






环境是gym的bipedal walker简单版,即只有轻微起伏的路面,没有障碍物。gym里没有这个环境,要额外安装,装一个swig和Box2D-2.3.10-cp39-cp39-win_amd64.whl,网上一搜就有。
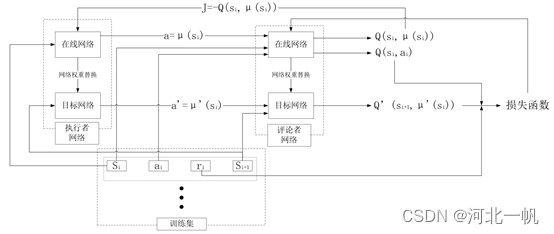
DDPG算法介绍的文章一搜一堆,这里不详述了。DDPG的数据流如上图所示。 完整代码如下
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import gym
import matplotlib.pyplot as plt
class DDPG:
def __init__(self, s_dim, a_dim, a_bound):
self.state_dim = s_dim
self.action_dim = a_dim
self.action_bound = a_bound
self.memory_size = 100000
# column labels: state, action, reward, state_next, terminal
self.memory = np.zeros((self.memory_size, 2 * self.state_dim + self.action_dim + 2))
self.memory_index = 0
self.batchsize = 32
self.gamma = 0.99
self.tau = 0.005
self.lr_a = 0.0002
self.lr_c = 0.0002
self.expl_noise = 0.25
self.policy_noise = 0.2
self.sess = tf.Session()
self.s = tf.placeholder("float", [None, self.state_dim], name="state")
self.r = tf.placeholder('float', [None, 1], name="reward")
self.s_next = tf.placeholder("float", [None, self.state_dim], name="state_next")
self.terminals = tf.placeholder('float', [None, 1], name="terminals")
with tf.variable_scope("Actor"):
self.a = self.build_actor(self.s, scope="eval", trainable=True)
self.a_next = self.build_actor(self.s_next, scope="target", trainable=False)
with tf.variable_scope("Critic"):
self.q = self.build_critic(self.s, self.a, scope="eval", trainable=True)
policy_noise = (np.random.normal(0, 1, size=self.action_dim) * 0.2).clip(-0.5, 0.5)
action_next = tf.clip_by_value(self.a_next + policy_noise, -self.action_bound, self.action_bound)
self.q_next = self.build_critic(self.s_next, action_next, scope="target", trainable=False)
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - self.tau) * t + self.tau * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
self.a_loss = -1 * tf.reduce_mean(self.q)
self.atrain = tf.train.AdamOptimizer(self.lr_a).minimize(self.a_loss, var_list=self.ae_params)
self.q_target = self.r + self.gamma * tf.multiply(self.q_next, self.terminals)
td_error = tf.losses.mean_squared_error(labels=self.q_target, predictions=self.q)
self.ctrain = tf.train.AdamOptimizer(self.lr_c).minimize(td_error, var_list=self.ce_params)
self.sess.run(tf.global_variables_initializer())
def build_critic(self, s, a, scope, trainable):
with tf.variable_scope(scope):
w1_s = tf.get_variable('w1_s', [self.state_dim, 128], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.action_dim, 128], trainable=trainable)
b1 = tf.get_variable('b1', [1, 128], trainable=trainable)
l1 = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
l2 = tf.layers.dense(l1, 128, activation=tf.nn.relu, trainable=trainable, name="l2")
q = tf.layers.dense(l2, 1, trainable=trainable, name="q")
return q
def build_actor(self, s, scope, trainable):
with tf.variable_scope(scope):
l1 = tf.layers.dense(s, 128, activation=tf.nn.tanh, name='l1', trainable=trainable)
l2 = tf.layers.dense(l1, 128, activation=tf.nn.tanh, trainable=trainable, name="l2")
a = tf.layers.dense(l2, self.action_dim, activation=tf.nn.tanh, trainable=trainable, name="a")
return tf.multiply(a, self.action_bound, name='scaled_a')
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(self.memory_size, size=self.batchsize)
bt = self.memory[indices, :]
bs = bt[:, :self.state_dim]
ba = bt[:, self.state_dim: self.state_dim + self.action_dim]
br = bt[:, self.state_dim + self.action_dim: self.state_dim + self.action_dim + 1]
bs_ = bt[:, self.state_dim + self.action_dim + 1: self.state_dim + self.action_dim + 1 + self.state_dim]
terminal = bt[:, -1:]
self.sess.run(self.atrain, {self.s: bs})
self.sess.run(self.ctrain, {self.s: bs, self.a: ba, self.r: br, self.s_next: bs_, self.terminals: terminal})
def store_memory(self, s, a, r, s_, terminal):
self.memory[self.memory_index % self.memory_size, :] = np.hstack((s.copy(), a.copy(), r, s_.copy(), terminal))
self.memory_index += 1
def choose_action(self, s):
return self.sess.run(self.a, {self.s: s[np.newaxis, :]})[0]
if __name__ == "__main__":
env = gym.make("BipedalWalker-v3")
env = env.unwrapped
env.seed(1)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high
ddpg = DDPG(state_dim, action_dim, action_bound)
expl_noise = 0.25
reward_list = []
for i_episode in range(3000):
s = env.reset()
ep_reward = 0
for i_step in range(300):
if i_episode > 2000:
env.render()
# Add exploration noise
a = ddpg.choose_action(s)
a = (a + np.random.normal(0, action_bound * expl_noise, size=action_dim)).clip(-action_bound, action_bound)
s_, r, done, info = env.step(a)
if r <= -100:
r = -1
done_int = 0.0 # 终止
else:
done_int = 1.0 # 未终止
ddpg.store_memory(s, a, r, s_, done_int)
if ddpg.memory_index > ddpg.memory_size:
expl_noise *= .999 # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if done:
break
# print(ep_reward)
if i_episode % 100 == 0:
print(i_episode, reward_list[-100:])
reward_list.append(ep_reward)
plt.plot(reward_list)
plt.show()
actor网络训练是使输出的动作拿到更大的Q值,即-Q最小化
self.a_loss = -1 * tf.reduce_mean(self.q)
self.atrain = tf.train.AdamOptimizer(self.lr_a).minimize(self.a_loss, var_list=self.ae_params)q是通过s和a来计算的
self.q = self.build_critic(self.s, self.a, scope="eval", trainable=True)这里的s来自minibatch里的记忆的state,a是通过在线actor网络输出的
self.a = self.build_actor(self.s, scope="eval", trainable=True)在线actor网络需要输入state,所以actor网络训练时,只有要把state给feed_dict到state的placeholder中
self.sess.run(self.atrain, {self.s: bs})critic网络训练时,与actor训练不同之处在于,动作不是actor网络输出的,而是从记忆中提取的,
self.sess.run(self.ctrain, {self.s: bs, self.a: ba, self.r: br, self.s_next: bs_, self.terminals: terminal})把ba给feed_dict进self.a节点,ctrain在run的时候,minimize TDerror
td_error = tf.losses.mean_squared_error(labels=self.q_target, predictions=self.q)
self.ctrain = tf.train.AdamOptimizer(self.lr_c).minimize(td_error, var_list=self.ce_params)q_target来自于target critic网络,其输入为state_next和action_next,state_next来自minibatch,action_next来自于target actor(给target actor输入minibatch的state_next)
TDerror里的q值来自于在线critic网络,其输入为minibatch的state和action
self.q = self.build_critic(self.s, self.a, scope="eval", trainable=True)注意这里的self.a不是actor网络算的,是minibatch里的动作直接feed_dict进来的(self.a: ba)
这里是网络权重soft update
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - self.tau) * t + self.tau * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]还有两个要注意的地方,就是两处噪声,一个是policy noise,加在target actor的输出上
policy_noise = (np.random.normal(0, 1, size=self.action_dim) * 0.2).clip(-0.5, 0.5)
action_next = tf.clip_by_value(self.a_next + policy_noise, -self.action_bound, self.action_bound)还有一处是exploration noise,加在作用于环境的动作上
a = ddpg.choose_action(s)
a = (a + np.random.normal(0, action_bound * expl_noise, size=action_dim)).clip(-action_bound, action_bound)使用tensorflow gpu,在台式机1660显卡上,训练不到一个小时,walker就会走了,walker走路的视频也同步上传至CSDN和b站(walker走路视频)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









