







1、CAP
只能3选2
1)一致性(Consistency)
客户每次读都是返回最新的写操作结果
2)可用性(Availability)
非故障节点在合理的时间内返回合理的响应
3)分区容忍性(Partition Tolerance)
当出现网络分区故障时,系统还能发挥作用
网络分区(network partition)是指网络故障或中断导致系统中的各个部分无法相互通信的情况。
CAP 应用
对于分布式系统,现实只能时CP 或者 AP 架构。CA是不可能的
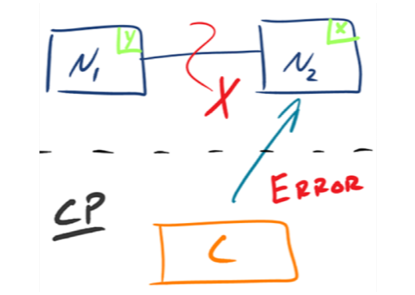
1)CP
如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
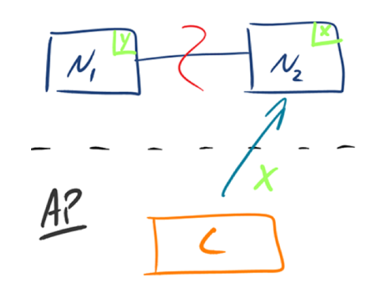
2) AP - Availability/Partition Tolerance
如下图所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
在面对网络分区时,Kubernetes 通常选择优先保证一致性和分区容忍性,而在某些情况下可能会暂时牺牲部分可用性。
如果一个 Kubernetes 集群分布在多个地理位置,某个位置与其他位置之间的网络连接中断,Etcd 将优先保证数据一致性,可能暂时无法进行新的写操作或在某些情况下无法响应读请求,直到网络分区恢复。
CAP原则的三选二是一个理论上的指导,但在实际工程中,我们可以通过多种策略和技术手段来最大化系统在一致性、可用性和分区容忍性三个方面的表现,构建高效可靠的分布式系统。
CAP细节
CAP 关注的粒度是数据,而不是整个系统
以一个最简单的用户管理系统为例,用户管理系统包含用户账号数据(用户 ID、密码)、用户信息数据(昵称、兴趣、爱好、性别、自我介绍等)。通常情况下,用户账号数据会选择 CP,而用户信息数据会选择 AP,如果限定整个系统为 CP,则不符合用户信息数据的应用场景;如果限定整个系统为 AP,则又不符合用户账号数据的应用场景。
每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
FMEA (Failure mode and effects analysis,故障模式与影响分析)
当我们设计出架构后,再用FMEA去分析
就是列表遇见问题,想出解决方案
2、高可用存储架构:双机架构
如何应对复制延迟和复制中断导致的数据不一致
主备(人工切换主机,备机的角色)
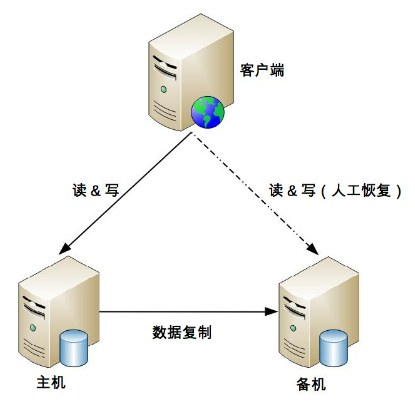
主从(从负责读)

还有双机切换等等
3、高可用存储架构:集群和分区
单机存储不了的时候,就需要多台了
一主多备集群
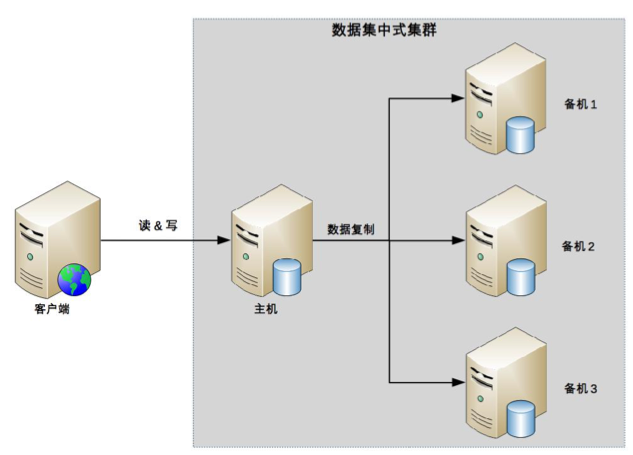
主机故障后,如何决定新的主机
目前开源的数据集中集群以 ZooKeeper 为典型,ZooKeeper 通过 ZAB 算法来解决上述提到的几个问题,但 ZAB 算法的复杂度是很高的。
数据集中集群架构中,客户端只能将数据写到主机;数据分散集群架构中,客户端可以向任意服务器中读写数据。正是因为这个关键的差异,决定了两种集群的应用场景不同。一般来说,数据集中集群适合数据量不大,集群机器数量不多的场景。例如,ZooKeeper 集群,一般推荐 5 台机器左右,数据量是单台服务器就能够支撑;而数据分散集群,由于其良好的可伸缩性,适合业务数据量巨大、集群机器数量庞大的业务场景。例如,Hadoop 集群、HBase 集群,大规模的集群可以达到上百台甚至上千台服务器。
数据分区
发生大灾,水灾,停电,大地震等等,一个地区的机房全部瘫痪,此时就需要数据分区恢复数据
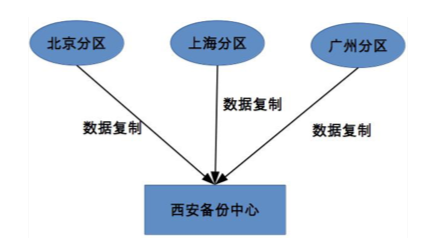


4、如何设计计算高可用架构?
部分硬件坏时,计算仍能正常运行
复杂度在于某台服务器上执行失败后,如何重新分配到其他机器上执行
5、应对接口级故障
接口级故障的典型表现就是系统并没有宕机,网络也没有中断,但业务却出现问题了。例如,业务响应缓慢、大量访问超时、大量访问出现异常(给用户弹出提示“无法连接数据库”),这类问题的主要原因在于系统压力太大、负载太高,导致无法快速处理业务请求,由此引发更多的后续问题。例如,最常见的数据库慢查询将数据库的服务器资源耗尽,导致读写超时,业务读写数据库时要么无法连接数据库、要么超时,最终用户看到的现象就是访问很慢,一会访问抛出异常,一会访问又是正常结果。
降级
降级指系统将某些业务或者接口的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能。例如,论坛可以降级为只能看帖子,不能发帖子;也可以降级为只能看帖子和评论,不能发评论;而 App 的日志上传接口,可以完全停掉一段时间,这段时间内 App 都不能上传日志。
降级的核心思想就是丢车保帅,优先保证核心业务。例如,对于论坛来说,90% 的流量是看帖子,那我们就优先保证看帖的功能;对于一个 App 来说,日志上传接口只是一个辅助的功能,故障时完全可以停掉。
熔断
假设一个这样的场景:A 服务的 X 功能依赖 B 服务的某个接口,当 B 服务的接口响应很慢的时候,A 服务的 X 功能响应肯定也会被拖慢,进一步导致 A 服务的线程都被卡在 X 功能处理上,此时 A 服务的其他功能都会被卡住或者响应非常慢。这时就需要熔断机制了,即:A 服务不再请求 B 服务的这个接口,A 服务内部只要发现是请求 B 服务的这个接口就立即返回错误,从而避免 A 服务整个被拖慢甚至拖死。
限流
降级是从系统功能优先级的角度考虑如何应对故障,而限流则是从用户访问压力的角度来考虑如何应对故障。限流指只允许系统能够承受的访问量进来,超出系统访问能力的请求将被丢弃。
例如某个直播间限制总用户数上限为 100 万,超过 100 万后新的用户无法进入;某个抢购活动商品数量只有 100 个,限制参与抢购的用户上限为 1 万个,1 万以后的用户直接拒绝
排队
排队实际上是限流的一个变种,限流是直接拒绝用户,排队是让用户等待一段时间,全世界最有名的排队当属 12306 网站排队了。排队虽然没有直接拒绝用户,但用户等了很长时间后进入系统,体验并不一定比限流好。
由于排队需要临时缓存大量的业务请求,单个系统内部无法缓存这么多数据,一般情况下,排队需要用独立的系统去实现,例如使用 Kafka 这类消息队列来缓存用户请求。
6、可扩展性
首先 拆— 流程 服务 功能(就是服务的细节)来考虑架构。拆分后哪个部分出错,范围不会波及太广
这几个系统架构并不是非此即彼的,而是可以在系统架构设计中进行组合使用的。以学生管理系统为例,我们最终可以这样设计架构:
1)整体系统采用面向服务拆分中的“微服务”架构,拆分为“注册服务”“登录服务”“信息管理服务”“安全服务”,每个服务是一个独立运行的子系统。
2)其中的“注册服务”子系统本身又是采用面向流程拆分的分层架构。
3)“登录服务”子系统采用的是面向功能拆分的“微内核”架构。
分层架构
分层架构是很常见的架构模式,它也叫 N 层架构,通常情况下,N 至少是 2 层。例如,C/S 架构、B/S 架构。常见的是 3 层架构(例如,MVC、MVP 架构)、4 层架构,5 层架构的比较少见,一般是比较复杂的系统才会达到或者超过 5 层,比如操作系统内核架构。
SOA和微服务
SOA 更加适合于庞大、复杂、异构的企业级系统,这也是 SOA 诞生的背景。这类系统的典型特征就是很多系统已经发展多年,采用不同的企业级技术,有的是内部开发的,有的是外部购买的,无法完全推倒重来或者进行大规模的优化和重构。因为成本和影响太大,只能采用兼容的方式进行处理,而承担兼容任务的就是 ESB。
微服务更加适合于快速、轻量级、基于 Web 的互联网系统,这类系统业务变化快,需要快速尝试、快速交付;同时基本都是基于 Web,虽然开发技术可能差异很大(例如,Java、C++、.NET 等),但对外接口基本都是提供 HTTP RESTful 风格的接口,无须考虑在接口层进行类似 SOA 的 ESB 那样的处理。
微服务要和devops一起 “快速交付” 才行,否则超过20个微服务,部署成本太高

通过前面的详细分析和比较,似乎微服务本质上就是一种比 SOA 要优秀很多的架构模式,那是否意味着我们都应该把架构重构为微服务呢?
其实不然,SOA 和微服务是两种不同理念的架构模式,并不存在孰优孰劣,只是应用场景不同而已。我们介绍 SOA 时候提到其产生历史背景是因为企业的 IT 服务系统庞大而又复杂,改造成本很高,但业务上又要求其互通,因此才会提出 SOA 这种解决方案。如果我们将微服务的架构模式生搬硬套到企业级 IT 服务系统中,这些 IT 服务系统的改造成本可能远远超出实施 SOA 的成本。
微服务的缺点
分的太细,系统复杂度指数级增长
调用链太长,性能下降
调用链太长,问题定位困难
微服务的应该怎么用
1个服务对应3人
首先,从系统规模来讲,3 个人负责开发一个系统,系统的复杂度刚好达到每个人都能全面理解整个系统,又能够进行分工的粒度;如果是 2 个人开发一个系统,系统的复杂度不够,开发人员可能觉得无法体现自己的技术实力;如果是 4 个甚至更多人开发一个系统,系统复杂度又会无法让开发人员对系统的细节都了解很深。
其次,从团队管理来说,3 个人可以形成一个稳定的备份,即使 1 个人休假或者调配到其他系统,剩余 2 个人还可以支撑;如果是 2 个人,抽调 1 个后剩余的 1 个人压力很大;如果是 1 个人,这就是单点了,团队没有备份,某些情况下是很危险的,假如这个人休假了,系统出问题了怎么办?
最后,从技术提升的角度来讲,3 个人的技术小组既能够形成有效的讨论,又能够快速达成一致意见;如果是 2 个人,可能会出现互相坚持自己的意见,或者 2 个人经验都不足导致设计缺陷;如果是 1 个人,由于没有人跟他进行技术讨论,很可能陷入思维盲区导致重大问题;如果是 4 个人或者更多,可能有的参与的人员并没有认真参与,只是完成任务而已。
“三个火枪手”的原则主要应用于微服务设计和开发阶段,如果微服务经过一段时间发展后已经比较稳定,处于维护期了,无须太多的开发,那么平均 1 个人维护 1 个微服务甚至几个微服务都可以。当然考虑到人员备份问题,每个微服务最好都安排 2 个人维护,每个人都可以维护多个微服务。
基础设施们

要做好微服务,这些基础设施都是必不可少的,否则微服务就会变成一个焦油坑,让业务和团队在里面不断挣扎且无法自拔。因此也可以说,微服务并没有减少复杂度,而只是将复杂度从 ESB 转移到了基础设施。
虽然建设完善的微服务基础设施是一项庞大的工程,但也不用太过灰心,认为自己团队小或者公司规模不大就不能实施微服务了。第一个原因是已经有开源的微服务基础设施全家桶了,例如大名鼎鼎的 Spring Cloud 项目,涵盖了服务发现、服务路由、网关、配置中心等功能;第二个原因是如果微服务的数量并不是很多的话,并不是每个基础设施都是必须的。通常情况下,我建议按照下面优先级来搭建基础设施:
-
服务发现、服务路由、服务容错:这是最基本的微服务基础设施。
-
接口框架、API 网关:主要是为了提升开发效率,接口框架是提升内部服务的开发效率,API 网关是为了提升与外部服务对接的效率。
-
自动化部署、自动化测试、配置中心:主要是为了提升测试和运维效率。
-
服务监控、服务跟踪、服务安全:主要是为了进一步提升运维效率。
以上 3 和 4 两类基础设施,其重要性会随着微服务节点数量增加而越来越重要,但在微服务节点数量较少的时候,可以通过人工的方式支撑,虽然效率不高,但也基本能够顶住。
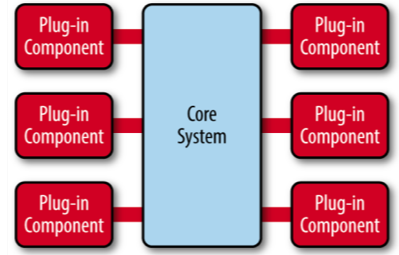
7、微内核架构
基本架构就是:核心系统(core system)和插件模块(plug-in modules)
OSGi
OSGi(Open Services Gateway initiative) 是一种用于 Java 平台的模块化系统和服务平台。它提供了一种动态的组件模型,使得应用程序可以被分解为许多小的、独立的模块(称为“bundles”),这些模块可以在运行时被安装、启动、停止、更新和卸载。OSGi 主要用于构建灵活、可扩展的应用程序和系统,尤其适用于需要长期运行的嵌入式系统、服务器和桌面应用程序。
OSGi 的核心概念
-
Bundles(捆绑包):
Bundles 是 OSGi 中的基本部署单元,相当于 Java 中的 JAR 文件。每个 bundle 包含一组相关的类和资源,并具有自己的生命周期管理。 -
Services(服务):
OSGi 平台提供一个动态服务注册和查找的框架,bundle 可以发布服务,也可以查找和使用其他 bundle 发布的服务。 -
Lifecycle Management(生命周期管理):
OSGi 提供一套标准的 API 用于管理 bundle 的生命周期,包括安装、启动、停止、更新和卸载。 -
Modules(模块):
OSGi 通过定义模块化系统,使得每个 bundle 可以有明确的依赖关系,并且能够实现版本管理和模块间的隔离。 -
Service Registry(服务注册表):
OSGi 平台维护一个全局的服务注册表,所有的 bundle 可以在这个注册表中发布和查找服务。
OSGi 的实际应用例子
1. Eclipse IDE
Eclipse 是一个流行的集成开发环境(IDE),它就是基于 OSGi 构建的。Eclipse 的插件系统使用 OSGi 来管理各种功能模块(如代码编辑器、调试工具、版本控制插件等)。每个功能模块都是一个 OSGi bundle,这使得 Eclipse 可以动态加载和卸载插件,提供一个高度可扩展和灵活的开发环境。
举例:
- 开发者可以在使用 Eclipse 时动态安装或卸载插件而无需重启 IDE。例如,安装一个新的版本控制插件(如 Git 插件)时,Eclipse 可以在后台加载该插件,并立即提供相应的功能。
2. Apache Karaf
Apache Karaf 是一个基于 OSGi 的轻量级容器,旨在运行 OSGi bundles。Karaf 提供了许多管理和部署 OSGi 应用的工具,如命令行控制台、远程管理、动态配置管理等。
举例:
- 在一个企业应用中,开发人员可以将不同的业务模块(如用户管理、订单处理、报告生成等)打包为独立的 OSGi bundles,并部署在 Karaf 容器中。业务需求变化时,可以动态更新或替换某个模块,而不会影响整个应用的运行。
3. 家庭自动化系统
OSGi 被广泛应用于智能家居系统中,这些系统通常由许多不同的设备和服务组成,需要高度的灵活性和可扩展性。例如,一个家庭自动化系统可以包含照明控制、安全监控、温度调节等功能,每个功能都可以作为一个独立的 OSGi bundle。
举例:
- 用户可以在智能家居系统中添加新的设备(如智能灯泡、温控器等),相应的 OSGi bundle 会动态加载并注册新的服务,使得这些设备能够与现有系统无缝集成。
通俗易懂的解释
可以把 OSGi 想象成一个大商场,每个商店就是一个 bundle。商场(OSGi 平台)提供基础设施来管理这些商店,包括店铺的开业、营业、关门、升级和撤销。每个商店独立经营,但可以相互提供和使用服务(例如,一家咖啡店可以使用隔壁打印店的打印服务)。如果需要引入新的店铺或升级某个店铺,整个商场不需要关闭,这样商场可以持续运营。















 2139
2139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









