






文章目录
Claude 3.7 Sonnet 和 Claude Code
预计阅读时间:5分钟

(插图:Claude 正在逐步思考)
今天,我们宣布推出 Claude 3.7 Sonnet¹ —— 迄今为止我们最智能的模型,同时也是市场上首个混合推理模型。Claude 3.7 Sonnet 能够给出近乎即时的回答,也可以展开延长、逐步的思考过程,并将这一过程向用户展示。API 用户还可以对模型思考的时长进行精细控制。
Claude 3.7 Sonnet 在编码和前端网页开发方面展现出了尤为显著的进步。除了这款模型,我们还推出了一个面向代理式编码的命令行工具 —— Claude Code。Claude Code 正以限量研究预览的形式发布,它使开发者可以直接通过终端将大量工程任务交由 Claude 处理。
(屏幕截图:展示 Claude Code 的入门流程)
Claude 3.7 Sonnet 现已适用于所有 Claude 方案 —— 包括免费版、Pro、团队版和企业版 —— 同时也可通过 Anthropic API、Amazon Bedrock 以及 Google Cloud 的 Vertex AI 使用。扩展思维模式在除免费版之外的所有版本中均可使用。
在标准模式和扩展思维模式下,Claude 3.7 Sonnet 的定价与前代产品保持一致:每百万输入 token 3 美元,每百万输出 token 15 美元(输出 token 包括思考 token)。
Claude 3.7 Sonnet:前沿推理的实用化
我们开发 Claude 3.7 Sonnet 所遵循的理念与市面上其他推理模型截然不同。正如人类利用同一颗大脑既能迅速应答,也能进行深度反思,我们认为推理能力应当是前沿模型的一项集成功能,而非完全独立的模型。这种统一的方法为用户提供了更为无缝的体验。
Claude 3.7 Sonnet 在多个方面体现了这一理念:
-
双模式设计
它既是一个普通的大型语言模型,又兼具推理能力。用户可以根据需要选择让模型直接回答,或在回答前花更多时间进行自我反思。在标准模式下,Claude 3.7 Sonnet 是 Claude 3.5 Sonnet 的升级版;而在扩展思维模式下,模型在回答前会进行更深入的思考,从而在数学、物理、指令遵循、编码等任务上表现更佳。我们发现,无论哪种模式下,向模型发起提示的方式基本一致。 -
思考预算控制
当通过 API 使用 Claude 3.7 Sonnet 时,用户可以设定模型最多思考 N 个 token(N 的上限为 128K token 输出限制),从而在回答速度、成本与答案质量之间进行权衡。 -
聚焦现实任务
在开发过程中,我们将重点从数学和计算机科学竞赛题目适当转移,更多关注能够真实反映企业应用场景的任务。
早期测试显示,Claude 在编码能力方面全面领先:
- Cursor 指出,Claude 再次成为处理实际编码任务的最佳模型,在处理复杂代码库和高级工具使用等领域均有显著提升。
- Cognition 发现它在规划代码修改和处理全栈更新方面远超其他模型。
- Vercel 强调 Claude 在复杂代理工作流中的卓越精准度;
- Replit 则成功利用 Claude 从零开始构建复杂的网页应用和仪表板,而其他模型往往止步不前;
- Canva 的评测显示,Claude 始终能生成生产级代码,其设计感更佳且错误大幅减少。
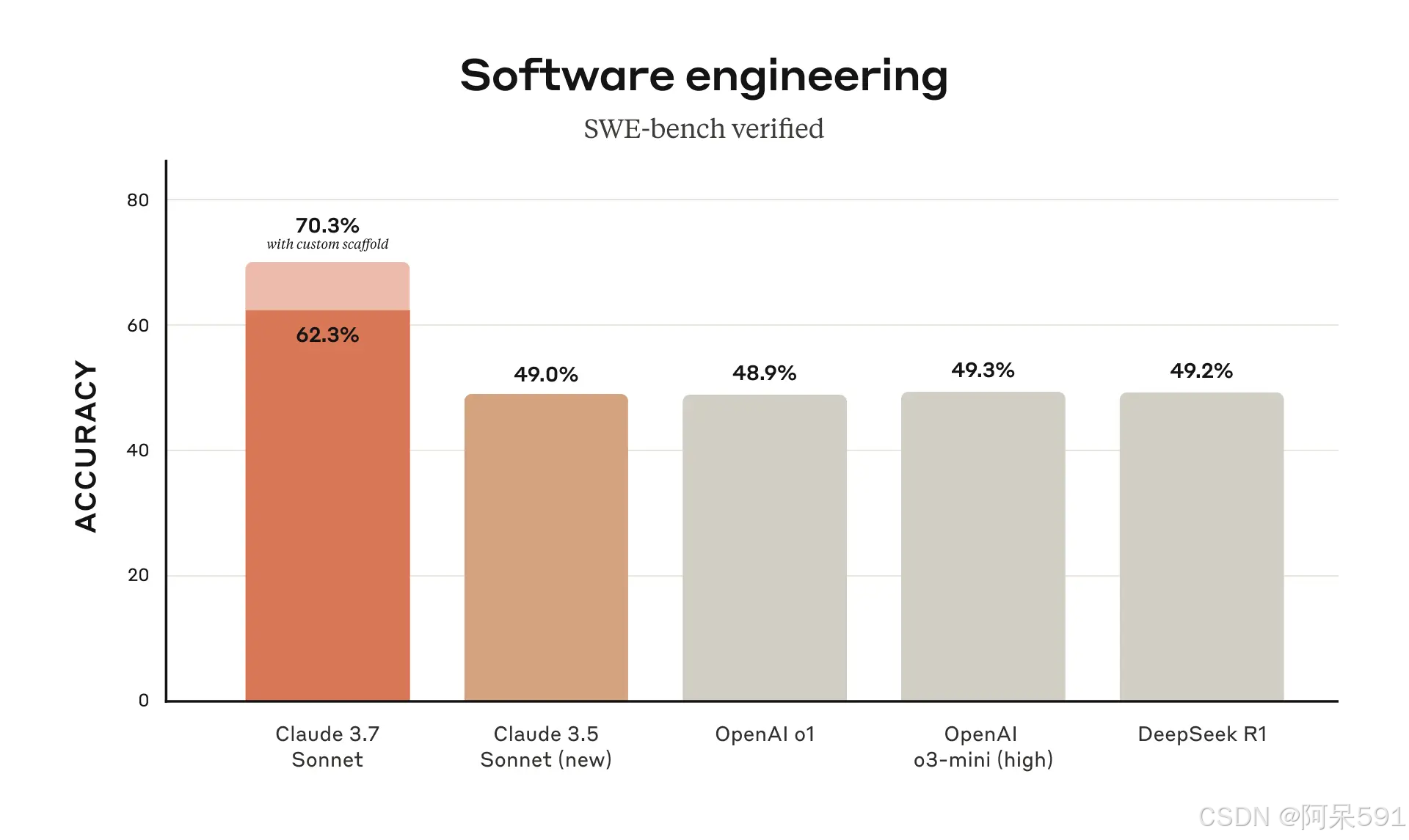
Claude 3.7 Sonnet 在 SWE-bench Verified 上取得了最先进的表现,该评测衡量 AI 模型解决现实软件问题的能力。更多关于搭建框架的信息,请参见附录。
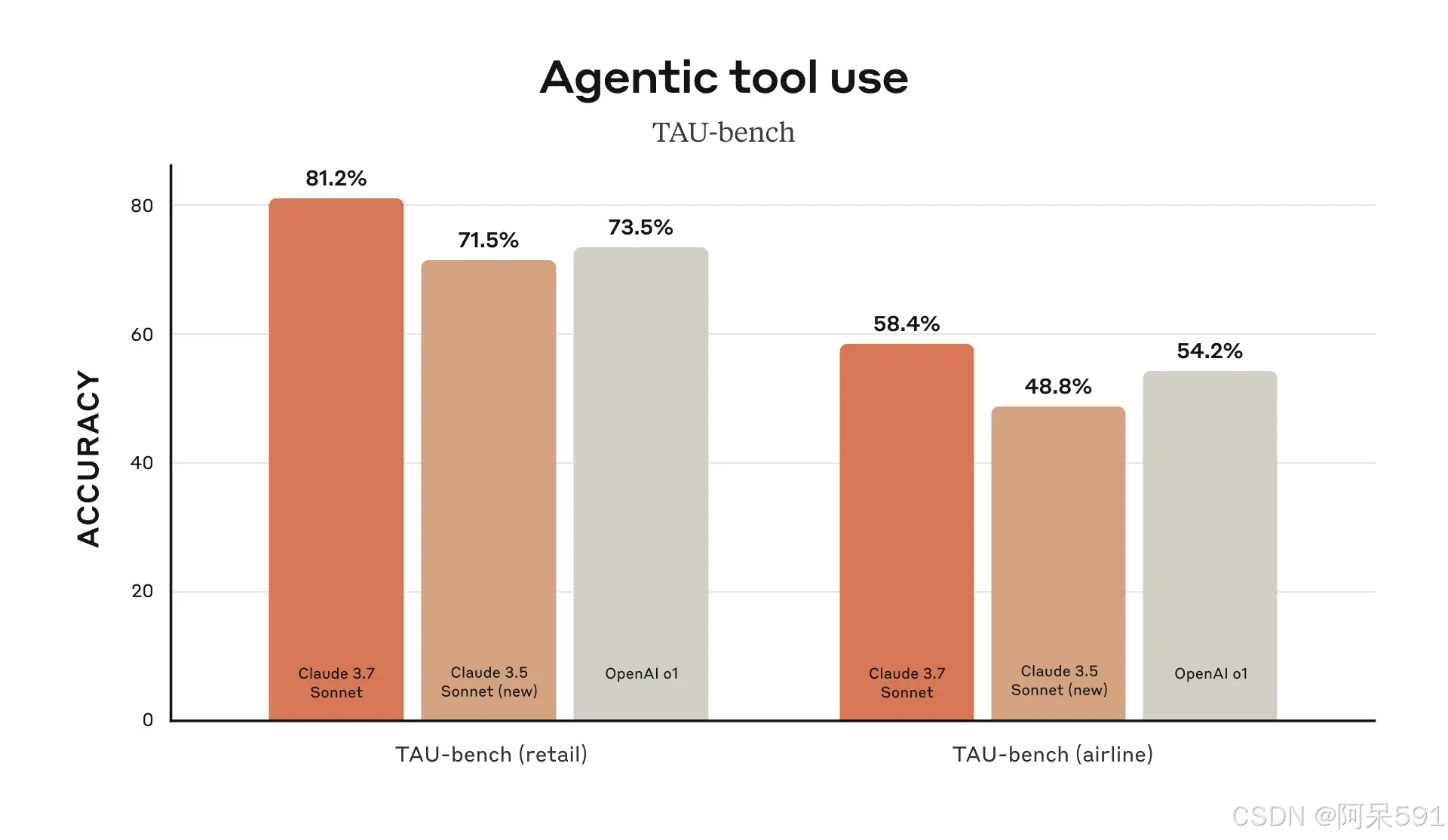
同时,Claude 3.7 Sonnet 在 TAU-bench 上也取得了最先进的表现,该评测测试 AI 代理在用户和工具交互下解决复杂实际任务的能力(更多信息请参见附录)。
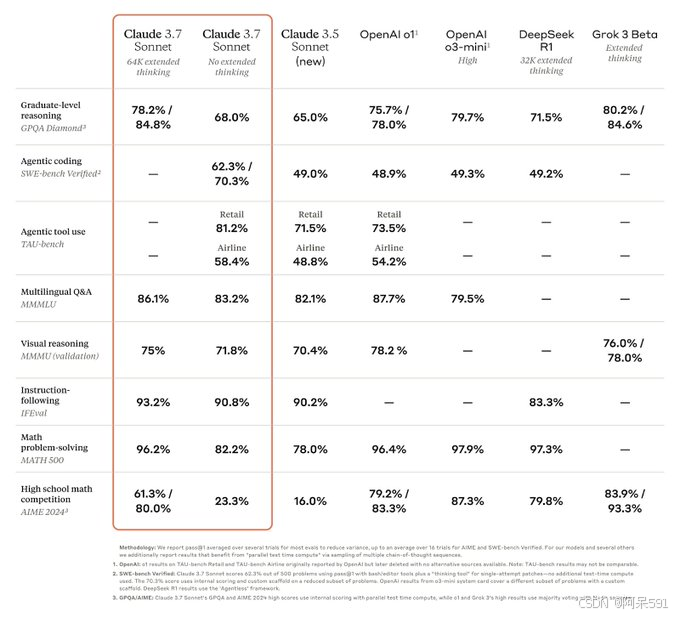
在指令遵循、通用推理、多模态能力以及代理式编码等方面,Claude 3.7 Sonnet 表现卓越;扩展思维模式在数学和科学领域更是带来了显著提升。超越传统基准测试,在我们的《宝可梦》游戏测试中,它甚至超越了所有前代模型。
Claude Code
自2024年6月以来,Sonnet 一直是全球开发者的首选模型。今天,我们通过推出 Claude Code —— 首款代理式编码工具(以限量研究预览形式发布) —— 进一步赋能开发者。
Claude Code 是一个积极协作的工具,能够:
- 搜索和阅读代码
- 编辑文件
- 编写并运行测试
- 提交代码并推送至 GitHub
- 使用命令行工具
它使你在每一步都能保持参与。尽管 Claude Code 仍处于早期阶段,但它已成为我们团队不可或缺的工具,尤其在测试驱动开发、调试复杂问题以及大规模重构方面表现出色。在早期测试中,Claude Code 能在一次操作中完成通常需要 45 分钟以上手工操作的任务,大幅缩短了开发时间并降低了成本。
在接下来的几周内,我们计划根据实际使用情况不断改进 Claude Code,包括:
- 提升工具调用的可靠性
- 增加对长时间运行命令的支持
- 改进应用内渲染效果
- 扩展 Claude 对自身能力的理解
我们的目标是通过 Claude Code 更好地了解开发者如何利用 Claude 进行编码,从而为未来模型的改进提供依据。加入此次预览,你将获得我们构建和改进 Claude 时所使用的强大工具,而你的反馈将直接影响其未来发展。
与 Claude 协同处理你的代码库
我们还改进了在 Claude.ai 上的编码体验。现在,所有 Claude 方案均支持 GitHub 集成,开发者可以将代码仓库直接连接至 Claude。
凭借对个人、工作及开源项目的深刻理解,Claude 3.7 Sonnet 已成为你修复漏洞、开发新功能和编写文档时的强大合作伙伴,助你高效管理最重要的 GitHub 项目。
负责任地构建
我们对 Claude 3.7 Sonnet 进行了广泛的测试和评估,并与外部专家紧密合作,以确保其符合我们的安全、可靠性和隐私标准。相比前代产品,Claude 3.7 Sonnet 在区分有害请求与无害请求时更为细腻,不必要的拒绝率降低了 45%。
此次发布的系统卡详细介绍了多个类别下的新安全成果,提供了我们“负责任扩展政策”评估的详细拆解,供其他 AI 实验室和研究人员参考。系统卡还讨论了计算机使用中的新风险(特别是提示注入攻击),并解释了我们如何评估和训练 Claude 来抵御这些风险。此外,它还探讨了推理模型潜在的安全益处,如理解模型决策过程的能力,以及模型推理是否真正值得信赖。更多细节请查阅完整的系统卡。
展望未来
Claude 3.7 Sonnet 和 Claude Code 标志着向真正增强人类能力的 AI 系统迈出的重要一步。凭借深度推理、独立工作和高效协同的能力,它们正引领我们迈向一个 AI 能够丰富并扩展人类成就的未来。

我们非常期待你探索这些新能力,并见证你将用它们创造出怎样的成果。正如以往一样,我们欢迎你的反馈,助力我们不断改进和进化模型。
附录
命名经验教训
评测数据来源
- Grok
- Gemini 2 Pro
- o1 和 o3-mini
- 补充 o1
- o1 TAU-bench
- 补充 o3-mini
- Deepseek R1
- TAU-bench
关于搭建框架的信息
这些得分通过在 Airline Agent Policy 中添加提示补充实现,该补充指示 Claude 更好地利用“规划”工具,鼓励模型在多轮推理过程中记录下解决问题的思考过程,与我们通常的思考模式区分开来,以充分发挥其推理能力。为容纳 Claude 通过更多思考产生的额外步骤,最大步骤数(按模型完成次数计算)已从 30 增加至 100(大多数轨迹在 30 步内完成,只有个别超过 50 步)。
此外,由于自发布以来对数据集进行了小幅改进,Claude 3.5 Sonnet(新版)的 TAU-bench 得分与最初报告的有所不同。我们在更新后的数据集上重新测试,以便与 Claude 3.7 Sonnet 进行更精确的比较。
SWE-bench Verified
关于搭建框架的信息:
解决像 SWE-bench 这样开放式代理任务的方法有很多。一些方法将决定检查或编辑哪些文件以及运行哪些测试的复杂性转移给传统软件,而将核心语言模型用于在预定义位置生成代码或从有限操作集中选择。
- Agentless(Xia 等,2024)是 Deepseek R1 及其他模型评测中广泛采用的框架,通过基于提示和嵌入的文件检索机制、补丁定位以及对回归测试进行 40 次拒绝采样来增强代理功能。
- 其他搭建框架(例如 Aide)则通过重试、N 倍最佳或蒙特卡洛树搜索(MCTS)为模型提供额外的测试时计算支持。
对于 Claude 3.7 Sonnet 和 Claude 3.5 Sonnet(新版),我们采用了一种更简单、搭建框架较少的方法,让模型在单次会话中自主决定运行哪些命令和编辑哪些文件。我们的主要“无扩展思考” pass@1 结果仅为模型配备了两种工具 —— 一个 bash 工具和一个通过字符串替换操作的文件编辑工具 —— 以及前文 TAU-bench 结果中提到的“规划工具”。由于基础设施限制,我们的内部系统实际上只能解决 500 个问题中的 489 个(即黄金解决方案通过测试)。为了与官方排行榜保持一致,我们将这 11 个无法解决的问题计为失败。为保证透明度,我们将单独发布在内部基础设施上未能通过测试的用例。
对于我们的“高计算”结果,我们引入了额外的复杂性和并行测试时计算,具体方法如下:
- 使用上述搭建框架采样多个并行尝试;
- 丢弃那些破坏代码仓库中可见回归测试的补丁(类似于 Agentless 所采用的拒绝采样方法,且未使用任何隐藏的测试信息);
- 然后,采用类似于在 GPQA 和 AIME 评测中使用的评分模型对剩余尝试进行排序,并选择最佳方案提交。
这样,在我们系统中有效的 489 个验证任务子集上,我们的得分为 70.3%。若不采用此搭建框架,Claude 3.7 Sonnet 在同一子集上的 SWE-bench Verified 得分为 63.7%。以下是不兼容于我们内部基础设施而被排除的 11 个测试用例:
- scikit-learn__scikit-learn-14710
- django__django-10097
- psf__requests-2317
- sphinx-doc__sphinx-10435
- sphinx-doc__sphinx-7985
- sphinx-doc__sphinx-8475
- matplotlib__matplotlib-20488
- astropy__astropy-8707
- astropy__astropy-8872
- sphinx-doc__sphinx-8595
- sphinx-doc__sphinx-9711



















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











