










数据可视化是以图形格式呈现数据。这对于数据分析来说非常重要,主要是因为以数据为中心的Python包的奇妙生态系统。它有助于理解数据,但是,复杂的是,通过总结和以简单易懂的格式呈现大量数据来了解数据的重要性,并有助于清晰有效地传达信息。

Pandas和Seaborn就是其中之一,它使导入和分析数据变得更加容易。在本文中,我们将使用Pandas和Seaborn来分析数据。
Pandas
Pandas提供了清理和处理数据的工具。它是最流行的用于数据分析的Python库。在pandas中,数据表被称为数据框。
示例
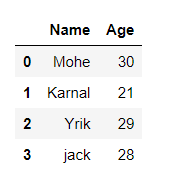
import pandas as pd
# initialise data of lists.
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
# Create DataFrame
df = pd.DataFrame( data )
# Print the output.
df
Seaborn
Seaborn是一个惊人的可视化库,用于在Python中绘制统计图形。它构建在matplotlib库之上,并与pandas的数据结构紧密集成。
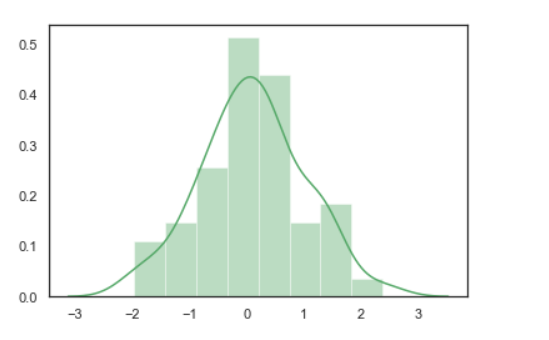
import numpy as np
import seaborn as sns
# Selecting style as white,
# dark, whitegrid, darkgrid
# or ticks
sns.set( style = "white" )
# Generate a random univariate
# dataset
rs = np.random.RandomState( 10 )
d = rs.normal( size = 50 )
# Plot a simple histogram and kde
# with binsize determined automatically
sns.distplot(d, kde = True, color = "g")
Seaborn:统计数据可视化
Seaborn有助于可视化统计关系,为了了解数据集中的变量如何相互关联以及这种关系如何依赖于其他变量,我们执行统计分析。此统计分析有助于可视化趋势并识别数据集中的各种模式。
以下图形将有助于可视化:
- 线形图
- 散点图
- 箱形图
- 散点图
- 计数图
- 小提琴图
- 群图
- 条形图
- KDE绘图
线形图
语法:sns.lineplot(x=None,y=None)
参数:
x、y:输入数据变量;必须是数字。可以直接传递数据或引用数据中的列。
示例1
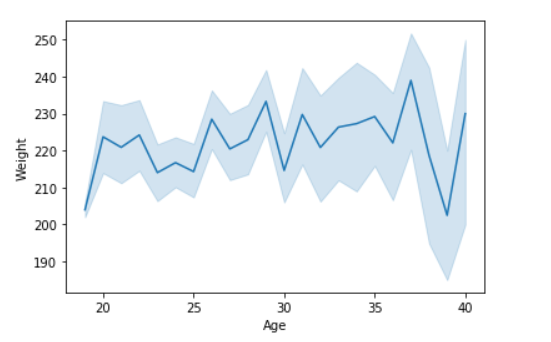
# import module
import seaborn as sns
import pandas
# loading csv
data = pandas.read_csv("nba.csv")
# plotting lineplot
sns.lineplot( data['Age'], data['Weight'])
示例2
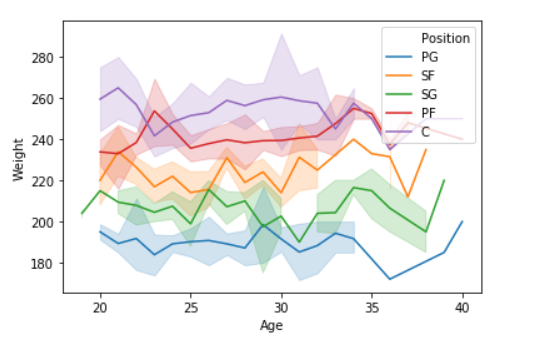
# import module
import seaborn as sns
import pandas
# read the csv data
data = pandas.read_csv("nba.csv")
# plot
sns.lineplot(data['Age'],data['Weight'], hue =data["Position"])
散点图
语法:seaborn.scatterplot(x=None,y=None)
参数:
x,y:输入数据变量,应为数值。
返回:此方法返回绘制了绘图的Axes对象。
示例1
# import module
import seaborn
import pandas
# load csv
data = pandas.read_csv("nba.csv")
# plotting
seaborn.scatterplot(data['Age'],data['Weight'])
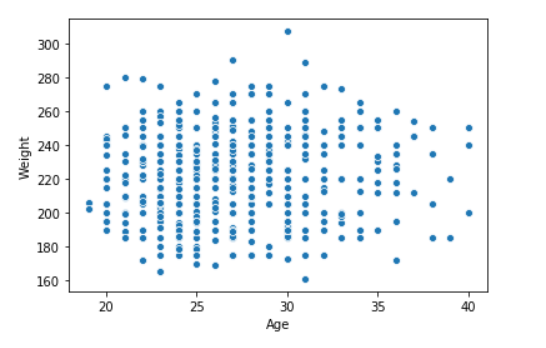
示例2
import seaborn
import pandas
data = pandas.read_csv("nba.csv")
seaborn.scatterplot( data['Age'], data['Weight'], hue =data["Position"])
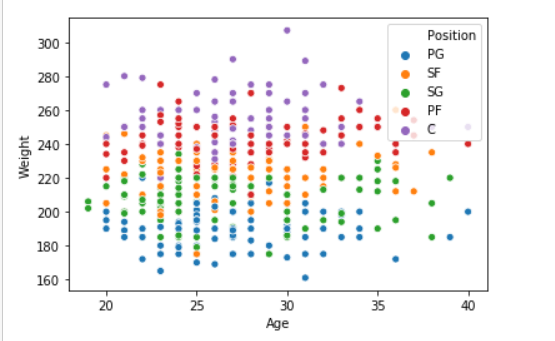
箱形图
语法:
seaborn.boxplot(x=None, y=None, hue=None, data=None)
参数:
x,y,hue:用于绘制长格式数据的输入。
data:用于绘图的数据集。如果x和y不存在,则这被解释为宽形式。
返回:它返回绘制了绘图的Axes对象。
示例1
# import module
import seaborn as sns
import pandas
# read csv and plotting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'] )
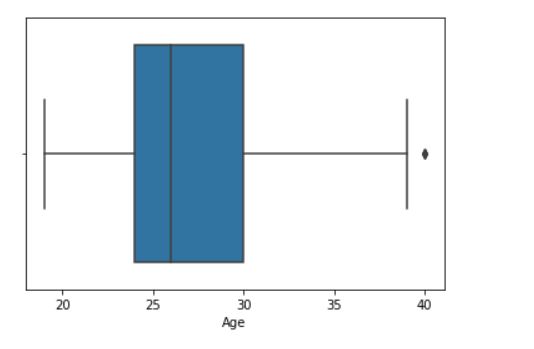
示例2
# import module
import seaborn as sns
import pandas
# read csv and plotting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Weight'])

小提琴图
语法:seaborn.violinplot(x=None,y=None,hue=None,data=None)
参数:
x,y,hue:用于绘制长格式数据的输入。
data:用于绘图的数据集。
示例1
# import module
import seaborn as sns
import pandas
# read csv and plot
data = pandas.read_csv("nba.csv")
sns.violinplot(data['Age'])
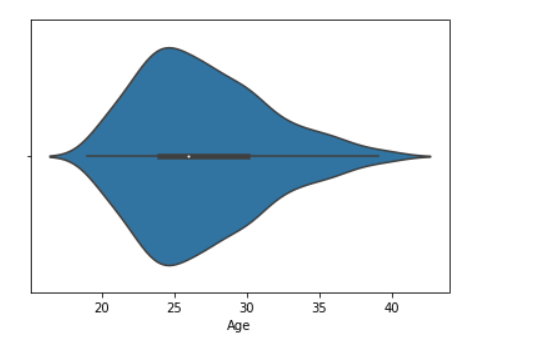
示例2
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.violinplot(x ="Age", y ="Weight",data = data)
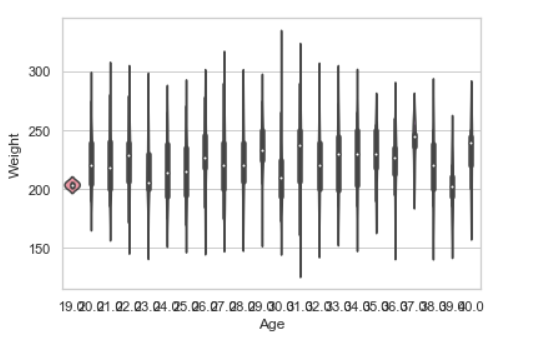
蜂群图
语法:seaborn.swarmplot(x=None,y=None,hue=None,data=None)
参数:
x,y,hue:用于绘制长格式数据的输入。
data:用于绘图的数据集。
示例1
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv( "nba.csv" )
seaborn.swarmplot(x = data["Age"])

示例2
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.swarmplot(x ="Age", y ="Weight",data = data)

条形图
语法:seaborn.barplot(x=None,y=None,hue=None,data=None)
参数:
x,y:该参数采用数据或矢量数据中的变量名称,用于绘制长格式数据的输入。
hue:(可选)该参数采用列名进行颜色编码。
data:(可选)该参数采用DataFrame、数组或数组列表、数据集进行绘图。如果x和y不存在,则这被解释为宽形式。否则,它将是长格式的。
返回:返回轴对象及其上绘制的图。
示例1
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x =data["Age"])
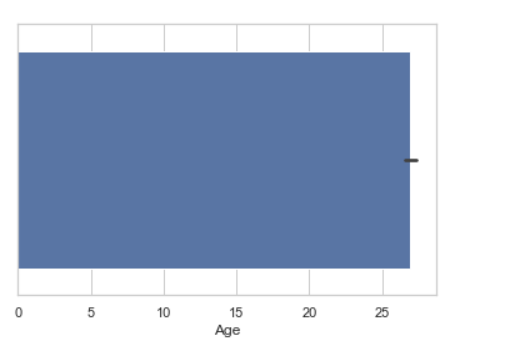
示例2
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x ="Age", y ="Weight", data = data)

点图
语法:seaborn.pointplot(x=None,y=None,hue=None,data=None)
参数:
x,y:用于绘制长格式数据的输入。
hue:(可选)颜色编码的列名。
data:dataframe作为用于绘图的数据集。
返回:绘制了图的轴对象。
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.pointplot(x = "Age", y = "Weight", data = data)
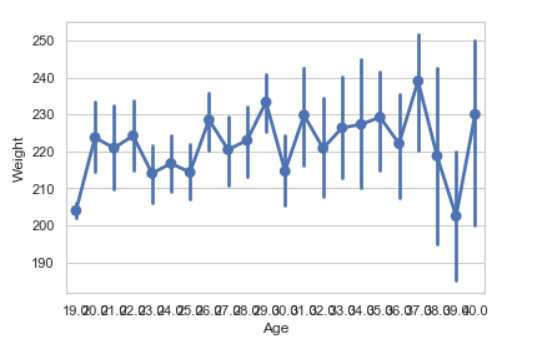
计数图
语法:seaborn.countplot(x=None,y=None,hue=None,data=None)
参数:
x,y:这个参数取数据或向量数据中变量的名称,可选,用于绘制长格式数据的输入。
hue:(可选)此参数采用列名称进行颜色编码。
data:(可选)该参数采用DataFrame、数组或数组列表、数据集进行绘图。如果x和y不存在,则这被解释为宽形式。否则,它将是长格式的。
返回:返回轴对象及其上绘制的图。
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.countplot(data["Age"])
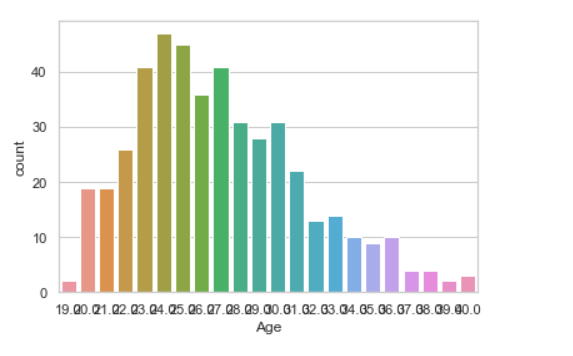
KDE图
语法:seaborn. kdeplot(x=None,*,y=None,vertical=False,palette=None,**kwargs)
参数:
x,y:数据中的向量或键
vertical:boolean(True或False)
data:pandas.DataFrame、numpy.ndarray、mapping或sequence
示例1
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
# Setting up the Data Frame
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length',
'Sepal_Width', 'Patal_Length', 'Petal_Width'])
iris_df['Target'] = iris.target
iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target'] =='Iris_Virginica'),
'Sepal_Length'], color = 'b', shade = True, Label ='Iris_Virginica')

示例2
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Number'])
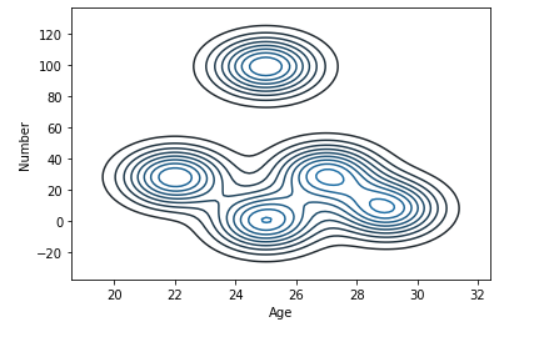
使用seaborn和pandas绘制双变量和单变量数据
在开始之前,让我们简单介绍一下双变量和单变量数据:
双变量数据:这种类型的数据涉及两个不同的变量。对这类数据的分析涉及原因和关系,并进行分析以找出两个变量之间的关系。
单变量数据:这种类型的数据只包含一个变量。因此,单变量数据的分析是最简单的分析形式,因为信息只涉及一个变化的量。它不处理原因或关系,分析的主要目的是描述数据并找到其中存在的模式。
让我们看一个二元数据的例子:
# import module
import seaborn as sns
import pandas
# read csv and plotting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Height'])

# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Weight'])
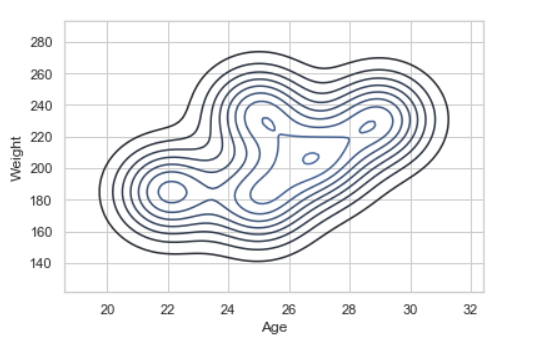
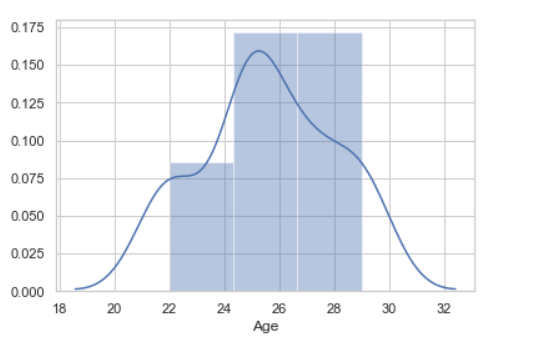
让我们看一个单变量数据分布的例子:
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.distplot( data['Age'])














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









