







1 数据集标签转化
MMDetection目标检测框架采用的数据集格式是COCO格式,为了采用COCODataset 类来加载数据并进行训练以及评测,需要将VisDrone数据集转换为COCO格式,可参考VisDrone数据集转COCO格式数据集
1.1 COCO数据集格式介绍
MS COCO 是google 开源的大型数据集, 分为目标检测、分割、关键点检测三大任务, 数据集主要由图片和json 标签文件组成。 对于目标检测,json文件的格式主要如下:
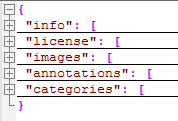
其中共包括6个字段,实际应用中,info和license字段用不上。
对于本实验转化后的数据集包括4个字段

images字段又包括4项字段
- filename:图片名
- height:高
- width:宽
- id
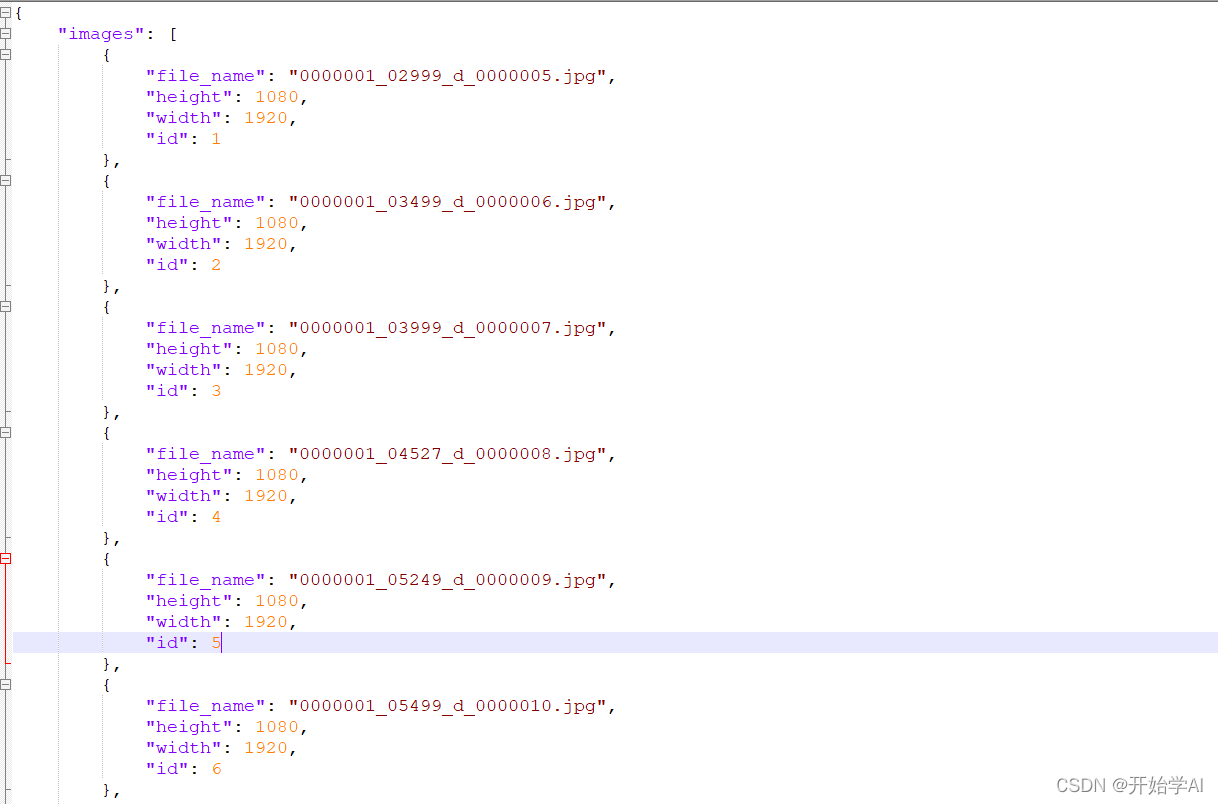
其中最重要的是id字段,代表的是图片的id,每一张图片具有唯一的一个独特的id。
annotations字段包含多个annotation实例的一个列表,annotation类型本身又包含了一系列的字段,如这个目标的category id和segmentation mask。segmentation格式取决于这个实例是一个单个的对象(即iscrowd=0,将使用polygons格式)还是一组对象(即iscrowd=1,将使用RLE格式)

- id字段:指的是这个annotation的一个id
- image_id:等同于前面image字段里面的id。
- category_id:类别id
- segmentation:用于分割
- area:标注区域面积
- bbox:标注框,左上角坐标 标注框宽和高
- iscrowd:决定是RLE格式还是polygon格式。
categories字段的id数,就是类别数。
- id:类别id
- name:类别id对应的名字
1.2 上传数据集并解压
已按照前文进行了标签转化,前文已在矩池云配置了MMDetection,为了实现在训练,将处理好的数据集上传。
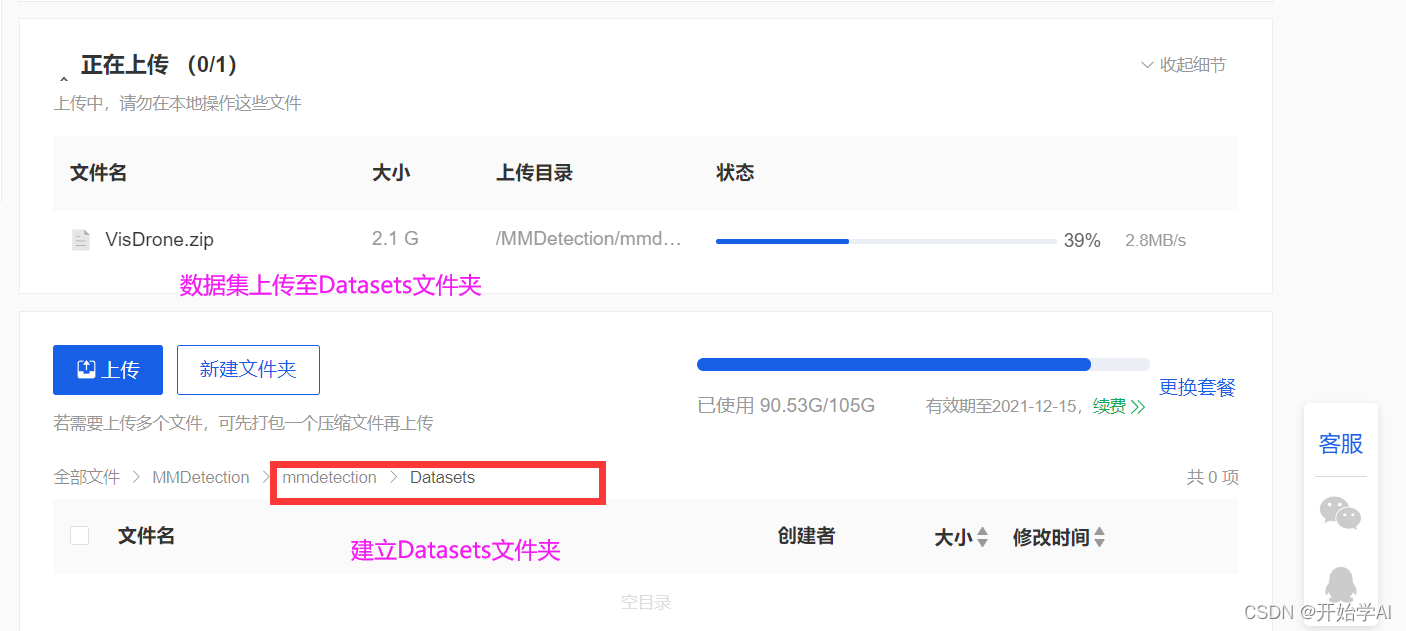
上传过程漫长,还是本地实验最舒服,好想拥有一块3090呀!
MMDetection 训练
解压文件,需要等待片刻
cd /mnt/MMDetection/mmdetection/Datasets
unzip VisDrone.zip
进入到工作目录
cd /mnt/MMDetection/mmdetection
选择模型以及调整配置文件,在configs文件夹下新建文件my_custom_config.py
在这里插入代码片

















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











