







简介
爬取新闻标题
1. 安装
pip install request
pip install fake_useragent
2. 演示
-
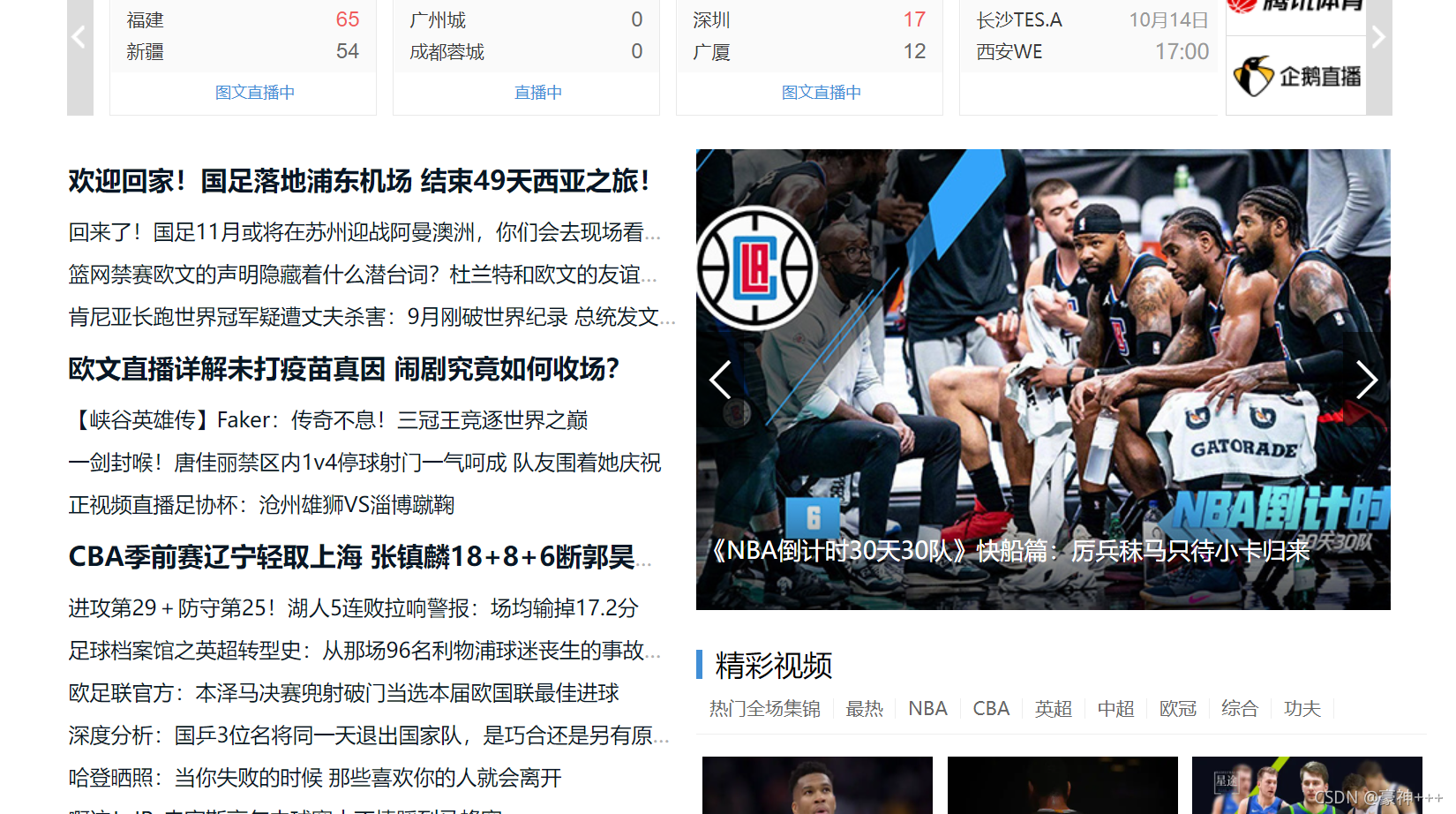
进入网址,查看网页源代码

-
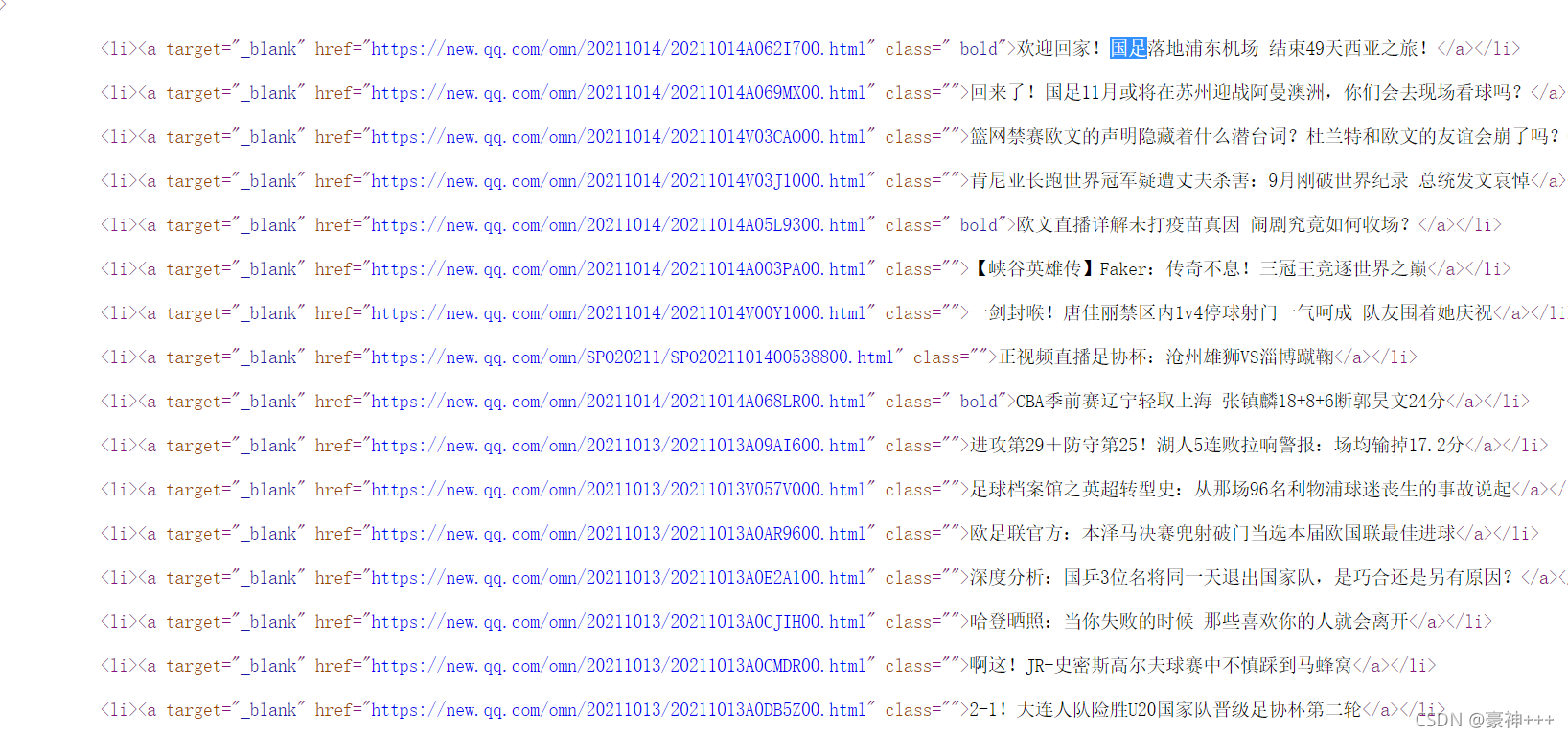
找到标题界面,根据li标签的特征使用re匹配
-
代码演示
import requests
from fake_useragent import UserAgent # 伪装请求头的库
import re
url = 'http://sports.qq.com/' # 腾讯体育新闻网址
headers = {'User-Agent': UserAgent().chrome}
response = requests.get(url, headers)
pattern = r'<li><a target="_blank" href="(.*?)" class="(.*?)">(.*?)</a></li>'
s = re.findall(pattern=pattern, string=response.text)
for content in s:
print(content[2])
print('--------完成-------')
- 结果















 1627
1627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









