







算法设计 第十一章 近似算法
1 近似算法
存在一些难解的问题,不能有效的找到最优解,如何做?降低标准,寻找足够优的解。
优化中的常见现象,将问题松弛或者将非凸问题转为凸问题,等等。降低求解复杂度,找到一个最够优的解。
1.1 近似率:
X是一个极大化问题,A是求解X的算法。
x
A
x_{A}
xA是算法A求出的解,
x
∗
x_{*}
x∗是最优解。
如果A的解至少是
1
a
\frac{1}{a}
a1的最优解,
x
A
≥
1
α
x
∗
x_{A}\ge\frac{1}{\alpha}x_{*}
xA≥α1x∗,则A是
α
\alpha
α-近似算法。
对于极小化问题,
x
A
≤
α
x
∗
x_{A}\leq{\alpha}x_{*}
xA≤αx∗。
2例子
2.1集合覆盖 set cover
给定集合的集合
F
=
{
S
1
,
.
.
.
,
S
n
}
F=\{S_1,...,S_n\}
F={S1,...,Sn},
∪
S
i
=
X
\cup S_i=X
∪Si=X,每个集合
S
i
S_i
Si有对应的成本,我们希望找到
F
F
F的子集,覆盖所有元素。每个
S
i
S_i
Si的成本相同,本质希望找到最少的子集来覆盖所有元素。
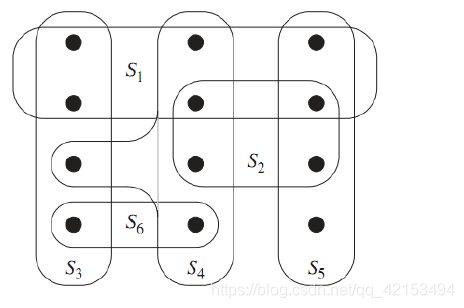
2.1.1 贪婪近似算法
当我们选择一个集合之后,删除已经被覆盖的元素。然后我们选择每个单位成本最小的集合直到覆盖所有元素。本质上每次选择覆盖未覆盖元素最多的集合。
- U = X U=X U=X
- C = C={} C=
- whille U
≠
\not =
= {}
– S ∈ F − C S\in F-C S∈F−C with min c o s t ( S ) / ∣ S ∩ U ∣ cost(S)/|S\cap U| cost(S)/∣S∩U∣
– C = C ∪ S C=C\cup {S} C=C∪S
– U = U − S U=U-S U=U−S - output C C C
2.1.2 计算近似率
选择的集合按照先后顺序为
S
1
,
S
2
,
…
,
S
m
S_1,S_2,\dots,S_m
S1,S2,…,Sm。
n
i
n_i
ni是选择
S
i
S_i
Si时,其覆盖的新元素个数。
元素被覆盖的顺序
e
1
,
e
2
,
…
,
e
n
e_1,e_2,\dots,e_n
e1,e2,…,en。
设
S
j
S_j
Sj第一次覆盖新元素
e
k
e_k
ek。
C
1
,
.
.
.
C_1,...
C1,...是最优覆盖中的部分集合,覆盖了
e
k
,
…
,
e
n
e_k,\dots,e_n
ek,…,en。
n
i
′
n_i'
ni′是其覆盖的对应元素个数。不仅仅是
e
k
,
…
,
e
n
e_k,\dots,e_n
ek,…,en中的元素。
- 1 ∑ i n i ′ ≥ n − k + 1 \sum_i n_i'\ge n-k+1 ∑ini′≥n−k+1, ∑ i c o s t ( C i ) ≤ O P T \sum_i cost(C_i)\leq OPT ∑icost(Ci)≤OPT因为 C i , . . . C_i,... Ci,...也可能覆盖了其他元素,是从最优覆盖中选择的部分集合。
- 2 C 1 , . . . . C_1,.... C1,....没有与 S 1 , . . . S j − 1 S_1,...S_{j-1} S1,...Sj−1重复的。假设某个 C i C_i Ci在 S 1 , . . . S j − 1 S_1,...S_{j-1} S1,...Sj−1中,则 e k e_k ek之后的元素会被某个 S i ( i ∈ [ 1 , j − 1 ] ) S_i(i\in[1,j-1]) Si(i∈[1,j−1])覆盖,矛盾。
- 3 ∑ i c o s t ( C i ) / ∑ i n i ′ ≤ O P T / ( n − k + 1 ) \sum_i cost(C_i)/\sum_i n_i'\leq OPT/(n-k+1) ∑icost(Ci)/∑ini′≤OPT/(n−k+1)==>存在某个 c o s t ( C i ) / n i ′ ≤ O P T / ( n − k + 1 ) cost(C_i)/n_i'\leq OPT/(n-k+1) cost(Ci)/ni′≤OPT/(n−k+1)。
- 4 c o s t ( S j ) / n j cost(S_j)/n_j cost(Sj)/nj贪婪算法选出的,所以 c o s t ( S j ) / n j ≤ c o s t ( C i ) / n i ′ cost(S_j)/n_j\leq cost(C_i)/ n_i' cost(Sj)/nj≤cost(Ci)/ni′(有个问题这里的 n ′ n' n′不是覆盖的新元素个数, ≤ \leq ≤未必成立啊??)
- 对于每个k都存在满足3和4的 C i C_i Ci
- ∑ k c o s t ( e k ) ≤ ∑ k c o s t ( C i ) / n i ′ ≤ ∑ k O P T / ( n − k + 1 ) ∼ l n ( n ) ∗ o p t \sum_k cost(e_k)\leq\sum_k cost(C_i)/ n_i'\leq \sum_kOPT/(n-k+1)\sim ln(n) *opt ∑kcost(ek)≤∑kcost(Ci)/ni′≤∑kOPT/(n−k+1)∼ln(n)∗opt。
2.2 时序问题 scheduling
n个独立的工作,m个处理器,给每个处理器分配任务,使得完成时间最早。

2.2.1 近似算法一
将工作任意排序,然后分配任务给每个处理器,优先分配给该时刻没有任务的处理器。
2.2.2 近似率
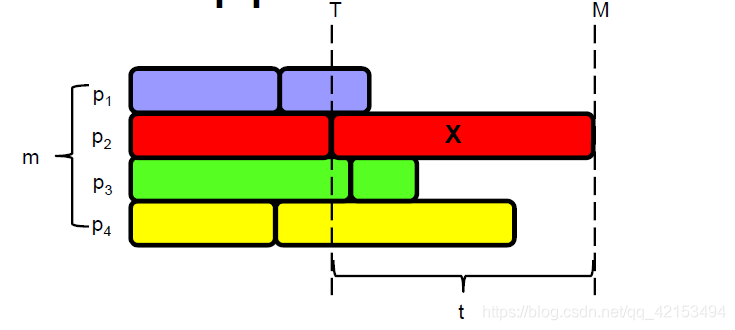
假设最优的makespan的
M
∗
M^*
M∗。
- M ∗ ≥ t M^*\ge t M∗≥t 因为要完成工作 X X X
- M ∗ > T M^*>T M∗>T 因为T时刻之前的工作是满的。
- M ∗ > m a x ( T , t ) M^*>max(T,t) M∗>max(T,t)
- M = T + t ≤ 2 M ∗ M=T+t\leq2M^* M=T+t≤2M∗
2.2.3 近似算法二
按照工作时间长短排序,工作时间长则优先处理。makespan 是 M M M
2.2.4 近似率二
M = t + T ≤ t + M ∗ M=t+T\leq t+M^* M=t+T≤t+M∗
- if t ≤ M ∗ / 3 t\leq M^*/3 t≤M∗/3,==> M ≤ 4 M ∗ / 3 M\leq4M^*/3 M≤4M∗/3
- if t > M ∗ / 3 t> M^*/3 t>M∗/3则所有任务的尺寸不小于 M ∗ / 3 M^*/3 M∗/3,最优算法时每个处理器最多处理两个任务,此时该算法返回最优解。
算法一是online 可以实时操作,算法二需要知道所有任务的尺寸。
2.3背包问题 knapsack
2.4 点集覆盖 vertex cover
G(V,E) 找到一个V的子集覆盖所有边E。尽可能选择最少的点。
2.4.1 近似算法
思路:找到一个最优的边集覆盖。
- 选择E中的任意一边 ( u , v ) (u,v) (u,v)
- u , v {u,v} u,v是我们选择的边。
- 移除所有与
u
,
v
{u,v}
u,v连接的点。如下图所示:

2.4.2近似率
该算法是2-近似,设
C
∗
C^*
C∗是最优解。
A
A
A是近似算法选出的边。注意这里是边,不是点。
C
=
2
∗
∣
A
∣
≤
2
∗
∣
C
∗
∣
C=2*|A|\leq 2*|C^*|
C=2∗∣A∣≤2∗∣C∗∣
2.5 旅行商问题 TSP
- 输入一个完全图
- 输出最小的距离的环,经过所有的点。
- 假设符合三角不等式。
2.5.1 近似算法1
- 最小生出树 T T T
- 访问树中所有节点,允许重复 T ′ T' T′
- 跳过重复的节点 H H H

2.5.2 近似率
设最优解为
H
∗
H^*
H∗
因为
T
T
T是最小生成树,
c
(
T
)
≤
C
(
H
∗
)
c(T)\leq C(H^*)
c(T)≤C(H∗)。
T经过所有点两次
c
(
T
∗
)
=
2
c
(
T
)
c(T^*)=2c(T)
c(T∗)=2c(T)。
因为
H
H
H是
T
∗
T^*
T∗经过shortcut之后的,
c
(
H
)
≤
c
(
T
∗
)
c(H)\leq c(T^*)
c(H)≤c(T∗)。
总是
c
(
H
)
≤
c
(
T
′
)
=
2
c
(
T
)
≤
2
c
(
H
∗
)
c(H)\leq c(T')= 2c(T)\leq 2c(H^*)
c(H)≤c(T′)=2c(T)≤2c(H∗)。
2.5.3 近似算法2
Euler tour:访问图中的所有边一次,当且仅当所有的点有偶数度。
-
最小生成树T
-
找到奇数度的点V’
-
构造最小的,完美匹配(一个点只与一个点相连)M
-
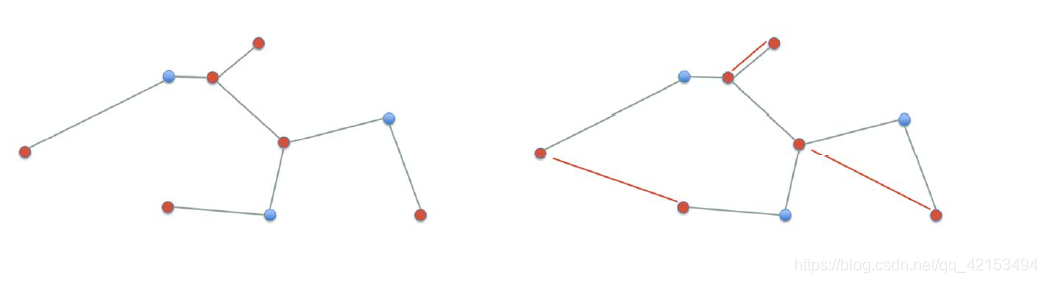
-
将M添加到T中获得T’,所有的点都是偶数度。
-
得到T’的 Euler tour T’’
-
shortcut T’’ 去获得H
2.5.4
H’是V’(奇数度点)的最优TSP
最小完美匹配M,因为每个点只有一个match,而且是最小的,
H
′
H'
H′有两个match,
c
(
M
)
≤
c
(
H
′
)
/
2
≤
c
(
H
∗
)
/
2
c(M)\leq c(H')/2\leq c(H^*)/2
c(M)≤c(H′)/2≤c(H∗)/2
c
(
H
)
≤
c
(
T
∗
)
=
c
(
M
)
+
c
(
T
)
≤
c
(
H
∗
)
/
2
+
c
(
H
∗
)
c(H)\leq c(T^*)=c(M)+c(T) \leq c(H^*)/2+c(H^*)
c(H)≤c(T∗)=c(M)+c(T)≤c(H∗)/2+c(H∗)
2.6k-center 问题
n个sites 我们想建立k个中心来服务他们,每个site选择离它最近的中心。
我们想要极小化最大的服务距离。
2.6.1算法
选择site作为中心
每次选择里中心最远的site作为中心。
2.6.2 近似率
r
=
m
a
x
S
m
i
n
C
d
(
s
,
c
)
r=max_Smin_Cd(s,c)
r=maxSminCd(s,c)
这里有k+1个点距离不小于
r
r
r,k个中心,以及剩下一个到中心最大距离的site。
假设
r
>
2
r
∗
r>2r^*
r>2r∗
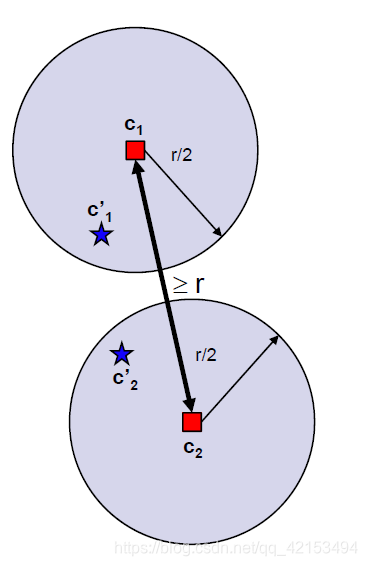
每个圆需要一个中心来服务圆心的site,导致第
k
+
1
k+1
k+1个无法被服务。因此
r
≤
2
r
∗
r\leq 2r^*
r≤2r∗
2.7加权点集覆盖weighted vertex cover
建模为整数规划问题
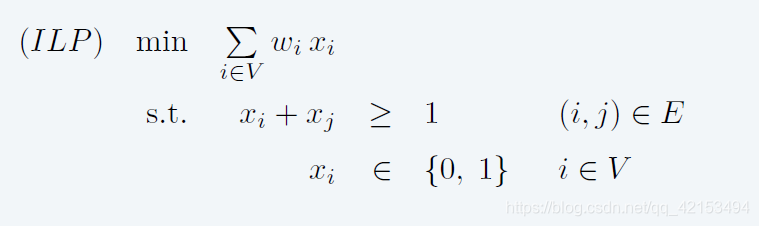
松弛为线性规划
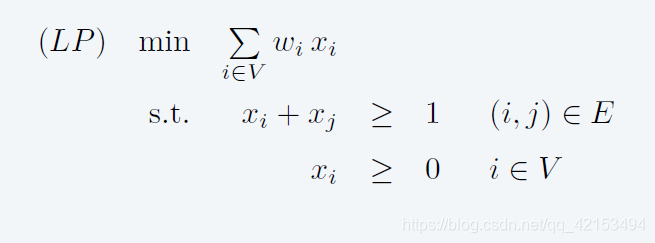

3 复杂度总结
















 3720
3720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









