









有台闲置的CentOS 8.5,正好给它装个Deepseek-R1,没有显卡故选用 llama.cpp,话不多说,上操作:

一.先克隆 llama.cpp 仓库并编译(😀用Ubuntu的有福了,有现成的可以直接下载llama-b4686-bin-ubuntu-x64.zip,跳过这步直接去看二)。

步骤
- 更新系统和安装依赖项
- 克隆
llama.cpp仓库 - 编译
llama.cpp项目
1. 更新系统和安装依赖项
首先,更新系统并安装必要的开发工具和依赖项。
sudo yum update -y
sudo yum groupinstall "Development Tools" -y
sudo yum install cmake git -y
2. 克隆 llama.cpp 仓库
使用 Git 克隆 llama.cpp 仓库。
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
3. 编译 llama.cpp 项目(挺慢的,需耐心等待)
创建构建目录并编译项目。
mkdir build
cd build
cd llama.cpp
# 4、编译llama.cpp,创建构建目录build,并进行静态编译
cmake -B build -DBUILD_SHARED_LIBS=OFF
#!!注意!! Linux自带的gcc版本比较低,我这是8.5版本,需要修一个编译配置文件:
vim ./ggml/src/CMakeLists.txt
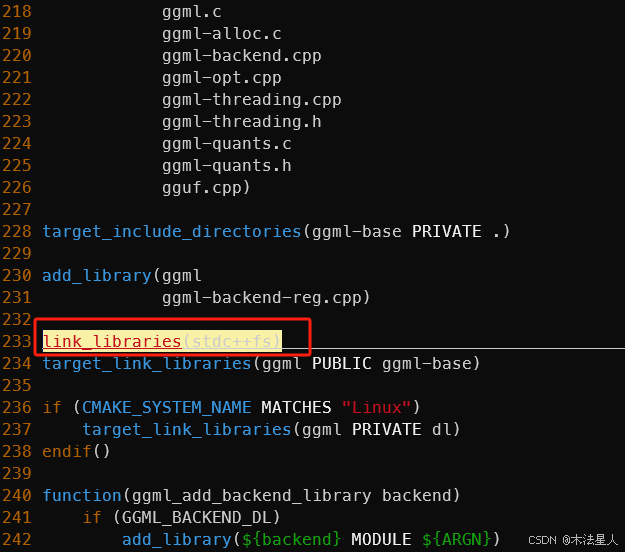
在225行后面添加一行:link_libraries(stdc++fs)
加完效果如下,记得保存:
并行构建项目,这台机只有双核,故设置为 2 个并行任务
cmake --build build --config Release -j 2
4. 检查编译结果:
成功编译后的输出如下:
到这一步,这台CentOS 8.5 系统已经可以运行 llama.cpp了,只缺个大模型。
二.安装Deepseek-R1 蒸馏模型
安装huggingface_hub
python -m pip install -U huggingface_hub
下载R1-1.5B(qwen2蒸馏)模型文件
huggingface-cli download unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf --local-dir .
跑起来
./build/bin/llama-server -m ./models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
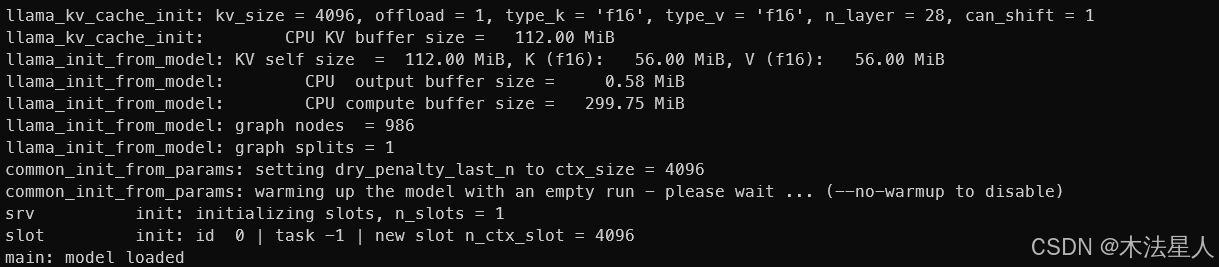
可以看到有28层网络。
三.AI Chat测试
#TODO


















 2422
2422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











