









五分钟学会筛选优质货币基金
前言
大家好,我是程序员阿浪,由于在疫情期间,阿浪闲来无事想学习一些理财知识,做一下财富自由的白日梦(ε=(゜ロ゜;)┛,然后就报名了财富星课堂的一个关于基金和股票实操的微课,基金和股票花了大概1.6k+大洋,本来还有保险的实操课,但是感觉个人在近期应该用不到,所以就只学了基金和股票的课程,但是也很贵4不4.
为什么要引出这个背景呢,因为要证明接下来的基金筛选是有科学依据哒hhhhh,可不是随便按照什么指标乱爬一通。但是呢,本文筛选出来的基金结果不构成投资建议,因为荐股犯法( ̄▽ ̄)",小伙伴们也不要听信什么荐股群,只有自己真正学到了理财的知识,才知道自己投哪只基金/股票,如果盲目的跟着别人投,是很容易被市场割韭菜的。
PS:基金训练营毕业证书 ✌ 至于如果有朋友想问我这门课的质量如何,可以去我的公众号给我留言私信。这里还是以爬虫教程为主。

这篇文章应该是基金类爬虫教程的第一篇文章,如果大家对这篇文章感兴趣,欢迎朋友们给文章点赞和关注我的微信公众号【THU小鱼干杂货铺】(可扫描文末二维码),如果备受宠爱(●ˇ∀ˇ●),我再发一篇债券基金的筛选与爬虫教程。
一、货币基金
1.什么是货币基金
货币基金的主要特点:
风险几乎是所有基金中的最低!(当然收益也是所有基金的最低( ̄_, ̄ )
安全性高、流动性强、收益较好、成本和门槛低
并且它主要用来管理活钱!即主要是平时吃喝玩乐用到的钱
常见的例子:
支付宝的余额宝、微信的零钱通
刚开始余额宝的收益率还很乐观,现在收益率已经拔凉拔凉了
如果你想选择收益率更高的货币基金,那么可以接着往下看。
2.如何筛选货币基金
四大指标,待我跟您逐一分析:

二、爬虫步骤(冲!
哦对了,如果对爬虫一窍不通的小白,建议去B站学(bai习(piao李巍老师的豆瓣电影爬取课程。
0.目标
爬取天天基金网上优质的货币基金相关信息,存入excel表格
1.引入库
代码如下(示例):
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #指定url,获取网页数据
import xlwt #进行excel操作
import json
import sqlite3 #进行SQLite数据库操作
2.准备爬虫需要的模块
2.1 URL访问模块
该模块主要通过构造浏览器客户端头部(伪装作用)发送request请求获取数据。
# 得到一个指定URL的网页内容
def askURL(url):
#head主要是伪装作用,用户代理,告诉服务器,我们是什么类型的浏览器
# 本质上是告诉浏览器我们可以接收什么类型的文件内容
head={
"Referer": "http://fund.eastmoney.com/data/hbxfundranking.html",
"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
# print(response.read().decode("utf-8"))
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if(hasattr(e,"code")):
print(e.code)
if(hasattr(e,"reason")):
print(e.reason)
return html
2.2 Json处理模块(网页异步加载需要)
#从html处理成标准json数据
def html2json(html):
dict = re.sub(r'^jQuery(.*?)\(', '',html)
return json.loads(dict[:-1])
2.3 正则表达式模块
findWanFenIncome = re.compile(r'<span class="ui-font-large ui-color-red ui-num">(.*?)</span>') #万份收益
findQiRiNianHuaIncome = re.compile(r'<span class="ui-font-middle ui-color-red ui-num">(.*?)</span>') #七日年化收益
findFundScale = re.compile(r'<td><a href=".*">基金规模</a>:(.*?)</td>') #基金规模
findPurchaseInfoUrl = re.compile(r'<a href="(.*?)">购买信息</a>') #基金购买信息超链接
findChiYouRenStructureUrl = re.compile(r'<a href="(.*?)">持有人结构</a>') #基金购买信息超链接
findFundLiquidity = re.compile(r'<td.*>买入确认日</td><td style=".*">(.*?)</td>') #买入确认日
findFundLiquidity1 = re.compile(r'<td.*>卖出确认日</td><td style=".*">(.*?)</td>') #卖出确认日
2.4 爬取天天基金网页模块(主要)
def getData(baseUrl):
tail_url = "&pageSize=50&callback=jQuery18307831678655611611_1596618935685&_=1596618935894"
datalist = []
for index in range(1,7): #获取1-6页的基金信息
url = baseUrl+str(index)+tail_url
html = askURL(url) #保存获取到的网页源码,实际是json字符串,格式见/test/temp.json
# 解析数据
dict = html2json(html) #网页源码转换为json数据
# print(dict)
for i in range(0,len(dict['Data'])):
print("当前爬取到第%d页,正在爬取%s的基金信息..."%(index,dict["Data"][i]["SHORTNAME"]))
fund_info = [] #保存一只基金的所有信息
#保存基金代码
fund_info.append(dict["Data"][i]["FCODE"])
#保存基金名称
fund_info.append(dict["Data"][i]["SHORTNAME"])
#保存基金28日年化收益率
fund_info.append(dict["Data"][i]["TEYI"])
#保存基金近3年年化收益率
if(dict["Data"][i]["SYL_3N"]!=""):
fund_info.append(dict["Data"][i]["SYL_3N"])
else:
fund_info.append(0)
'''保存完一只基金的基本信息后,进入基金详情页寻找基金规模、流动性、持有人结构信息'''
fund_url = "http://fund.eastmoney.com/"+str(dict["Data"][i]["FCODE"])+".html"
fund_html = askURL(fund_url)
# print(fund_html)
soup = BeautifulSoup(fund_html, "html.parser") # 将抓取的html网页转换为树形结构的文档
for item in soup.find_all('div', class_="fundInfoItem"): # 查找符合要求的字符串,形成列表
# print(item)
re_item = str(item) #转为字符串,用于正则表达式
wanfenIncome = re.findall(findWanFenIncome, re_item)[0]
# 保存基金每万份收益
fund_info.append(wanfenIncome)
qirinianhuaIncome = re.findall(findQiRiNianHuaIncome,re_item)[0]
# 保存基金七日年化收益
fund_info.append(qirinianhuaIncome)
fundscale = re.findall(findFundScale,re_item)[0]
# 保存基金规模
fund_info.append(fundscale)
#获取基金流动性,T+0或者T+1
purchaseInfoUrl = "http://fundf10.eastmoney.com/jjfl_"+str(dict["Data"][i]["FCODE"])+".html"
purchaseInfo_html = askURL(purchaseInfoUrl)
soup = BeautifulSoup(purchaseInfo_html, "html.parser")
item = soup.find_all('div', class_ ="boxitem w790")
re_item = str(item[2]) # item[2]表示交易确认日这个div
fundLiquidity = re.findall(findFundLiquidity, re_item)[0]
# 保存买入确认日
fund_info.append(fundLiquidity)
fundLiquidity1 = re.findall(findFundLiquidity1, re_item)[0]
# 保存卖出确认日
fund_info.append(fundLiquidity1)
# 获取持有人结构信息,散户比例>60%最好
chiYouRenStructureUrl = "http://fundf10.eastmoney.com/FundArchivesDatas.aspx?type=cyrjg&code="+str(dict["Data"][i]["FCODE"])
chiYouRenStructure_html = askURL(chiYouRenStructureUrl)
# print(chiYouRenStructure_html)
soup = BeautifulSoup(chiYouRenStructure_html, "html.parser")
item = soup.find_all('td', class_="tor")
personalHoldScale = item[1].string #item[1]表示最新的散户持有比例
# print(personalHoldScale)
# 保存散户持有比例
fund_info.append(personalHoldScale)
#一条基金的信息搜集完毕,存入总的datalist
datalist.append(fund_info)
return datalist
2.5 保存数据转存Excel模块
#保存数据
def saveData(datalist,savepath):
print("saving...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet("货币基金信息",cell_overwrite_ok=True) # 创建工作表单
col = ("基金代码","基金名称","28日年化收益率","近3年年化收益率","每万份日收益","七日年化收益","基金规模","买入确认日","卖出确认日","散户持有比例")
for i in range(0,10):
sheet.write(0,i,col[i]) #写一行列名
for i in range(0,len(datalist)):
print("第%d条."%(i+1))
data = datalist[i]
for j in range(0,10):
sheet.write(i+1,j,data[j])
book.save(savepath) # 保存数据表
print("saved.")
3 执行main函数
def main():
#hbxfundranking.html表示搜索货币基金排行
# sSYL_3N 表示近三年收益率
# mga;表示按起购金额筛选:100元起(A类)
baseurl = "http://api.fund.eastmoney.com/FundRank/GetHbRankList?intCompany=0&MinsgType=a&IsSale=1&strSortCol=SYL_3N&orderType=desc&pageIndex="
# 1.爬取网页,获取数据
datalist = getData(baseurl)
# 3.保存数据
savepath = "货币基金筛选表.xls"
saveData(datalist,savepath)
三、运行过程&结果展示
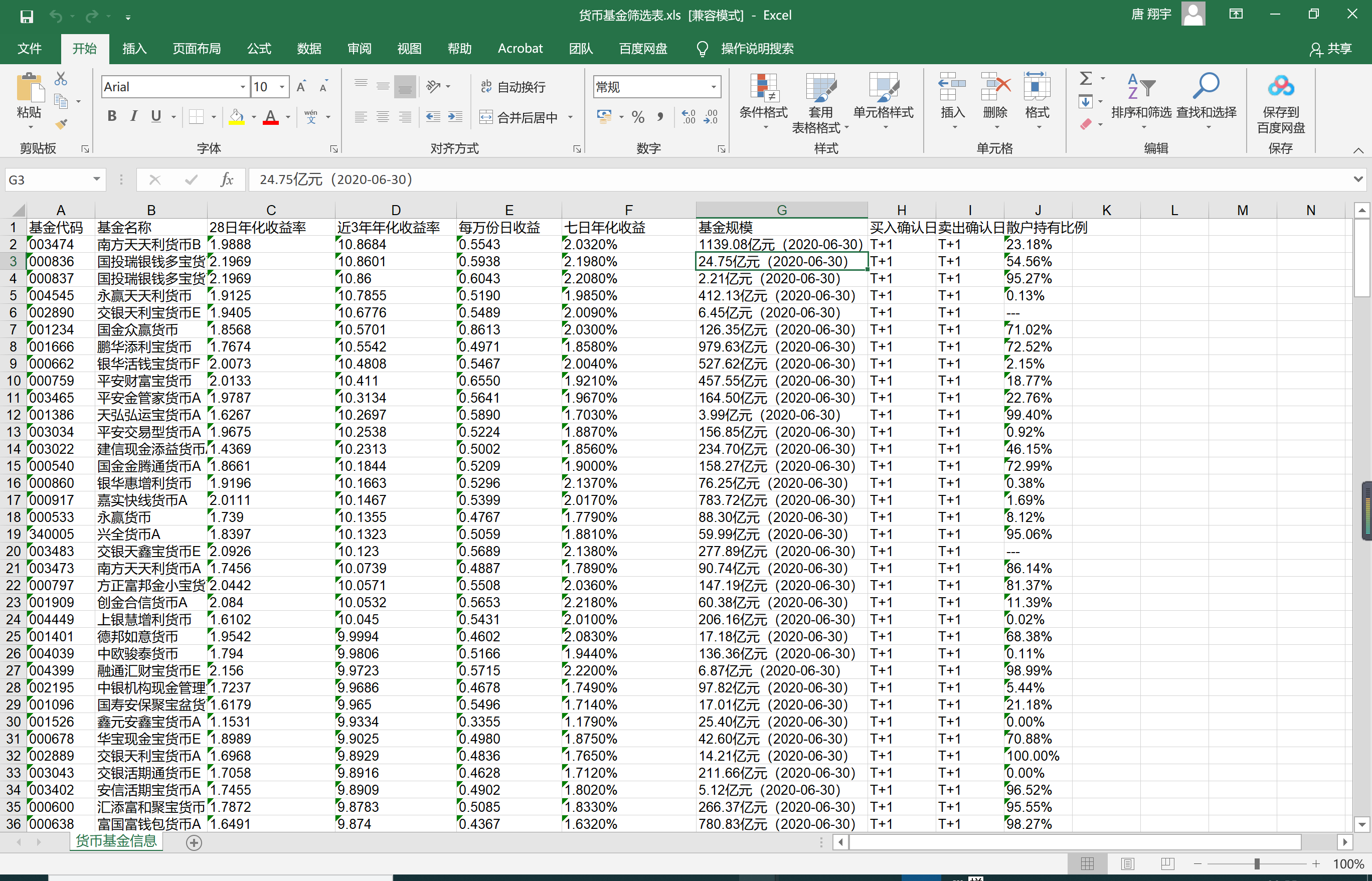
货币基金的关键指标已经罗列在表格中,接下来就看你看谁顺眼,然后梭哈买买买!
四、总结
本文主要对货币基金的筛选流程和爬虫实操进行了代码讲解,如果有需要最后输出筛选基金的表格和完整代码的朋友,可在我的公众号【THU小鱼干杂货铺】(微信号:DryGoodsShare)回复关键词【货币基金】获取。后期完善代码后我将把源码放入我的github仓库,码字不易,期待您的点赞、收藏和关注!(B站说:内心强大的人从不吝啬赞美和鼓励( •̀ ω •́ )✧)
大佬们的 【三连】 就是阿浪创作的最大动力,如果本篇博客有任何错误和建议,欢迎大佬们留言!
我是阿浪,对所有未知都要心存敬畏,永远保持一颗好奇心,我们下期见!


















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









