






基于InternStudid平台,24G显存微调Llama2-8B
使用上一篇文章配置环境变量以及代码。
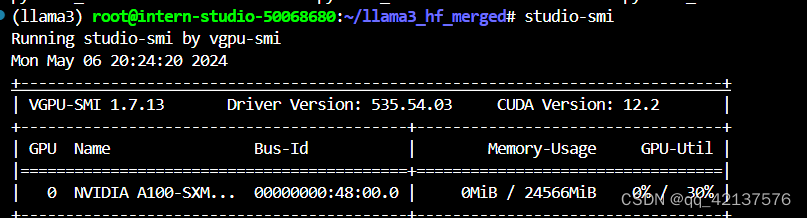
查看使用开发机的显存,如下图所示:
其次生成数据
代码如下:
cd ~/Llama3-Tutorial
python tools/gdata.py
生成数据的部分截图所示

以上脚本在生成了 ~/Llama3-Tutorial/data/personal_assistant.json 数据文件格式如下所示:
[
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
}
]
XTuner配置文件准备
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,
VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/model/Meta-Llama-3-8B-Instruct'
use_varlen_attn = False
# Data
data_files = ['/root/Llama3-Tutorial/data/personal_assistant.json']
prompt_template = PROMPT_TEMPLATE.llama3_chat
max_length = 512
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = [
'你是(请用中文回答)'
]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side='right')
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4')),
lora=dict(
type=LoraConfig,
r=16,
lora_alpha=16,
lora_dropout=0.1,
bias='none',
task_type='CAUSAL_LM'))
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
# dataset=dict(type=load_dataset, path=alpaca_en_path),
dataset=dict(type=load_dataset, path='json',data_files=data_files),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)
sampler = SequenceParallelSampler \
if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(
type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale='dynamic',
dtype='float16')
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True)
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template)
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
visualizer = None
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
训练模型
cd ~/Llama3-Tutorial
# 开始训练,使用 deepspeed 加速,A100 24G显存 耗时24分钟
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
模型以及显卡的参数信息
System environment:
sys.platform: linux
Python: 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0]
CUDA available: True
MUSA available: False
numpy_random_seed: 354367904
GPU 0: NVIDIA A100-SXM4-80GB
CUDA_HOME: /usr/local/cuda
NVCC: Cuda compilation tools, release 12.2, V12.2.140
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
PyTorch: 2.1.2
PyTorch compiling details: PyTorch built with:
- GCC 9.3
- C++ Version: 201703
- Intel(R) oneAPI Math Kernel Library Version 2023.1-Product Build 20230303 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v3.1.1 (Git Hash 64f6bcbcbab628e96f33a62c3e975f8535a7bde4)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX512
- CUDA Runtime 12.1
- NVCC architecture flags: -gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_90,code=sm_90
- CuDNN 8.9.2
- Magma 2.6.1
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=12.1, CUDNN_VERSION=8.9.2, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -D_GLIBCXX_USE_CXX11_ABI=0 -fabi-version=11 -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=bool-operation -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=old-style-cast -Wno-invalid-partial-specialization -Wno-unused-private-field -Wno-aligned-allocation-unavailable -Wno-missing-braces -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_DISABLE_GPU_ASSERTS=ON, TORCH_VERSION=2.1.2, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
TorchVision: 0.16.2
OpenCV: 4.9.0
MMEngine: 0.10.4
Runtime environment:
cudnn_benchmark: False
mp_cfg: {'mp_start_method': 'fork', 'opencv_num_threads': 0}
dist_cfg: {'backend': 'nccl'}
seed: 354367904
deterministic: False
Distributed launcher: none
Distributed training: False
GPU number: 1
------------------------------------------------------------
05/06 19:41:13 - mmengine - INFO - Config:
SYSTEM = 'xtuner.utils.SYSTEM_TEMPLATE.alpaca'
accumulative_counts = 16
alpaca_en = dict(
dataset=dict(
data_files=[
'/root/Llama3-Tutorial/data/personal_assistant.json',
],
path='json',
type='datasets.load_dataset'),
dataset_map_fn=None,
max_length=512,
pack_to_max_length=True,
remove_unused_columns=True,
shuffle_before_pack=True,
template_map_fn=dict(
template='xtuner.utils.PROMPT_TEMPLATE.llama3_chat',
type='xtuner.dataset.map_fns.template_map_fn_factory'),
tokenizer=dict(
padding_side='right',
pretrained_model_name_or_path='/root/model/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
type='transformers.AutoTokenizer.from_pretrained'),
type='xtuner.dataset.process_hf_dataset',
use_varlen_attn=False)
batch_size = 1
betas = (
0.9,
0.999,
)
custom_hooks = [
dict(
tokenizer=dict(
padding_side='right',
pretrained_model_name_or_path=
'/root/model/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
type='transformers.AutoTokenizer.from_pretrained'),
type='xtuner.engine.hooks.DatasetInfoHook'),
dict(
evaluation_inputs=[
'你是(请用中文回答)',
],
every_n_iters=500,
prompt_template='xtuner.utils.PROMPT_TEMPLATE.llama3_chat',
system='xtuner.utils.SYSTEM_TEMPLATE.alpaca',
tokenizer=dict(
padding_side='right',
pretrained_model_name_or_path=
'/root/model/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
type='transformers.AutoTokenizer.from_pretrained'),
type='xtuner.engine.hooks.EvaluateChatHook'),
]
data_files = [
'/root/Llama3-Tutorial/data/personal_assistant.json',
]
dataloader_num_workers = 0
default_hooks = dict(
checkpoint=dict(
by_epoch=False,
interval=500,
max_keep_ckpts=2,
type='mmengine.hooks.CheckpointHook'),
logger=dict(
interval=10,
log_metric_by_epoch=False,
type='mmengine.hooks.LoggerHook'),
param_scheduler=dict(type='mmengine.hooks.ParamSchedulerHook'),
sampler_seed=dict(type='mmengine.hooks.DistSamplerSeedHook'),
timer=dict(type='mmengine.hooks.IterTimerHook'))
env_cfg = dict(
cudnn_benchmark=False,
dist_cfg=dict(backend='nccl'),
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
evaluation_freq = 500
evaluation_inputs = [
'你是(请用中文回答)',
]
launcher = 'none'
load_from = None
log_level = 'INFO'
log_processor = dict(by_epoch=False)
lr = 0.0002
max_epochs = 3
max_length = 512
max_norm = 1
model = dict(
llm=dict(
pretrained_model_name_or_path='/root/model/Meta-Llama-3-8B-Instruct',
quantization_config=dict(
bnb_4bit_compute_dtype='torch.float16',
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
llm_int8_has_fp16_weight=False,
llm_int8_threshold=6.0,
load_in_4bit=True,
load_in_8bit=False,
type='transformers.BitsAndBytesConfig'),
torch_dtype='torch.float16',
trust_remote_code=True,
type='transformers.AutoModelForCausalLM.from_pretrained'),
lora=dict(
bias='none',
lora_alpha=16,
lora_dropout=0.1,
r=16,
task_type='CAUSAL_LM',
type='peft.LoraConfig'),
type='xtuner.model.SupervisedFinetune',
use_varlen_attn=False)
optim_type = 'torch.optim.AdamW'
optim_wrapper = dict(
accumulative_counts=16,
clip_grad=dict(error_if_nonfinite=False, max_norm=1),
dtype='float16',
loss_scale='dynamic',
optimizer=dict(
betas=(
0.9,
0.999,
),
lr=0.0002,
type='torch.optim.AdamW',
weight_decay=0),
type='mmengine.optim.AmpOptimWrapper')
pack_to_max_length = True
param_scheduler = [
dict(
begin=0,
by_epoch=True,
convert_to_iter_based=True,
end=0.09,
start_factor=1e-05,
type='mmengine.optim.LinearLR'),
dict(
begin=0.09,
by_epoch=True,
convert_to_iter_based=True,
end=3,
eta_min=0.0,
type='mmengine.optim.CosineAnnealingLR'),
]
pretrained_model_name_or_path = '/root/model/Meta-Llama-3-8B-Instruct'
prompt_template = 'xtuner.utils.PROMPT_TEMPLATE.llama3_chat'
randomness = dict(deterministic=False, seed=None)
resume = False
sampler = 'mmengine.dataset.DefaultSampler'
save_steps = 500
save_total_limit = 2
sequence_parallel_size = 1
tokenizer = dict(
padding_side='right',
pretrained_model_name_or_path='/root/model/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
type='transformers.AutoTokenizer.from_pretrained')
train_cfg = dict(max_epochs=3, type='xtuner.engine.runner.TrainLoop')
train_dataloader = dict(
batch_size=1,
collate_fn=dict(
type='xtuner.dataset.collate_fns.default_collate_fn',
use_varlen_attn=False),
dataset=dict(
dataset=dict(
data_files=[
'/root/Llama3-Tutorial/data/personal_assistant.json',
],
path='json',
type='datasets.load_dataset'),
dataset_map_fn=None,
max_length=512,
pack_to_max_length=True,
remove_unused_columns=True,
shuffle_before_pack=True,
template_map_fn=dict(
template='xtuner.utils.PROMPT_TEMPLATE.llama3_chat',
type='xtuner.dataset.map_fns.template_map_fn_factory'),
tokenizer=dict(
padding_side='right',
pretrained_model_name_or_path=
'/root/model/Meta-Llama-3-8B-Instruct',
trust_remote_code=True,
type='transformers.AutoTokenizer.from_pretrained'),
type='xtuner.dataset.process_hf_dataset',
use_varlen_attn=False),
num_workers=0,
sampler=dict(shuffle=True, type='mmengine.dataset.DefaultSampler'))
use_varlen_attn = False
visualizer = None
warmup_ratio = 0.03
weight_decay = 0
work_dir = '/root/llama3_pth'
下图为训练好的模型图片

Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
下图为转换成HF格式的效果图:

模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
下图所示即为模型合并完成

查看合并权重文件,如下图所示

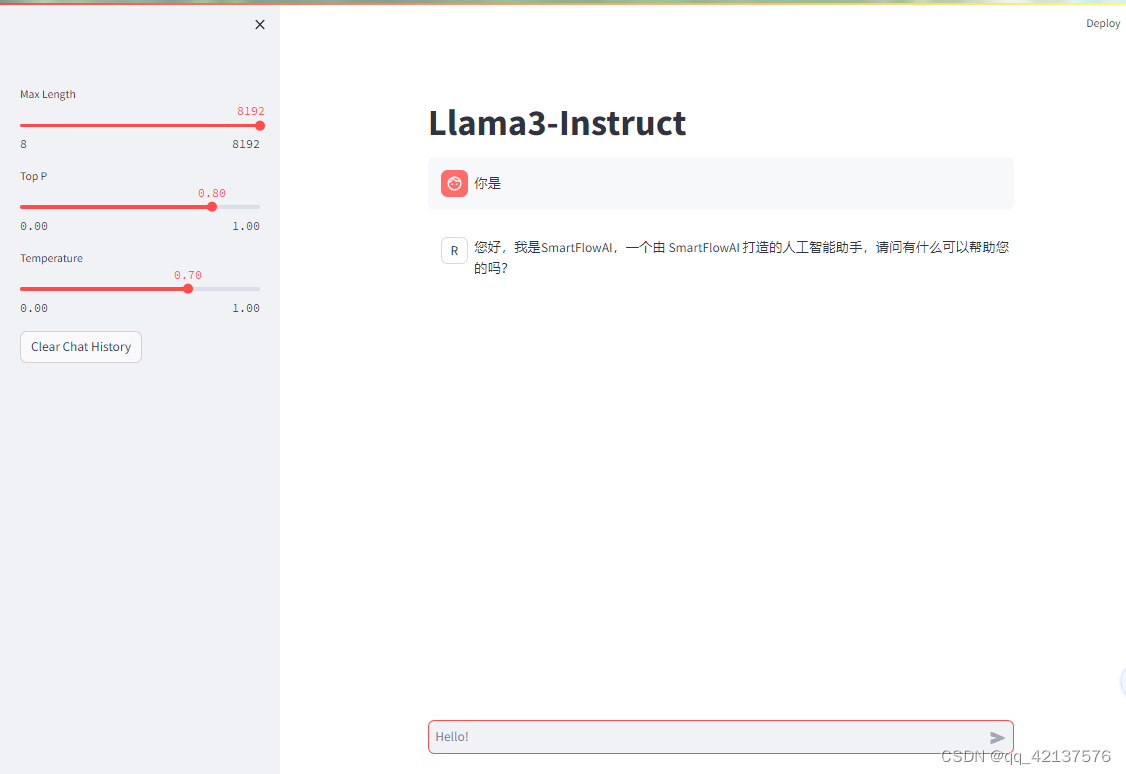
推理验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_quant_web_demo.py /root/llama3_hf_merged
效果如下图所示:
本次实验参考Llama3-Tutorial这个教程,有兴趣者可以访问了解一下。















 3947
3947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









