








kfold和StratifiedKFold 用法
两者区别
代码及结果展示
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
#定义一个数据集
img_dataset=[[0,0],[1,1],[2,2],[3,3],[4,4],[5,5],[6,6],[7,7],[8,8],[9,9]]
img_label=[0,0,0,0,1,1,1,1,1,1]
#非随机的kfold
kfolds = KFold(n_splits=2, shuffle=False)
for train_index_ls,val_index_ls in kfolds.split(img_dataset,img_label):
print("train_index_ls=%s,val_index_ls=%s"%(train_index_ls,val_index_ls))
for train_img_index in train_index_ls:
print("img=%s,label=%s"%(img_dataset[train_img_index],img_label[train_img_index]))
train_index_ls=[5 6 7 8 9],val_index_ls=[0 1 2 3 4]
img=[5, 5],label=1
img=[6, 6],label=1
img=[7, 7],label=1
img=[8, 8],label=1
img=[9, 9],label=1
train_index_ls=[0 1 2 3 4],val_index_ls=[5 6 7 8 9]
img=[0, 0],label=0
img=[1, 1],label=0
img=[2, 2],label=0
img=[3, 3],label=0
img=[4, 4],label=1
#随机生成kflod
kfolds = KFold(n_splits=2, shuffle=True)
for train_index_ls,val_index_ls in kfolds.split(img_dataset,img_label):
print("train_index_ls=%s,val_index_ls=%s"%(train_index_ls,val_index_ls))
for train_img_index in train_index_ls:
print("img=%s,label=%s"%(img_dataset[train_img_index],img_label[train_img_index]))
train_index_ls=[0 1 3 5 9],val_index_ls=[2 4 6 7 8]
img=[0, 0],label=0
img=[1, 1],label=0
img=[3, 3],label=0
img=[5, 5],label=1
img=[9, 9],label=1
train_index_ls=[2 4 6 7 8],val_index_ls=[0 1 3 5 9]
img=[2, 2],label=0
img=[4, 4],label=1
img=[6, 6],label=1
img=[7, 7],label=1
img=[8, 8],label=1
#非随机生成stratifiedKFolds
stratifiedKFolds = StratifiedKFold(n_splits=2, shuffle=False)
for train_index_ls,val_index_ls in stratifiedKFolds.split(img_dataset,img_label):
print("train_index_ls=%s,val_index_ls=%s"%(train_index_ls,val_index_ls))
for train_img_index in train_index_ls:
print("img=%s,label=%s"%(img_dataset[train_img_index],img_label[train_img_index]))
train_index_ls=[2 3 7 8 9],val_index_ls=[0 1 4 5 6]
img=[2, 2],label=0
img=[3, 3],label=0
img=[7, 7],label=1
img=[8, 8],label=1
img=[9, 9],label=1
train_index_ls=[0 1 4 5 6],val_index_ls=[2 3 7 8 9]
img=[0, 0],label=0
img=[1, 1],label=0
img=[4, 4],label=1
img=[5, 5],label=1
img=[6, 6],label=1
结果分析
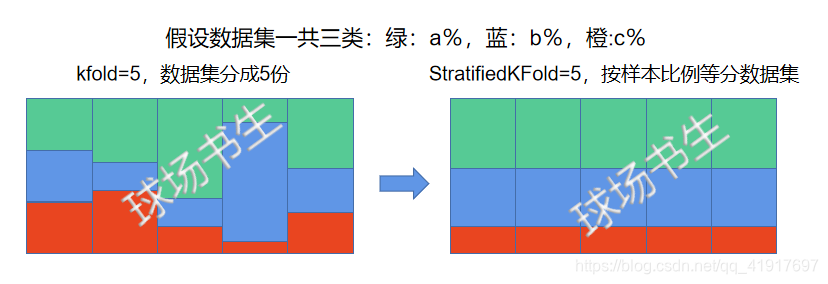
1.K折,会将数据集分成K份,同时会将(k-1)份作为训练集,剩余1份作为验证集。一共会有K个组合,即每一份都会有机会作为验证集。
2.如果不打乱顺序,会先抽出验证集,剩下的作为训练集。以此往后,得到K个组合。
3.StratifiedKFold会从每一个类比中,等比例的划分每一折,即每一折里的类别比例都是一样的。
补充:random_state(随机状态)
stratifiedKFolds = StratifiedKFold(n_splits=2, shuffle=True)
每次的分组都不太一样:
val_index_ls=[0 1 4 5 6] 、val_index_ls=[2 3 4 5 6]
val_index_ls=[0 3 4 6 7]、val_index_ls=[1 2 5 8 9]
stratifiedKFolds = StratifiedKFold(n_splits=2, shuffle=True,random_state=776)
每次的分组都一样:
val_index_ls=[1 3 5 6 7]、val_index_ls=[0 2 4 8 9]
val_index_ls=[1 3 5 6 7]、val_index_ls=[0 2 4 8 9]
如果不设置random_state的话,则每次构建的模型是不同的。
每次生成的数据集是不同的,每次拆分出的训练集、测试集是不同的,所以根据需求而定。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









