










在我们读论文过程中,我们会有将PDF论文中的一些文字复制下来的需求,但因为PDF的特殊性,要么复制不出来,要么复制的有问题。通过OCR软件,我们可以通过现在的图形文字识别技术,将PDF的文字识别出来,方便我们使用。
这边我就推荐一下天若OCR吧,之前也是用的这个,感觉还是不错的。
官网下载地址:https://ocr.tianruo.net/
有条件的可以支持一下专业版
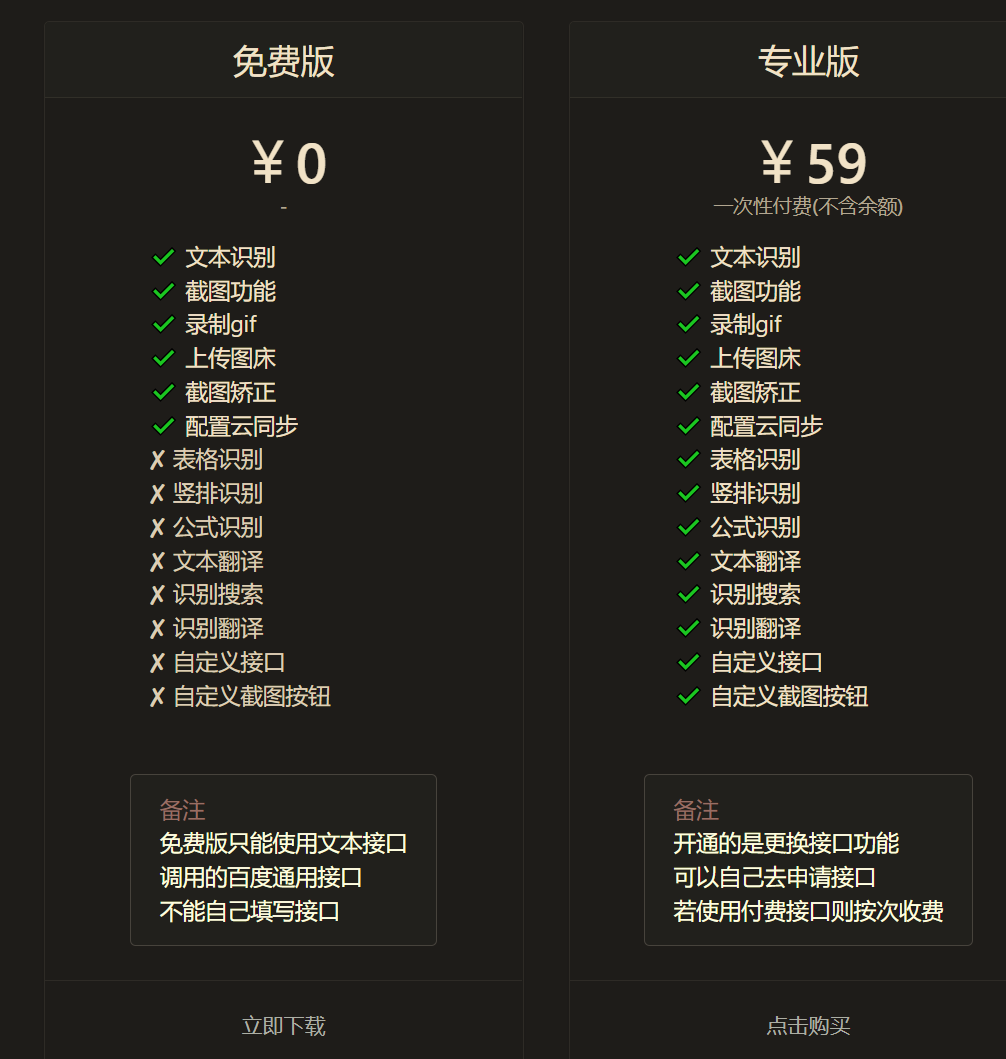
如果后面用的频繁的话,那我可能后面也会买一个支持一下。
这个软件用起来很简单,想看教程的可以点这教程。
而由于技术门槛相当的高,能做中文OCR识别的公司并不多,所以那些独立开发者开发的OCR软件,一般都是借用大公司的API接口。
因此,天若OCR提供了不同的接口(要收费的)。
关于接口的申请和配置请看这里接口申请和配置
下面通过识别一段PDF论文中的文字来测试一下:

识别还是很准确且速度也很快,体验不错!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











