







Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Paper:https://arxiv.org/pdf/1703.03400.pdf
Code:https://github.com/cbfinn/maml
Tips:ICML的一篇Meta-learning相关的paper,可参考李宏毅的公开课。
(阅读笔记)
1.Main idea
- A : \mathcal{A:} A:We propose an algorithm for meta-learning that is model-agnostic.
- B : \mathcal{B:} B:给出了一个Meta-learning的解释:The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples.
- C : \mathcal{C:} C:本文方法可以,较少的训练步骤(一般就是仅仅几步),较少的训练样本(few-shot),得到很好的效果。In our approach, the parameters of the model are explicitly trained such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task.
- D : \mathcal{D:} D:实验部分主要有分类,回归,强化学习。
2.Intro
- A : \mathcal{A:} A:又要学得快,又要学得有泛化性,那么meta-learning就是很重要的一个方法。
- B : \mathcal{B:} B:The key idea underlying our method is to train the model’s initial parameters such that the model has maximal performance on a new task after the parameters have been updated through one or more gradient steps computed with a small amount of data from that new task.
- C : \mathcal{C:} C:从特征学习的角度:can be viewed from a feature learning standpoint as building an internal representation that is broadly suitable for many tasks.
- D : \mathcal{D:} D:From a dynamical systems standpoint, our learning process can be viewed as maximizing the sensitivity of the loss functions of new tasks with respect to the parameters.
3.Notation
每个模型就是找到 f θ f_{\theta} fθ来使输入 x t x_t xt映射到输出 a t a_t at;每个任务 T i \mathcal{T_i} Ti有如下定义: T i : { H ; q i ; L T i } \mathcal{T_i}:\{H; q_i; \mathcal{L_{\mathcal{T_i}}}\} Ti:{H;qi;LTi}
- H H H可以理解为任务的长度,对于独立同分布(i.i.d.)的分类任务来说,做一次决策即可( H = 1 H=1 H=1);而对于一些下棋游戏等强化学习,需要有很多次的决策,则 H H H值会增加。
-
q
i
q_i
qi表示分布。
C a s e ( H = 1 ) Case(H=1) Case(H=1): q ( x 1 ) q(x_1) q(x1)表示初始样本的分布;
C a s e ( H > 1 ) Case(H>1) Case(H>1): q ( x t + 1 ∣ x t , a t ) q(x_{t+1}|x_t,a_t) q(xt+1∣xt,at),每一次的决策都是上一次决策下的一个条件分布,其中第 t t t次的输出即是 a t a_t at。 - L T i \mathcal{L_{\mathcal{T_i}}} LTi表示损失函数,就是输入 x t x_t xt与输出 a t a_t at的差距,一般均方差,交叉熵损失函数。同样的,若仅仅是分类任务,仅只有 x 1 x_1 x1与 a 1 a_1 a1。
4.Details
- 有一个有很多不同任务的分布 p ( T ) p(\mathcal{T}) p(T),如Omniglot就可以自由选择得到自己想要的 N − w a y s ; K − s h o t N-ways;K-shot N−ways;K−shot的任务,而目标是让MAML模型尽可能的适应于这个多样的任务。新的任务 T i \mathcal{T_i} Ti通过简单的几个step,甚至是一个step,就能解决问题。
- 如果整体训练的话,可能是整体的好,可能并不会单独的某个任务好。For example, a neural network might learn internal features that are broadly applicable to all tasks in
p
(
T
)
p(\mathcal{T})
p(T), rather than a single individual task.
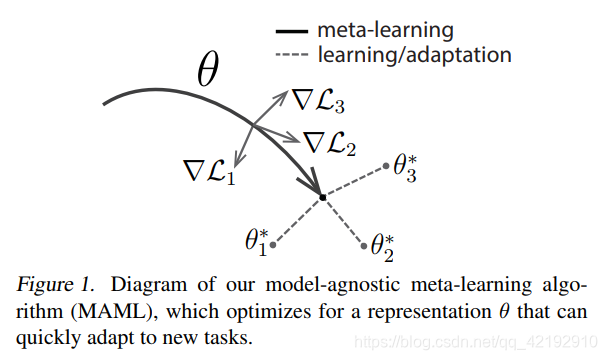
如:mnist分成两个任务:识别1-5和识别6-10。如果整体一起训练1-10,那么模型虽然能够分别处理1-5和6-10这两个任务,不过有可能每个数字的分类不一定是其当前任务的梯度降低最优的情况。 - 如下图所示,梯度的方向。其中
θ
\theta
θ是模型已经训练好了的参数,而当我们再次遇到新的Task任务
T
i
\mathcal{T_i}
Ti时候(图示是
T
1
,
2
,
3
\mathcal{T}_{1,2,3}
T1,2,3),那么我们只需要进行梯度下降算法步骤,算出损失函数的梯度方向
▽
L
i
\bigtriangledown \mathcal{L_i}
▽Li,那我们参数
θ
\theta
θ更新的方向也为其梯度的方向,最后得到
θ
1
,
2
,
3
∗
\theta_{1,2,3}^*
θ1,2,3∗。若是对新任务仅更新参数一次即有如下式:
θ i ∗ = θ − α ▽ θ L T i ( f θ ) \theta_{i}^*=\theta-\alpha \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_\theta) θi∗=θ−α▽θLTi(fθ)
新更新的参数 θ i ∗ \theta_{i}^* θi∗是第 i i i个新任务 T i \mathcal{T_i} Ti在训练好的模型参数 θ \theta θ,减去在原始 θ \theta θ的函数 f θ f_\theta fθ映射下的新任务的损失 L T i \mathcal{L_{\mathcal{T_i}}} LTi的梯度乘上 α \alpha α学习率的值。(仅一次梯度更新)
-
θ
\theta
θ这个开始训练得到的参数怎么来的呢?就是通过那一堆任务分布
p
(
T
)
p(\mathcal{T})
p(T)中抽样再训练得到的。注意到更新参数时候并不是
f
θ
f_\theta
fθ而是
f
θ
∗
f_\theta^*
fθ∗,最后优化。
min θ ∑ T i ∼ p ( T ) L T i ( f θ i ∗ ) = ∑ T i ∼ p ( T ) L T i ( f θ − α ▽ θ L T i ( f θ ) ) θ ← θ − β ▽ θ ∑ T i ∼ p ( T ) L T i ( f θ i ∗ ) \min_{\theta} \sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})=\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta-\alpha \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_\theta)})\\ \theta \leftarrow \theta- \beta \bigtriangledown_\theta\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*}) θminTi∼p(T)∑LTi(fθi∗)=Ti∼p(T)∑LTi(fθ−α▽θLTi(fθ))θ←θ−β▽θTi∼p(T)∑LTi(fθi∗) - First-order approximation:每一次优化都是对损失函数
L
T
i
\mathcal{L_{\mathcal{T_i}}}
LTi进行优化,那么每一次,参数
θ
\theta
θ都会得到有一个
θ
i
∗
\theta_i^*
θi∗,这么多Task
T
i
\mathcal{T_i}
Ti任务的影响得到最后的
θ
\theta
θ。那么可以首先改写下求和顺序:
▽ θ ∑ T i ∼ p ( T ) L T i ( f θ i ∗ ) = ∑ T i ∼ p ( T ) ▽ θ L T i ( f θ i ∗ ) \bigtriangledown_\theta \sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})=\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*}) ▽θTi∼p(T)∑LTi(fθi∗)=Ti∼p(T)∑▽θLTi(fθi∗)
先拿掉每个任务Task的求和符号,单独讨论一个任务的情况,对 θ \theta θ的每一个参数(假设数目为 j j j)进行微分偏导,那么最后则有下式。 θ k ∗ \theta_k^* θk∗是每一个参数最后造成对 θ ∗ \theta^* θ∗的影响。 i i i是初始设置的参数,而 k k k是最后模型的一次梯度下降的参数。
▽ θ L T i = ∂ L ( θ ∗ ) ∂ θ j → ∑ k ∂ L ( θ ∗ ) ∂ θ k ∗ × ∂ θ k ∗ ∂ θ j \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}} = \frac{\partial \mathcal{L(\theta^*)}}{\partial \theta_j} \rightarrow \sum_{k} \frac{\partial \mathcal{L(\theta^*)}}{\partial \theta_k^*} \times \frac{\partial \theta_k^*}{\partial \theta_j} ▽θLTi=∂θj∂L(θ∗)→k∑∂θk∗∂L(θ∗)×∂θj∂θk∗
代入 θ ∗ \theta^* θ∗与 θ \theta θ关系则有:
∂ θ k ∗ ∂ θ j = ∂ ( θ k − α × ∂ L ( θ ) ∂ θ k ) ∂ θ j \frac{\partial \theta_k^*}{\partial \theta_j} = \frac{\partial (\theta_k-\alpha \times \frac{\partial \mathcal{L(\theta)}}{\partial \theta_k} )}{\partial \theta_j} ∂θj∂θk∗=∂θj∂(θk−α×∂θk∂L(θ))
若 k k k与 j j j不相等, ∂ θ k ∂ θ j \frac{\partial \theta_k}{\partial \theta_j} ∂θj∂θk就没有了,仅有 − α × ∂ 2 L ( θ ) ∂ θ j ∂ θ k -\alpha \times \frac{\partial^{2}\mathcal{L(\theta)}}{\partial \theta_j \partial \theta_k} −α×∂θj∂θk∂2L(θ);若 k k k与 j j j相等,则是 1 − α × ∂ 2 L ( θ ) ∂ θ j ∂ θ k 1-\alpha \times \frac{\partial^{2}\mathcal{L(\theta)}}{\partial \theta_j \partial \theta_k} 1−α×∂θj∂θk∂2L(θ)。若为了简便不想算二阶偏导,即让第一项为0,第二项为1,即是First-order approximation。 - benchmark一般用的数据集是Omniglot和mini-ImageNet。
更具体地:MAML与迁移学习相关的pre-training是有区别的:- MAML是对很多组support/query set不同的task进行训练,所以模型在每一组任务的表现都会是同等条件下训练的最好结果,但是其得到的 ϕ \phi ϕ并不一定是(通常是)最优的解,更需要一定的小步数特定任务的训练才能达到对该任务的优秀能力,得到其参数 θ ^ n \hat{\theta}^n θ^n。可以理解为更看重这个model的潜力怎么样。
- Pre-training是很多种不同的数据一同收敛到最优的地方,但不一定是每个具体某一类数据最优的地方,所以其处理的参数一直都是整体的参数
ϕ
\phi
ϕ。可以理解为当前这个模型一步一步训练是怎么样,结果就怎么样。
L ( ϕ ) = ∑ n = 1 N L n ( θ ^ n ) L ( ϕ ) = ∑ n = 1 N L n ( ϕ ) \mathcal{L(\phi)}=\sum_{n=1}^{N}L^n(\hat{\theta}^n) \\ \mathcal{L(\phi)}=\sum_{n=1}^{N}L^n(\phi) L(ϕ)=n=1∑NLn(θ^n)L(ϕ)=n=1∑NLn(ϕ)















 5496
5496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









