







10.1 k k k近邻学习
给定测试样本,基于某种距离度量找出训练集中与其最靠近的 k k k个训练样本,然后基于这 k k k个"邻居 "的信息来进行预测。
- 投票法:在分类任务中可使用"投票法" ,即选择这 k k k个样本中出现最多的类别标记作为预测结果。
- 平均法:在回归任务中时使用"平均法" ,即将这 k k k个样本的实值输出标记平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
k k k近邻学习有一个明显的不同之处:它似乎没有显式的训练过程!
给定测试样本
x
x
x, ,若其最近邻样本为
z
z
z,则最近邻分类器出错的概率就是
x
x
x与
z
z
z类别标记不同的概率,即:
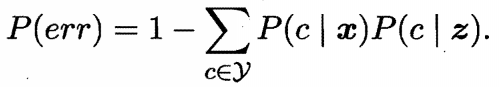
假设样本独立同分布,且对任意
x
x
x和任意小正数
δ
\delta
δ ,在
x
x
x附近
δ
\delta
δ距离范围内总能找到一个训练样本;换言之,对任意测试样本,总能在任意近的范围内找到上式中的训练样本
z
z
z. 令
c
∗
=
a
r
g
m
a
x
c*=argmax
c∗=argmaxc
∈
\in
∈y
P
(
c
∣
x
)
P(c|x)
P(c∣x) 表示贝叶斯最优分类器的结果,有:

最近邻分类器虽简单,但它的泛化错误率不超过贝叶斯最优分类器的错误率的两倍!
10.2低维嵌入
任意测试样本 x x x附近任意小的离范围内总能找到一个训练样本,即训练样本的来样密度足够大,或称为"密采样" (dense sample). 然而,这个假设在现实任务中通常很难满足,例如若 δ \delta δ = 0.001。
例如假定属性维数为 20 ,若要求样本满足密采样条件,则至少需(103)20 = 1060 个样本。
事实上,在高维情形下出现的数据样本稀疏、 距离计算困难等问题是所有机器学习方法共同面面临的严重障碍, 被称为" 维数灾难" (curse of dimensionality)。
缓解维数灾难的一个重要途径是降维(dimension reduction) 亦称" 维数约简 " ,即通过某种数学变换将原始高维属性空间转变为一个低维"子空间" 。


10.3主成分分析

降维后低维空间的维数
d
′
d'
d′通常是由用户事先指定,或通过在
d
′
d'
d′值不同的低维空间中对
k
k
k近邻分类器(或其他开销较小的学习器)进行交叉验证来选取较好的
d
′
d'
d′值.对 PCA,还可从重构的角度设置一个重构阈值,例如
t
t
t=95%后选取使下式成立的最小
d
′
d'
d′值:
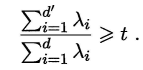
PCA仅需保留
W
W
W样本的均值向量即可通过简单的向量减法和矩阵"向量乘法将新样本投影至低维空间中,显然,低维空间与原始高维空间必有不同,因为对应于最小的
d
−
d
′
d-d'
d−d′ 个特征值的特征向量被舍弃了,这是降维导致的结果。但舍弃这部分信息往往是必要的:一方面舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机; 另一方面,当数据受到噪声影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在 定程度上起到去噪的效果。















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











