







CatBoost是一个缩写词,指的是“分类提升”,旨在在分类和回归任务中表现良好。CatBoost处理分类变量而不需要手动编码的能力是其主要优势之一。它采用了一种称为有序提升的方法来处理分类特征所面临的困难,如大基数。这使得CatBoost能够自动处理分类数据,节省用户的时间和精力。CatBoost的基本思想是能够有效地处理分类特征。它实现了一种名为有序提升的新技术,该技术通过排列分类变量来生成数值表示。该方法在保持类别信息的同时允许模型使用强大的梯度提升技术。
什么是CatBoost?
CatBoost是Yandex开发的尖端算法,是无缝,高效和令人兴奋的机器学习,分类和回归任务的首选解决方案。凭借其创新的有序提升算法,CatBoost通过利用决策树的力量将预测提升到新的高度。在本文中,您将探索catboost算法的工作原理。
CatBoost的主要功能
与CatBoost相关的主要功能如下:
- 梯度提升:它是一种功能强大的集成学习技术,它结合了弱预测模型(通常是决策树)来构建一个功能强大的预测模型。它的工作原理是迭代地将新模型添加到集合中,每个模型都经过训练以纠正先前模型所犯的错误。CatBoost使用梯度提升,通过关注错误分类的示例来提高模型的准确性。
- 分类特征:分类特征,如颜色或类型,是反映定性数据的变量。CatBoost有效地处理分类特征,而不需要大量的预处理或一次性编码,使其成为现实世界数据集的有效工具。
- 学习率:学习率控制模型在提升阶段学习的步长。为了平衡模型的学习速度和准确性,CatBoost会根据数据集特征自动选择理想的学习率。
- L2正则化:它也被称为岭正则化,在损失函数中引入惩罚项以防止过拟合并提高模型的泛化能力。在CatBoost的上下文中,L2正则化是一个关键特性,有助于控制提升树的复杂性。它通过在训练过程中使用的损失函数中添加正则化项来实现这一点。
Catboost如何工作
CatBoost是一种强大的梯度提升技术,专为机器学习任务而设计,特别是那些涉及结构化输入的任务。它利用了梯度提升的概念,这是一种集成学习方法。该算法首先进行初始猜测,通常是目标变量的平均值。然后,它逐渐构建决策树的集合,每棵树的目标是减少前一棵树的错误或残差。
CatBoost的主要优势之一是它能够有效地处理分类特征。它采用了一种称为“有序提升”的技术来直接处理分类数据,从而加快了训练速度并提高了模型性能。这是通过以保持类别的自然顺序的方式对类别特征进行编码来实现的。
为了防止过度拟合,CatBoost结合了正则化技术。这些技术在训练过程中引入了惩罚或约束,以阻止模型变得过于复杂和过于接近训练数据。正则化有助于泛化模型,使其对未知数据更具鲁棒性。
该算法通过使用梯度下降最小化损失函数来迭代地构造树的集合。在每次迭代中,它计算损失函数相对于当前预测的负梯度,并将新树拟合到负梯度。学习率决定了梯度下降过程中的步长。重复该过程,直到已经添加了预定数量的树或已经满足收敛标准。在进行预测时,CatBoost会将来自集合中所有树的预测组合在一起。这种预测的聚合导致高度准确和可靠的模型。
从数学上讲,
CatBoost可以表示如下:
给定具有N个样本和M个特征的训练数据t,其中每个样本表示为(x_i,y_i),因为x_i是M个特征的向量,y_i是对应的目标变量,CatBoost旨在学习预测目标变量y的函数F(x)。
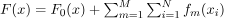
其中,
F(x)表示CatBoost旨在学习的整体预测函数。它接受一个输入向量x并预测相应的目标变量y。
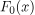
是最初的猜测或基线预测。它通常被设置为训练数据集中目标变量的平均值。此项捕获目标变量的总体平均行为。
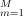
表示所有树的总和。M表示集合中的树的总数。
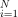
表示训练样本的总和。N表示训练样本的总数。
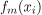
表示对第i个训练样本的第m棵树的预测。集合中的每棵树通过对每个训练样本进行自己的预测来对整体预测做出贡献。
该方程指出,通过将初始猜测F_0(x)与每个训练样本的每个树f_m(x_i)的预测相加,获得总体预测F(x)。对所有树(m)和所有训练样本(i)执行该求和。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











