器状态为:
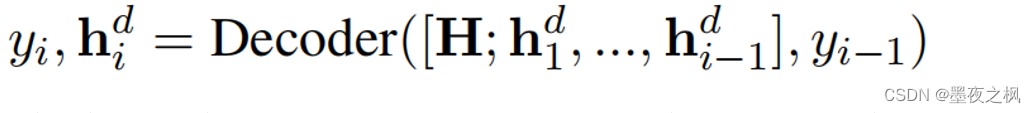
其中,每一层Decoder(·)都是一个transformer块,它包含与解码器状态的自注意和与编码器状态H的交叉注意。
生成的输出结构化序列从开始标记开始,以结束标记结束。整个输出序列p(y|x)的条件概率由每一步p(yi | y<i, x)的概率逐步组合:
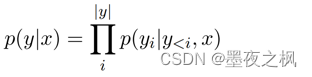
其中y<i=y1…yi−1,以及p(yi | y<i, x)是由softmax(·)归一化的目标词汇表的概率。
2.3 约束解码
以上是一个很简单的文本到结构的模型,整个生成过程并不是仅仅简单的调用模型就可以了,还有一个比较关键的就是需要进行按需约束解码。如何约束文本到结构生成正确的目标结构?这其中有两方面的要素,一是得有正确的事件框架,比如说,type后面得有个冒号然后再跟个词,大括号也不能随便生成,后面这个框架结构就不对。二是需要符合事件的Schema约束,比如说运输的事件,论元必须是目的地、出发地之类的,不能生成公司、创始人这些不沾边的词。
对于这样一个句子,它可以生成两个事件,但是到底想要生成哪个事件,不能由着它胡乱生成,所以就提出了受限的约束解码。
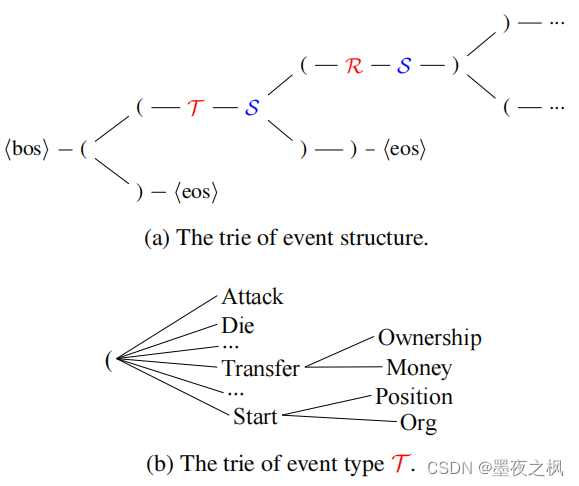
抽取结构约束被建模为解码的路径约束,使用Trie树建模
- 约束了解码空间,降低了解码难度
- Schema的约束保证结构和语义上的合法性
图(a)中,T和R表示event type和argument role的标签名称。S表示原始文本中的text span,它是提取事件的事件触发器或参数。
2.4 低资源学习

整个模型第三个核心的组件是低资源学习,也就是使用<Text,Event>对的课程表学习。为了降低学习难度,采用课程表学习,逐步提升生成结构的复杂度。这么做主要是因为以下两点,一是输出事件结构生成和预训练的文本生成存在较大的差异性,正常情况下事件生成过程中很容易出现模型的塌陷,也就是会出现生成的结构的不完整,然后就会导致无意义的参数空间。二是非语义指标“(”和“)”经常出现,但包含的语义信息很少,却非常重要。所以说采用课程表学习,也就是分步进行,先进行子结构生成学习,再进行完整结构生成学习。其实就是给定一个文本,先生成一个一个的子结构,比如说transport对应returned。然后把完整的结构送进模型训练。这样逐步的训练能保证得到较好的结果。
3 实验
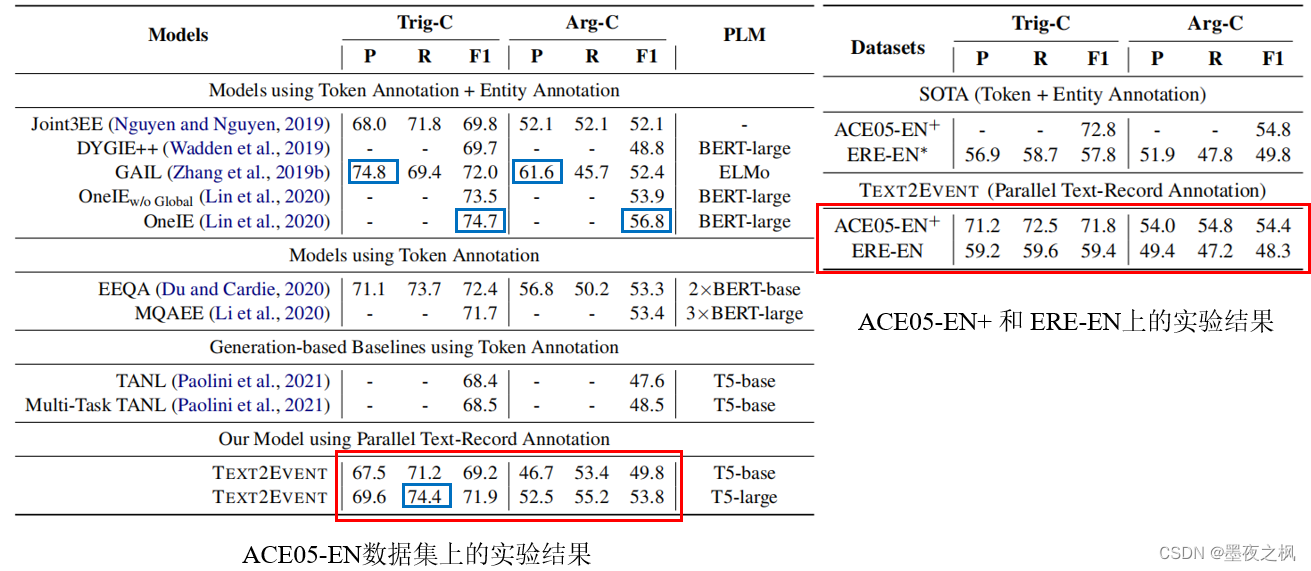
左表ACE2005的英文数据上的所有baseline和Text2Event的性能。右表显示了SOTA和Text2Event在ACE05-EN+和ERE-EN上的性能。trigger-C表示触发器的识别和分类。Argument-C表示参数的识别和分类。PLM表示每个模型所使用的预训练语言模型。Text2Event与以上这些模型(还有SOTA)相比,使用监督更少、结构更简单、性能更优。
3.1 迁移学习
Text2Event具有很强的迁移能力。比如说在10个事件类型上做预训练,然后再迁移到剩下23类的事件类别上做抽取。
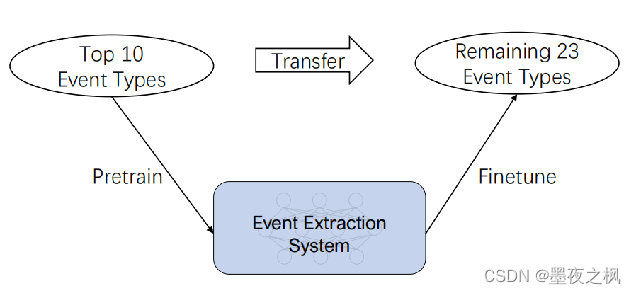
在没有加迁移学习的几种模型在触发器抽取和参数抽取上的结果差不了多少,但是引入了迁移学习一下子就变得不一样了,F值一下子就提升了3.7和3.2。
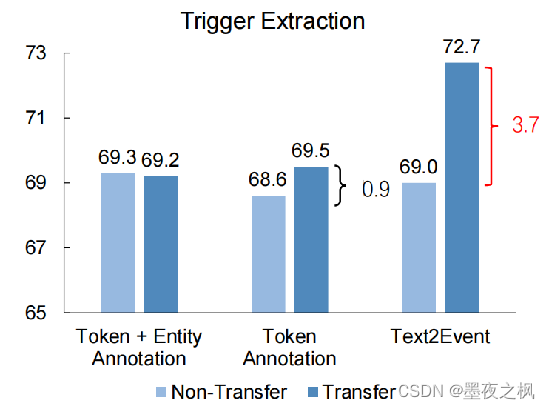
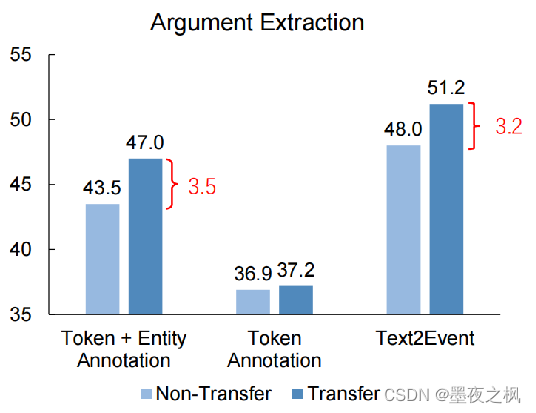
接下来,这是他们做的一个消融实验:Text2Event是直接用全结构学习进行训练的基础模型。而w/o CD在推理过程中丢弃约束解码,并生成事件结构作为无约束的生成模型。表中显示到,特别是在低资源的情况下,约束解码会使整个生成任务性能有较高的提升(能有6%-7%个点的提升),也就是说预料越少,性能越强。
4 总结
介绍了一种信息抽取新范式:结构生成统一建模,这是一种序列到结构的生成模型。能够直接学习包含知识结构平行语料,统一建模事件抽取的所有子任务。

















 1480
1480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











