








Visual Instruction Tuning 论文阅读
论文地址:https://arxiv.org/pdf/2304.08485.pdf
项目地址:https://llava-vl.github.io
Abstract
背景:使用机器生成的指令跟随数据(machine-generated instruction-following data)对大语言模型(LLM)进行指令调整可以增强它的零样本能力。本文旨在将这种思想扩展到多模态领域。
本文的贡献:
-
展示了第一个基于
language-only GPT-4生成多模态指令跟随数据集。 -
基于上述数据集进行指令调整,构建了一个端到端训练的多模态大模型:
LLaVA(Large Language and Vision Assistant)模型。LLaVA模型通过连接视觉编码器和语言模型,实现了通用的视觉和语言理解能力。LLaVA具有不错的多模态对话能力,在未见过的图像和指令上有时达到多模态GPT-4的水准(85.1%的相对得分)。- 在Science QA数据集上进行微调后,
LLaVA和GPT-4的协同作用达到了92.53%的新的最高准确率。
-
论文提供了
GPT-4生成的视觉指导调优数据、模型和代码的公开可用性。
1. Instruction
人工智能的一个核心愿景之一是开发一种通用助手,能够有效地遵循多模态的视觉和语言指令,以满足人类的意图,在真实世界中完成各种任务。为了解决这个问题,最近社区对语言增强的基础视觉模型(language-augmented foundation vision model)表现出了极大的兴趣。
参考阅读列表:Computer Vision in the Wild 。当前的研究方向中,针对不同的任务,通常会使用一个独立的大型视觉模型来解决每个任务。在这些模型的设计中,任务指令通常被隐式地考虑进去,即针对不同的任务选择不同的模型进行实验。这样的方法可以得到不错的性能,但是固定的接口使得模型对用户的指令互动性不好。大语言模型已经证明了语言任务可以对基本任务提供通用的接口,即可以输入不同的指令来让模型完成不同的任务。但是现在的大语言模型是只针对文本的(text-only)。
在本文中作者团队实现了视觉指令调整(visual instruction-tuning) 将指令微调扩展到多模态空间,用于建立一个通用视觉辅助器( general-purpose visual assistant)。主要贡献如下:
-
多模态指令跟随数据集:提供了一个数据重构视角(perspective)和管道(pipeline),使用
ChatGPT/GPT-4来将图像-文本对转换为合适的指令跟随格式。 -
构建多模态大模型:连接了开集视觉编码器(
CLIP)和语言编码器(LLaMA),使用自行构建的数据集进行端对端微调。 -
我们向公众发布以下资产:生成的多模态指令数据、用于数据生成和模型训练的代码库、模型检查点和可视化聊天演示。
2. RelatedWork
Multimodal Instruction-following Agent
计算机视觉领域现有的构建指令跟随代理的工作大致可以分为两类:
- 端对端训练模型,被分散地在特定领域
- 借助
LangChain或LLM实现的协调多种模型的系统,例如ChatGPT,X-GPT,MM-REACT。
但是本文的目标是希望实现一个适用多个任务的端到端训练的多模态模型。
Instruction Tuning
指令调整的方法可以有效提高LLM在少样本和零样本的泛化能力,研究人员将这一思想从NLP领域扩展到CV领域。例如Flamingo。
然而,虽然这些模型在任务迁移泛化性能方面表现出有希望的成果,但它们并没有明确使用图像-语言指令数据进行指令调整。因此,本文旨在填补这一空白并研究其有效性。需要澄清的是,视觉指令调整与视觉提示调整是不同的:前者旨在提高模型的指令遵循能力,而后者旨在提高模型适应性中的参数效率。
3. GPT-assisted Visual Instruction Data Generation
这一部分介绍了使用ChatGPT/GPT-4,根据现有的图片对数据(image-pair data)收集指令跟随数据。作者团队收集了158,000个独特的语言-图像指令遵循样本,其中包括58,000个对话样本、23,000个详细描述样本和77,000个复杂推理样本。并且发现GPT-4模型可以生成更高质量的数据。
3.1 将图像-文本对扩展为指令跟随形式
以图像描述为例:由图像
X
v
\mathbf{X_v}
Xv,图像的标题
X
c
\mathbf{X_c}
Xc组成的二元组可以对应一系列问题
X
q
\mathbf{X_q}
Xq (由GPT-4生成,如Table 8 所示)来指示模型生成简单的描述。就可以将这个图像-文本对扩展为一个指令跟随数据:
Human : X_q, X_v <STOP>
Assistant : X_c <STOP>

这样的扩展在深度和广度上都是不足的,因此交互性很弱。为了解决这个问题,利用仅使用文本作为输入的GPT-4或ChatGPT作为强大的教师,创建涉及视觉内容的指令遵循数据。
3.2 向语言模型传递视觉信息
文章给出标题和边界框两种方法来将视觉信息传递给语言模型:
- 标题(Caption) 提供了不同的视角下对图像的描述,例如不同的物体之间的位置关系,或者其中的人物正在做什么。
- 边界框(Boxes) 定位了图像中的物体,以物体概念+位置信息的形式呈现(通常就是物体概念和矩形四个角的坐标构成)。

这样的表示可以把图像编码为可被机器识别的序列,作者在COCO图像数据集上生成了三种指令跟随数据,如下所示。对于每个类别,都是先手动设计一些样例,在利用GPT-4的上下文阅读能力来完成其他数据的生成。

三种数据形式包括对话(Conversation)、细节描述(detail description)和复杂推理(complex reasoning)。
生成对话数据
对话(Conversation) 形式的数据以人机对话的形式呈现,助手(Assistance)会回答人类提出的在图像上具有明确答案的视觉问题(包括物体类型、数量、动作、位置等)。用于生成数据的提示如下Table 10 所示。

生成细节描述
为了得到丰富而全面的描述,作者团队创建了一个问题列表,提示GPT-4然后筛选出了如Table 9 中所示的问题。对于每个问题,从列表中抽取一个询问GPT-4以生成详细描述。

生成复杂推理数据
上述二者关注视觉内容本身,基于对视觉内容的理解生成深层理解。答案通常遵循严格的逻辑进行推理。
4. Visual Instruction Tuning
4.1 Architecture
主要目标是有效利用预训练视觉模型和语言模型的能力,模型结构如下所示。
- 使用
LLaMA作为大语言模型 f ϕ ( ⋅ ) f_{\phi}(\cdot) fϕ(⋅) 。 - 采用
CLIP视觉编码器ViT/14得到图像的视觉特征 Z V = g ( X V ) \mathbf{Z_V}=g(\mathbf{X_V}) ZV=g(XV)。 - 使用线性投影矩阵 W V \mathbf{W_V} WV 将视觉特征转化成语言嵌入令牌(language embedding tokens) H q \mathbf{H_q} Hq。

本文提出的图像信息处理部分较为简单,仅使用线性投影矩阵,未来可优化的方向包括:
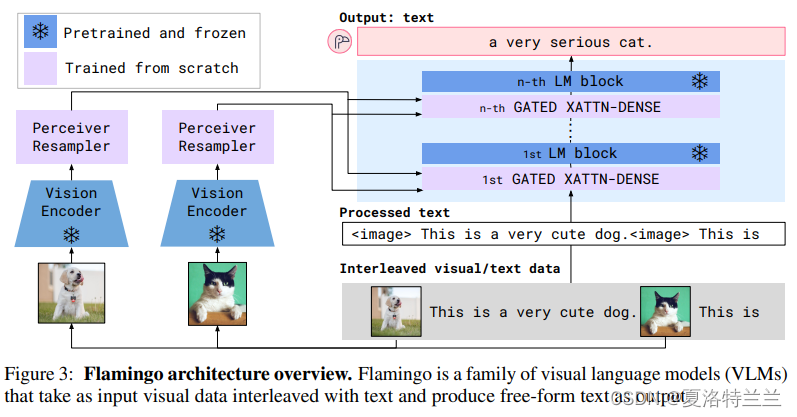
- 使用更复杂的模态桥接器,例如Flamingo中的门控交叉注意力和BLIP-2中的Q-former
- 使用对象级特征的视觉编码器,例如SAM。
4.2 Training
对于任意一个图像
X
V
\mathbf{X_V}
XV,生成一个
T
T
T 轮的问答数据序列
(
X
q
1
,
X
a
1
,
…
,
X
q
T
,
X
a
T
)
(\mathbf{X_q^1,X_a^1,\dots,X_q^T,X_a^T})
(Xq1,Xa1,…,XqT,XaT)。将每个回答(answer)当做机器的回复(response)。在第一轮对话中加入视觉信息,即使用视觉特征和语言向量的一种排列当做指令。总体而言,
X
i
n
s
t
r
u
c
t
i
o
n
t
\mathbf{X_{instruction}^t}
Xinstructiont 表示如下。
X
i
n
s
t
r
u
c
t
i
o
n
t
=
{
R
a
n
d
o
m
c
h
o
o
s
e
[
X
q
1
,
X
V
]
o
r
[
X
V
,
X
q
1
]
,
t
=
1
X
q
t
,
t
>
1
\mathbf{X_{instruction}^t}=\begin{cases} Random\ choose\ [\mathbf{X_{q}^1},\ \mathbf{X_{V}}]\ or\ [\mathbf{X_V},\ \mathbf{X_q^1}], & t = 1 \\ \mathbf{X_{q}^t}, &t > 1 \end{cases}
Xinstructiont={Random choose [Xq1, XV] or [XV, Xq1],Xqt,t=1t>1
将这些问答序列组合就可以得到如下的训练数据,因为只考虑生成内容和在哪里结束的问题,因此只有绿色部分会被用来计算损失。

使用模型初始的自回归函数来作为对LLM进行指令微调。对于长度为
L
L
L 的对话数据序列,计算可能的回答概率如下。其中强调了图像特征
X
V
\mathbf{X_V}
XV, 同时忽略了系统信息以及所有之前的<STOP>符号。
p
(
X
a
∣
X
V
,
X
i
n
s
t
r
u
c
t
)
=
∏
i
=
1
L
p
θ
(
x
i
∣
X
v
,
X
i
n
s
t
r
u
c
t
i
o
n
,
<
i
,
X
a
,
<
i
)
p(\mathbf{X_a}|\mathbf{X_V},\mathbf{X_instruct})=\prod_{i=1}^L p_{\theta}(x_i|\mathbf{X_v},\mathbf{X_{instruction,<i}}, \mathbf{X_{a,<i}})
p(Xa∣XV,Xinstruct)=i=1∏Lpθ(xi∣Xv,Xinstruction,<i,Xa,<i)
上面提到的系统信息是指
X
s
y
s
t
e
m
−
m
e
s
s
a
g
e
\mathbf{X_{system-message}}
Xsystem−message,是系统将要执行的任务,如下所示。
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human’s questions. and <STOP> = ###
对于LLaVA模型的训练,考虑两个指令调整的过程:模态特征对齐的预训练和端到端微调。
Stage1: Pre-training for Feature Alignment
这个过程用于训练将视觉特征和文本特征进行融合,也可以视作为冻结的LLM训练一个兼容的视觉标记器(visual tokenizer)。
使用的数据集
Conceptual Captions 3M数据集包含了300万个图像和对应的文本描述。每个图像都有一个与之相关联的自然语言描述,这些描述是通过人工标注生成的。这些描述通常涵盖了图像中的内容、场景、对象和活动等信息。
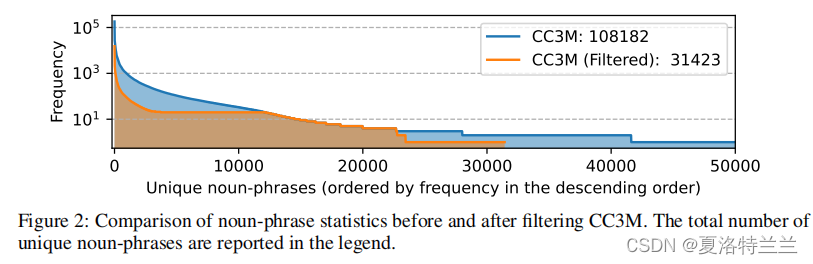
为了平衡概念覆盖和训练效率,从CC3M中筛选出了595K个图像-文本对。在筛选过程中先使用Spacy提取了整个CC3M数据集中每个标题(图片描述)的名词短语的频率并除去频率小于3的名词短语(罕见组合)。将剩下的短语按频率升序排列并加入包含短语的标题,当名词频率大于100时只挑选其中100条标题。筛选前后的数据如下图所示,因为在将句子加到数据集中的时候会包含一些其他词汇,所以仍会有部分罕见组合出现。
特征对齐的方法
选取Table 8 中的一些问题(要求机器描述这个图像)作为输入的
X
q
\mathbf{X_q}
Xq,将数据集中的标题(图像描述)作为回答
X
a
\mathbf{X_a}
Xa。然后冻结图像编码器和语言模型,训练投影矩阵
W
\mathbf{W}
W 直到似然函数达到极大。
Stage2: Fine-tuning End-to-End
这一阶段冻结视觉编码器,并更新LLaVA模型的投影层和LLM,训练参数是
θ
=
{
W
,
ϕ
}
\theta=\{\mathbf{W},\ \phi\}
θ={W, ϕ}。考虑一下两种特殊场景。
- 多模态聊天机器人(Multimodal Chatbot)将 §3 中收集的158K独特的语言图像指令按照三种回答格式(对话、详细描述和复杂推理)进行均匀抽样并基于这些数据进行微调得到聊天机器人。
- 科学问答(Science QA)在
Science QA基准数据集上进行,通过将问题和上下文作为输入,将推理过程和答案作为输出进行训练。
Appendix
§ 1 CLIP:Contrastive Language-Image Pre-Training
论文题目:Learning Transferable Visual Models From Natural Language Supervision
项目地址:https://github.com/OpenAI/CLIP
§ 1 LLaMA: a collection of foundation language models ranging from 7B to 65B parameters.
论文题目:Open and Efficient Foundation Language Models
§ 2 Flamingo: a visual language model for few-shot learning.
论文题目:Flamingo: a Visual Language Model for Few-Shot Learning
§ 4.1 ViT-L/14:一种CLIP模型
论文题目:Learning Transferable Visual Models From Natural Language Supervision



















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











