







MIG (Multi-Instance
GPU):MIG是一种在单个GPU上虚拟化多个GPU实例的技术,每个实例可以被不同的应用程序独立使用。它解决了在传统GPU上同时运行多个应用程序时出现的资源竞争和性能瓶颈问题,同时还可以实现更高效的资源利用和更好的可伸缩性。
按照这里的mixed strategy做,记得重启插件
K8s cannot schedule pod on full GPU when some other GPUs are MIG enabled
#不行重启吧
# 应对nvidia-smi mig -lcip 不能用的时候
nvidia-smi mig -lgi
# 一步到位
nvidia-smi mig -cgi 9,14,14 -C
nvidia-smi -i <GPU IDs> -mig 1
nvidia-smi mig -lgip 来确认我们能够创建的 GPU 实例
nvidia-smi mig -cgi 9,14,14 (必须小的在前)
nvidia-smi mig -lcip”看到我们现在拥有的 GPU 实例
【删除 GPU 实例 ID 7 上的计算实例 ID 0: sudo nvidia-smi mig -gi 7 -ci 0 -dci
然后删除GPU实例
删除用 nvidia-smi mig -gi 3,5 -dgi】
nvidia-smi mig -gi 2 -cci 2 在GPU实例2上创建计算实例2
这是A30,执行nvidia-smi mig -lgip后的结果
官网地址
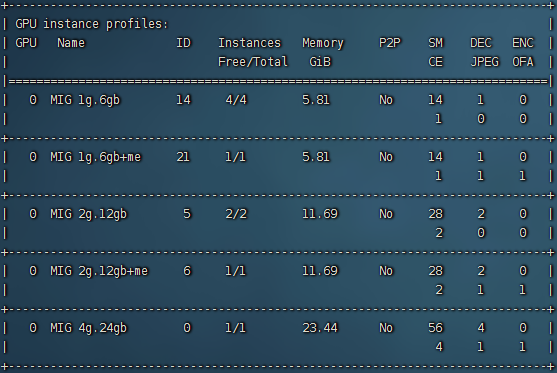
在MIG(NVIDIA的多实例GPU技术)中,“2g.12gb”表示一个GPU实例具有2个计算资源,每个计算资源具有12GB的显存。而“+me”指的是“Multi-Engine”,它表示这个GPU实例是支持多个计算引擎的。具体来说,它允许将一个GPU实例分成多个小型GPU,并行执行不同的计算任务,从而提高GPU的利用率和吞吐量。
因此,上述错误信息表示,只有在安装了R525及更高版本的驱动程序后,才能使用支持多引擎的2g.12gb GPU实例。
在NVIDIA
GPU中,每个计算引擎是一组硬件资源,包括CUDA核心、存储器、寄存器文件和其他资源,它们协同工作来执行计算任务。一个GPU可以拥有多个计算引擎,每个引擎可以独立执行不同的计算任务。例如,一个计算引擎可以执行深度学习模型的训练,而另一个计算引擎可以同时执行物理模拟的计算。这种并行执行不同类型的计算任务可以提高GPU的利用率和吞吐量,并加速整个应用程序的执行速度。因此,多个计算引擎可以帮助提高GPU的性能,使得在同一个GPU上执行多个计算任务更加高效。
nvidia mig中 CE ENC DEC OFA JPG 这些是什么?底下的数字是2 0 2 0 0 代表什么?
NVIDIA MIG 是 NVIDIA A100 GPU 上的 Multi-Instance GPU 技术。以下是这些缩写词的解释:
CE: Compute Element,即计算单元。 ENC: Encoder,即编码器。 DEC: Decoder,即解码器。 OFA:
Output Frame Analyzer,即输出帧分析器。 JPG: JPEG 核心,即支持 JPEG 图像编解码的硬件核心。 2 0 2
0 0 应该是指 NVIDIA A100 GPU 上可用的计算单元数量、编码器数量、解码器数量、输出帧分析器数量和 JPEG
核心数量。具体来说,它表示每个 NVIDIA A100 GPU 上有 2 个计算单元(CE)、0 个编码器(ENC)、2
个解码器(DEC)、0 个输出帧分析器(OFA)和 0 个 JPEG 核心(JPG)。需要注意的是,这个数字可能因配置不同而有所变化。
分好mig,让docker运行到指定mig-devices
nvidia-smi -L 拿到UUID号,然后 docker run docker run -e NVIDIA_VISIBLE_DEVICES= UUID号(比如:MIG-3d1cbd00-962dXXXXX)
名字解释
1、GI=GPU Instance
CI=Compute Instance
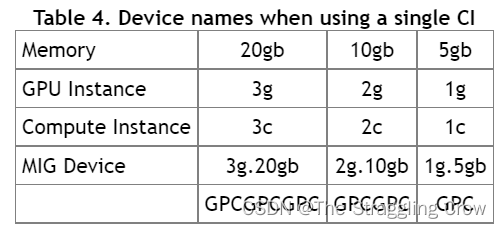
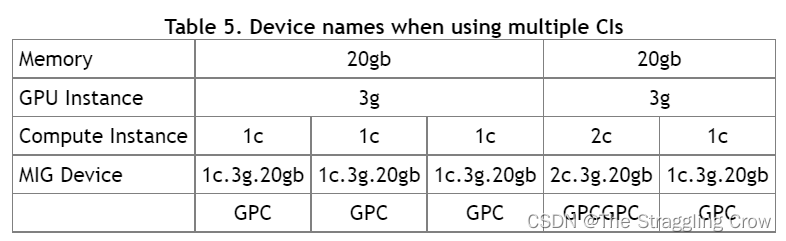
1、作用:MIG可以把单个GPU划分多个GPU分区,称为实例。最大化GPU利用率
2、实践:
在 A100 上使用 MIG 并行部署多个 Triton 推理服务器
使用 Kubernetes 和 Prometheus 监控堆栈根据推理请求的数量自动调整 Triton 推理服务器的数量。
使用 NGINX Plus 负载平衡器在不同的 Triton 推理服务器之间均匀分配推理负载。
3、DGX A100 允许在 Kubernetes 吊舱(pod)上运行多达 56 个 Triton 推理服务器(每个 A100 最多有七个使用 MIG 的服务器)
4、yaml格式不对,修理地址
5、官网介绍
博客介绍
mig的参考官网介绍,普通的如下
"default-runtime": "nvidia"
sudo systemctl restart docker
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.12.2/nvidia-device-plugin.yml
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-feature-discovery/v0.6.1/deployments/static/nfd.yaml
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-feature-discovery/v0.6.1/deployments/static/gpu-feature-discovery-daemonset.yaml














 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









