









Motivation
现有的模型存在捕捉细微差异的能力不足的问题,这些模型在区分字面相似度高但语义不同的句子对方面表现不佳。这可能是由self-attention架构本身造成的,self-attention机制主要是利用单词的上下文来理解单词的语义,而忽略了建模句子对之间的语义差异。我们假设更多地关注细粒度的语义差异,尤其是同时建模差异和密切性向量会进一步提升模型的性能。

Approach
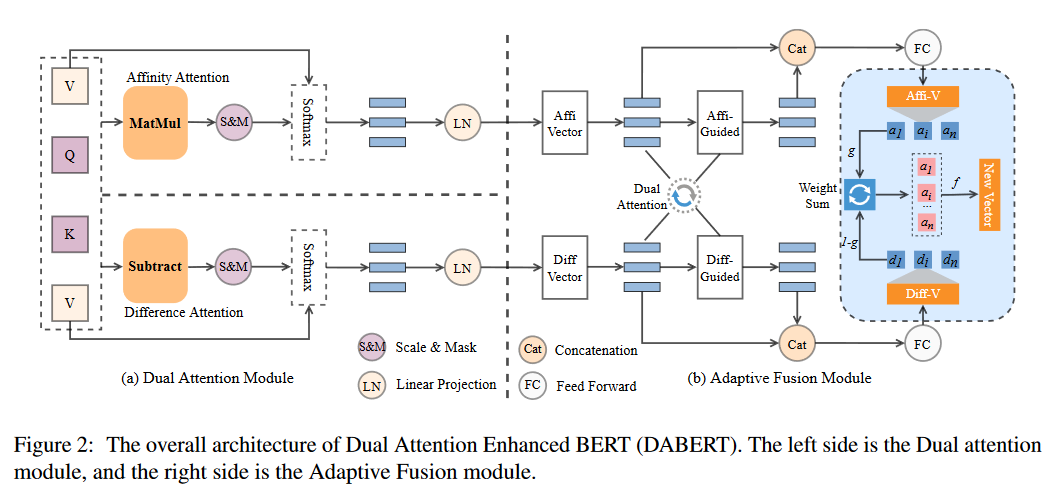
Dual Attention Module
输入是K, Q, V三个矩阵,双重注意模块分别使用两种attention机制计算K, Q, V之间的潜在关系来计算它们的类同和差异。因此,该模块产生了两组attention表示,它们将被后面的自适应融合模块融合。
Affinity Attention
类同注意力模块是双重注意模块的一部分,它是标准的点积注意力。
A
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
∗
V
A = softmax(\frac{QK^T}{\sqrt{d_k}})*V
A=softmax(dkQKT)∗V
A
=
{
a
1
,
.
.
.
,
a
l
}
A = \{a_1,...,a_l\}
A={a1,...,al} 是由transformer原始注意力模块生成出的描述类同的表示。
Difference Attention
差异注意力模块捕捉并汇总了句子对之间的差异信息。差异注意模块采用了基于减法的交叉注意机制,它允许模型通过元素的减法来注意句对之间的不同部分:
D
=
softmax
(
β
d
k
)
∗
V
β
=
∥
Q
−
K
∥
+
M
∥
Q
−
K
∥
i
j
=
∑
k
=
0
d
k
Q
i
k
−
K
j
k
\begin{gathered} \mathbf{D}=\operatorname{softmax}\left(\frac{\beta}{\sqrt{d_k}}\right) * \mathbf{V} \\ \boldsymbol{\beta}=\|\mathbf{Q}-\mathbf{K}\|+\mathbf{M} \\ \|\mathbf{Q}-\mathbf{K}\|_{i j}=\sum_{k=0}^{d_k} \mathbf{Q}_{i k}-\mathbf{K}_{j k} \end{gathered}
D=softmax(dkβ)∗Vβ=∥Q−K∥+M∥Q−K∥ij=k=0∑dkQik−Kjk
D
=
{
d
1
,
.
.
.
,
d
l
}
D = \{d_1,...,d_l\}
D={d1,...,dl} 是由差异注意力模块生成出的表示。(第三个公式:Q和K中对应两个向量的差异就等于这两个向量每个维度的差值之和)
类同注意力和差异注意力都被用来建模句子对的语义关系,并分别从类同和差异的角度获得相同维度的表征。
Adaptive Fusion Module
在获得类同信号A和差异信号D后,我们引入了一个自适应融合模块来融合这两个信号,而不是直接融合(即平均嵌入向量),因为直接融合可能会损害预训练模型的原始表示能力。
我们首先通过类同引导的attention来更新差异向量。我们让每个类同向量
a
i
a_i
ai与差异信号矩阵D相互作用,获得新的差异特征
d
i
∗
d_i^∗
di∗。然后,基于
d
i
∗
d_i^∗
di∗,我们可以反过来通过差异引导的注意力获得新的类同特征
a
i
∗
a_i^∗
ai∗:
δ
i
=
tanh
(
W
D
D
⊕
(
W
a
i
a
i
+
b
a
i
)
)
d
ˉ
i
=
D
∗
softmax
(
W
d
i
δ
i
+
b
d
i
)
γ
i
=
tanh
(
W
A
A
⊕
(
W
d
ˉ
i
d
ˉ
i
+
b
d
ˉ
i
)
)
a
ˉ
i
=
A
∗
softmax
(
W
a
ˉ
i
γ
i
+
b
a
ˉ
∗
i
)
d
i
∗
=
tanh
(
W
d
i
∗
(
[
d
i
;
d
ˉ
i
]
)
+
b
d
i
∗
)
)
a
i
∗
=
tanh
(
W
a
i
∗
(
[
a
i
;
a
ˉ
i
]
)
+
b
a
i
∗
)
)
\begin{aligned} \delta_i &=\tanh \left(\mathbf{W}_D \mathbf{D} \oplus\left(\mathbf{W}_{a_i} a_i+b_{a_i}\right)\right) \\ \bar{d}_i &=\mathbf{D} * \operatorname{softmax}\left(\mathbf{W}_{d_i} \delta_i+b_{d_i}\right) \\ \gamma_i &=\tanh \left(\mathbf{W}_A \mathbf{A} \oplus\left(\mathbf{W}_{\bar{d}_i} \bar{d}_i+b_{\bar{d}_i}\right)\right) \\ \bar{a}_i &=\mathbf{A} * \operatorname{softmax}\left(\mathbf{W}_{\bar{a}_i} \gamma_i+b_{\bar{a} *_i}\right) \\ d_i^* &\left.=\tanh \left(\mathbf{W}_{d_i^*}\left(\left[d_i ; \bar{d}_i\right]\right)+b_{d_i^*}\right)\right) \\ a_i^* &\left.=\tanh \left(\mathbf{W}_{a_i^*}\left(\left[a_i ; \bar{a}_i\right]\right)+b_{a_i^*}\right)\right) \end{aligned}
δidˉiγiaˉidi∗ai∗=tanh(WDD⊕(Waiai+bai))=D∗softmax(Wdiδi+bdi)=tanh(WAA⊕(Wdˉidˉi+bdˉi))=A∗softmax(Waˉiγi+baˉ∗i)=tanh(Wdi∗([di;dˉi])+bdi∗))=tanh(Wai∗([ai;aˉi])+bai∗))
其中
W
D
,
W
A
,
W
a
i
,
W
d
ˉ
i
∈
R
d
l
∗
d
v
;
W
d
i
,
W
a
ˉ
i
∈
R
1
∗
2
d
l
\mathbf{W}_D, \mathbf{W}_A, \mathbf{W}_{a_i}, \mathbf{W}_{\bar{d}_i} \in R^{d_l * d_v} ; \mathbf{W}_{d_i},\mathbf{W}_{\bar{a}_i} \in R^{1 * 2 d_l}
WD,WA,Wai,Wdˉi∈Rdl∗dv;Wdi,Waˉi∈R1∗2dl.
⊕
\oplus
⊕ 表示信号矩阵和特征向量的拼接。
然后,为了自适应地捕捉和融合来自类同和差异性特征的有用信息,我们引入了门融合模块:
d
^
i
=
tanh
(
W
d
^
i
d
i
∗
+
b
d
^
i
)
a
^
i
=
tanh
(
W
a
^
i
a
i
∗
+
b
a
^
i
)
g
i
=
σ
(
W
g
i
(
d
^
i
⊕
a
^
i
)
)
v
i
=
g
i
a
^
i
+
(
1
−
g
i
)
d
^
i
\begin{aligned} \hat{d}_i &=\tanh \left(\mathbf{W}_{\hat{d}_i} d_i^*+b_{\hat{d}_i}\right) \\ \hat{a}_i &=\tanh \left(\mathbf{W}_{\hat{a}_i} a_i^*+b_{\hat{a}_i}\right) \\ g_i &=\sigma\left(\mathbf{W}_{g_i}\left(\hat{d}_i \oplus \hat{a}_i\right)\right) \\ v_i &=g_i \hat{a}_i+\left(1-g_i\right) \hat{d}_i \end{aligned}
d^ia^igivi=tanh(Wd^idi∗+bd^i)=tanh(Wa^iai∗+ba^i)=σ(Wgi(d^i⊕a^i))=gia^i+(1−gi)d^i
其中
W
d
^
i
,
W
a
^
i
∈
R
d
h
∗
d
v
;
W
g
i
∈
R
1
∗
2
d
h
\mathbf{W}_{\hat{d}_i}, \mathbf{W}_{\hat{a}_i} \in R^{d_h * d_v} ; \mathbf{W}_{g_i} \in R^{1 * 2 d_h}
Wd^i,Wa^i∈Rdh∗dv;Wgi∈R1∗2dh
d
h
d_h
dh 是 hidden size.
g
i
g_i
gi 是决定这两个不同表融合的门,这样我们就得到了融合特征
v
i
\boldsymbol{v}_i
vi。最终,考虑到潜在的噪声问题,我们提出了一个过滤门来选择性地利用融合特征
v
i
\boldsymbol{v}_i
vi。当
v
i
\boldsymbol{v}_i
vi 趋于有利时,过滤门将纳入融合特征和原始特征。否则,融合信息将被过滤掉:
f
i
=
σ
(
W
f
i
,
a
i
(
a
i
⊕
(
W
v
i
v
i
+
b
v
i
)
)
l
i
=
f
i
∗
t
a
n
h
(
w
l
i
v
i
+
b
l
i
)
f_i = \sigma(W_{f_i,a_i}(a_i\oplus(W_{v_i}v_i+b_{v_i}))\\ l_i = f_i * tanh(w_{l_i}v_i+b_{l_i})
fi=σ(Wfi,ai(ai⊕(Wvivi+bvi))li=fi∗tanh(wlivi+bli)
其中
W
f
i
,
a
i
∈
R
1
∗
2
d
v
;
W
v
i
,
W
l
i
∈
R
d
v
∗
d
h
,
l
i
\mathbf{W}_{f_i, a_i} \in R^{1 * 2 d_v} ; \mathbf{W}_{v_i}, \mathbf{W}_{l_i} \in R^{d_v * d_h},l_i
Wfi,ai∈R1∗2dv;Wvi,Wli∈Rdv∗dh,li 是最终的融合语义特征,并会被传播到下一次计算中。
Results
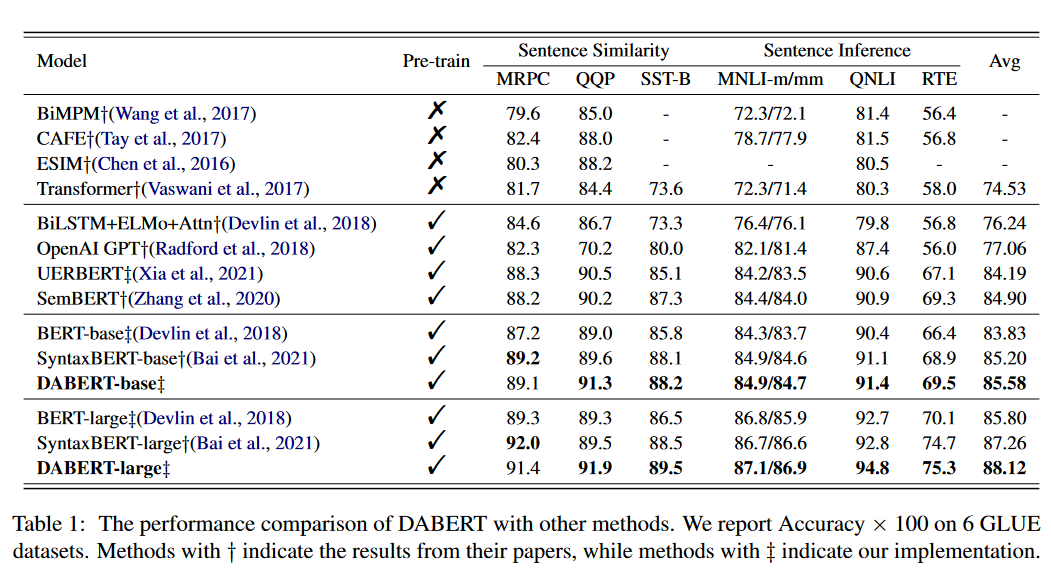
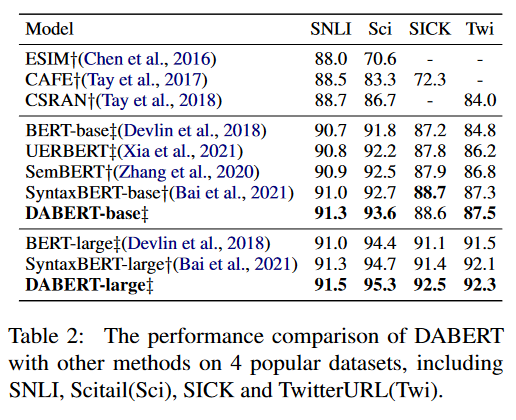
Main Results
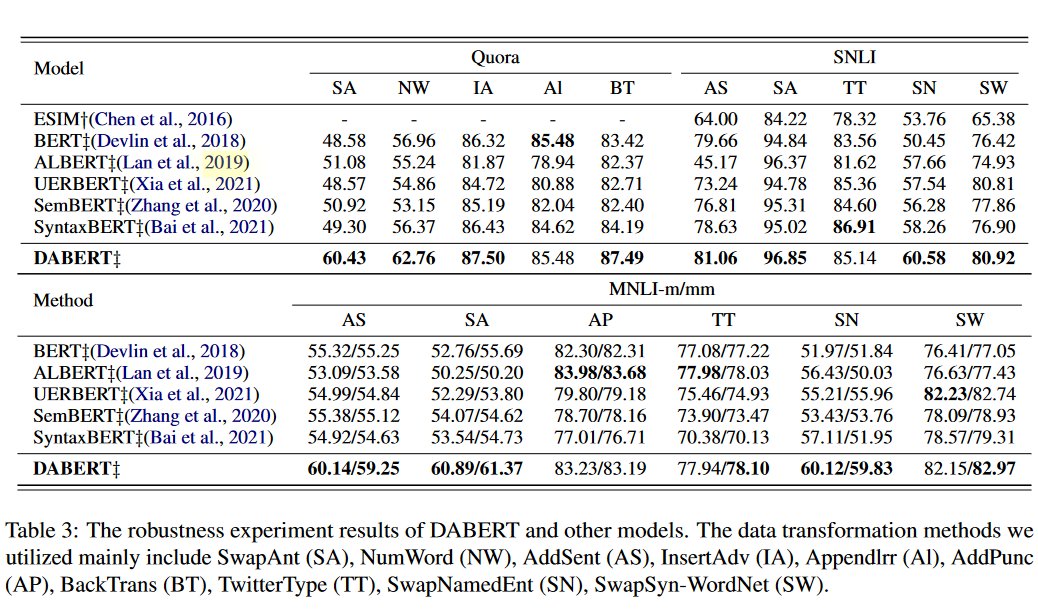
Robustness Test Performance
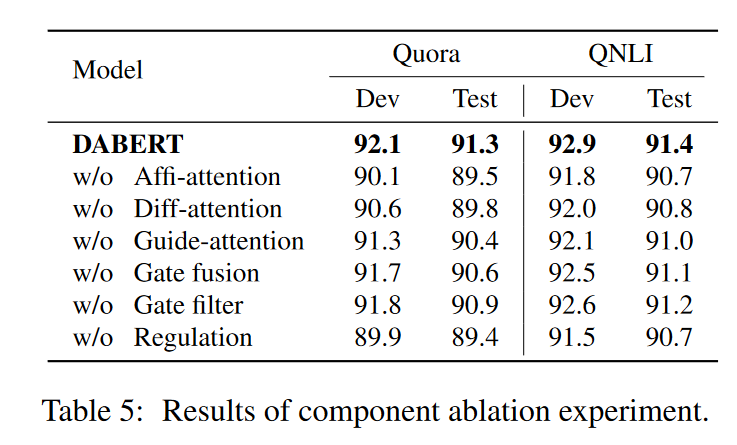
Ablation Study
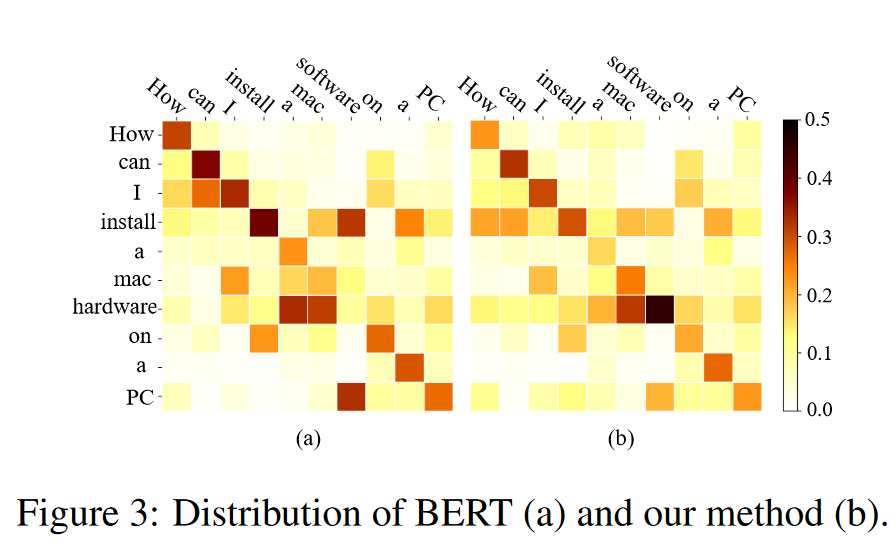
Case Study














 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









