







情况:训练的时候调用这行代码不会报错,测试的时候会报错
报错代码定位:
mmtrack/models/motion/flownet_simple.py的def prepare_imgs(self, imgs, img_metas)函数的这一行:
mean = torch.tensor(mean, dtype=imgs.dtype, device=imgs.device)。
问题特点:device=imgs.device将mean放在cuda上计算,会报错,如果放在cpu上就不报错。
解决思路:将这行代码放在cpu上计算,计算之后再重新放回cuda。
这个函数改为:
def prepare_imgs(self, imgs, img_metas):
"""Preprocess images pairs for computing flow.
Args:
imgs (Tensor): of shape (N, 6, H, W) encoding input images pairs.
Typically these should be mean centered and std scaled.
img_metas (list[dict]): list of image information dict where each
dict has: 'img_shape', 'scale_factor', 'flip', and may also
contain 'filename', 'ori_shape', 'pad_shape', and
'img_norm_cfg'. For details on the values of these keys see
`mmtrack/datasets/pipelines/formatting.py:VideoCollect`.
Returns:
Tensor: of shape (N, 6, H, W) encoding the input images pairs for
FlowNetSimple.
"""
if not hasattr(self, 'img_norm_mean'):
mean = img_metas[0]['img_norm_cfg']['mean']
mean = torch.tensor(mean, dtype=imgs.dtype)#, device=imgs.device 【放在cpu上】
self.img_norm_mean = mean.repeat(2)[None, :, None, None]
mean = self.flow_img_norm_mean
mean = torch.tensor(mean, dtype=imgs.dtype)#, device=imgs.device 【放在cpu上】
self.flow_img_norm_mean = mean.repeat(2)[None, :, None, None]
if not hasattr(self, 'img_norm_std'):
std = img_metas[0]['img_norm_cfg']['std']
std = torch.tensor(std, dtype=imgs.dtype)#, device=imgs.device 【放在cpu上】
self.img_norm_std = std.repeat(2)[None, :, None, None]
std = self.flow_img_norm_std
std = torch.tensor(std, dtype=imgs.dtype)#, device=imgs.device 【放在cpu上】
self.flow_img_norm_std = std.repeat(2)[None, :, None, None]
flow_img = imgs * self.img_norm_std.cuda() + self.img_norm_mean.cuda()# 【重新放回cuda】
flow_img = flow_img / self.flow_img_norm_std.cuda() - self.flow_img_norm_mean.cuda()# 【重新放回cuda】
flow_img[:, :, img_metas[0]['img_shape'][0]:, :] = 0.0
flow_img[:, :, :, img_metas[0]['img_shape'][1]:] = 0.0
flow_img = torch.nn.functional.interpolate(
flow_img,
scale_factor=self.img_scale_factor,
mode='bilinear',
align_corners=False)
return flow_img
新情况:使用上面的方法使用调试工具pdb调通了,但重新跑测试代码,又出现了同样的错误RuntimeError: CUDA error: device-side assert triggered
问题解决:无意间发现,自定义数据集的frame_id是从1开始的,而在mmtracking官方给的代码的frame_id从0开始的,这就会导致后面很多判断语句的结果出错。
例如:mmtrack/datasets/coco_video_dataset.py中的类似语句都会错误:
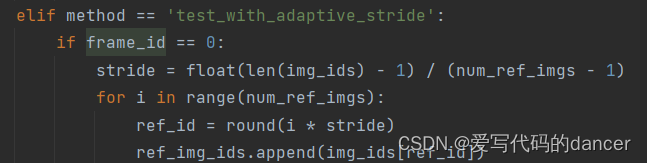
数据集重做很麻烦,因此,我决定修改相关的代码。在每个与frame_id有关的函数的开头就将frame_id-1即可,代码如下,问题解决。

总结:RuntimeError: CUDA error: device-side assert triggered这个报错,看起来是一个与cuda有关的问题,但实际上可能是代码撰写逻辑中存在问题。















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









