







非线性回归是一种用于模拟变量之间复杂关系的强大工具。然而,离群值的存在可能会显着扭曲结果,导致参数估计不准确和预测不可靠。因此,检测离群值对于稳健的非线性回归分析至关重要。本文深入研究了在非线性回归中识别离群值的方法和技术,确保您获得可靠和准确的结果。
了解非线性回归
什么是非线性回归?
非线性回归是回归分析的一种形式,其中观测数据由模型参数的非线性组合函数建模,并取决于一个或多个自变量。与线性回归不同,它假设变量之间的直线关系,非线性回归可以模拟更复杂的关系。
离群值检测的重要性
离群值是指显著偏离数据总体模式的数据点。在非线性回归的背景下,离群值可能对模型产生不成比例的影响,导致有偏的参数估计和较差的预测性能。检测和适当处理离群值对于保持回归分析的完整性至关重要。
非线性回归中离群值的检测方法
1.目视检查
- 散点图:散点图是直观检查数据是否存在潜在离群值的简单而有效的方法。通过绘制因变量与自变量的关系图,您可以确定与预期关系相差甚远的点。
- 残差图:残差图显示相对于自变量或拟合值的残差(观测值和预测值之间的差异)。离群值通常表现为具有较大残差的点,这些点与其余数据显著偏离。
2.统计方法
- 学生化残差:学生化残差是残差除以其标准差的估计值。它们遵循t分布,从而更容易识别离群值。具有大于特定阈值的学生化残差的点(例如,2或3)被认为是离群值。
- Cook距离:Cook距离测量每个数据点对拟合值的影响。Cook距离大于特定阈值(通常为4/n,其中n为数据点数量)的点被视为有影响力和潜在离群值。
- Hadi’s Potential:Hadi’s Potential是一种结合杠杆和残差来识别影响点的度量。它在非线性回归中特别有用,其中单独的杠杆可能不足以检测离群值。
3.鲁棒回归方法
- 最小绝对偏差(LAD):最小绝对偏差最小化绝对残差之和,而不是残差平方之和。该方法对离群值不太敏感,并提供了普通最小二乘(OLS)回归的稳健替代方案。
- M-估计:M-估计通过使用减少离群值影响的损失函数来推广最大似然估计。常用的M估计量包括Huber’s T和Tukey’s Bigweight。
- 最小二乘(LTS):最小二乘回归最小化最小平方残差的总和,有效地忽略了可能由于离群值引起的最大残差。该方法在存在离群值的情况下提供稳健的参数估计。
非线性回归检测离群值:实例
步骤1: 导入相关模块库
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.robust.robust_linear_model import RLM
from statsmodels.robust.norms import HuberT, LeastSquares
from sklearn.metrics import mean_squared_error
步骤2: 创建随机数据集
n = 100
x = np.linspace(0, 10, n)
y = 2.5 * np.sin(1.5 * x) + np.random.normal(0, 0.5, n)
# Adding some outliers
x_outliers = np.append(x, [1, 2, 3])
y_outliers = np.append(y, [10, -10, 12])
data = pd.DataFrame({
'tumor_size': x_outliers, 'metastasis_fraction': y_outliers})
步骤3:使用普通最小二乘回归拟合非线性模型
# Adding a nonlinear term for the regression model
data['tumor_size_squared'] = data['tumor_size'] ** 2
ols_model = smf.ols('metastasis_fraction ~ tumor_size + tumor_size_squared', data=data).fit()
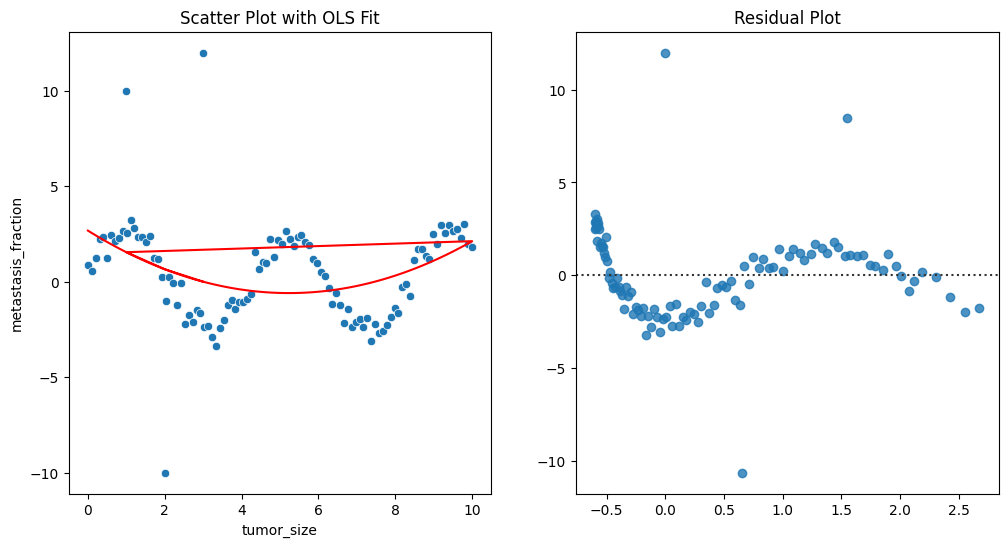
步骤4:可视化数据
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x='tumor_size', y='metastasis_fraction', data=data)
plt.plot(data['tumor_size'], ols_model.fittedvalues, color='red')
plt.title('Scatter Plot with OLS Fit')
plt.subplot(1, 2, 2)
sns.residplot(x=ols_model.fittedvalues, y=ols_model.resid)
plt.title('Residual Plot')
plt.show()
步骤5:应用于回归模型
# Robust regression using Least Absolute Deviations (LAD)
lad_model = smf.quantreg('metastasis_fraction ~ tumor_size + tumor_size_squared', data=data).fit(q=0.5)
# Robust regression using M-Estimation with HuberT norm
rlm_huber = RLM(data['metastasis_fraction'], sm.add_constant(data[['tumor_size', 'tumor_size_squared']]), M=HuberT()).fit()
步骤6:使用统计方法识别离群值
# Studentized Residuals
data['studentized_residuals'] = ols_model 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3530
3530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











