






 本文深入浅出地解释了Seq2Seq模型在机器翻译中的应用,特别是结合Attention机制的工作原理。通过可视化的方式,阐述了编码器如何处理输入序列并生成上下文向量,以及解码器如何利用注意力机制在每个时间步关注输入序列的相关部分,从而提高翻译质量。
本文深入浅出地解释了Seq2Seq模型在机器翻译中的应用,特别是结合Attention机制的工作原理。通过可视化的方式,阐述了编码器如何处理输入序列并生成上下文向量,以及解码器如何利用注意力机制在每个时间步关注输入序列的相关部分,从而提高翻译质量。
Sequence-to-sequence(序列到序列)是一种深度学习模型,在机器翻译,文本摘要和图像标注等任务中取得了很好的效果。谷歌翻译在2016年底开始使用这种模型。两篇论文解释了这些模型(Seq2Seq,http://emnlp2014.org/papers/pdf/EMNLP2014179.pdf)
然而我发现,充分理解模型并实现它需要理解一系列相互叠加的概念。我觉得可视化模型会让人更容易理解——这就是我写这篇文章的原因。在阅读本文之前你要知道一些深度学习方面的知识。我希望这篇文章可以让你更容易理解上面两篇以及未来有关的论文。
序列到序列模型是输入一个序列(如词,段落,图片特征等等),然后输出一个序列的模型。一个训练模型工作方式如下图:
height="198" width="650" src="https://jalammar.github.io/images/seq2seq_1.mp4">一个在神经网络翻译中,序列是一系列词,模型一个词一个词的处理,输出一系列词。
height="198" width="650" src="https://jalammar.github.io/images/seq2seq_2.mp4">工作原理
模型内部是由编码器(encoder)和解码器(decoder)组成。
编码器处理每个输入的序列,它将它从序列中捕获的信息转为向量(称为上下文 context)。在处理完整个输入序列后,编码器发送上下文给解码器,然后解码器逐项的生成输出的序列。
机器翻译模型是同样原理
height="198" width="650" src="https://jalammar.github.io/images/seq2seq_4.mp4">在机器翻译中,上下文是向量(最基本的是数组)。编码器和解码器往往都是递归神经网络(recurrent neural networks,RNN)(RNN的介绍见“https://www.youtube.com/watch?v=UNmqTiOnRfg”)

你可以在建模的时候设定上下文的大小。它基本上是编码器RNN的隐藏神经元的数量。上面的图显示了一个大小为4的向量,但是实际应用中上下文向量的大小一般是256,512或者1024.
根据设计,一个RNN在每个时间步(time step)需要两个输入:一个输入内容(在编码器的情况下,输入内容是一个句子中的一个词)和一个隐藏层状态(hidden state)。其中输入内容——词,需要转为向量(机器只能识别数字不能识别字母)。为了将词转为向量,我们需要使用词嵌入技术。
(word embedding “https://machinelearningmastery.com/what-are-word-embeddings/“)
词嵌入技术可以将单词转为向量空间,向量空间可以保存词的意义和语义信息。(虽然这样翻译,但是实际上就是将词映射成向量,将向量“嵌入”到空间中,然后所有词构成一个空间。向量的大小和向量在空间的位置可以表示词本身的意思和每个词之间的关系)
(例子:king-man+woman = queen见”http://p.migdal.pl/2017/01/06/king-man-woman-queen-why.html“)
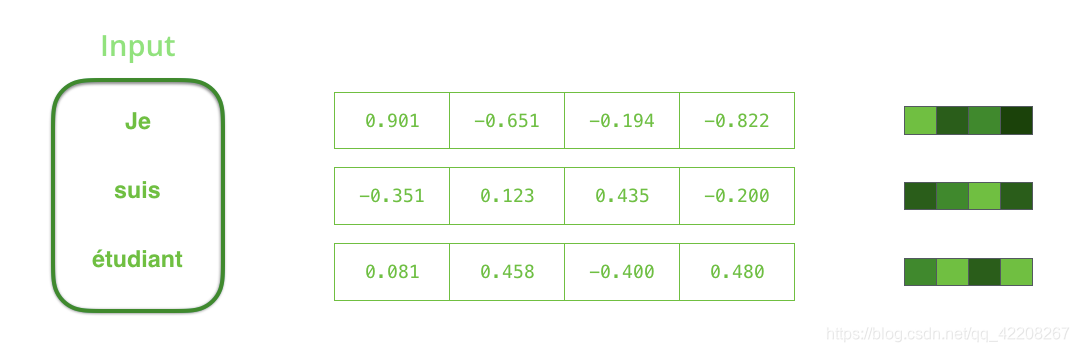
现在我们已经介绍了向量/张量(tensors),让我们以动画的方式回顾一下RNN的运行机制。
height="198" width="650" src="https://jalammar.github.io/images/RNN_1.mp4">下一步RNN使用第二次输入的向量和隐藏层状态#1来创建该时间步的输出。(时间步-time step 虽然这样翻译,但是我觉得就是时刻的意思,只不过是离散的时间,一些人直译为时间步了,我就跟着翻译)
在接下来的动画中,编码器和解码器的每次闪烁都是处理其输入并产生该时间步的输出。由于编码器和解码器都是由RNN构成,所以每次RNN进行处理时,都是根据输入和之前已知的输入更新其隐藏层状态。(就是之前多次输入的结果和本次输入的内容叠加,本次输出结果与前文相关)
让我们看一下编码器的隐藏层状态。注意最后的隐藏层状态实际上是我们传给解码器的上下文
解码器隐藏状态的更新和编码器类似,不赘述。
现在让我们从另一个角度观察一下Seq2Seq模型。下面这个动画更容易理解描述上述模型的静态图形。这是一个整体描述,我们显示了每个时间步模型的状态,而不仅是一个编码器。这样我们可以观察到每个时间步的输入和输出。
注意力机制(Attention)
上下文向量是提升模型性能的瓶颈,因为它无法处理长句子(1.计算量大大增加,2、每个词对下个状态影响的程度相同)。一种解决办法就是注意力机制(见论文: Bahdanau,Luong)这两篇论文介绍了一种叫注意力(Attention)的技术,它可以极大的提高翻译系统的质量。注意力可以让模型关注输入序列中所需要的部分。
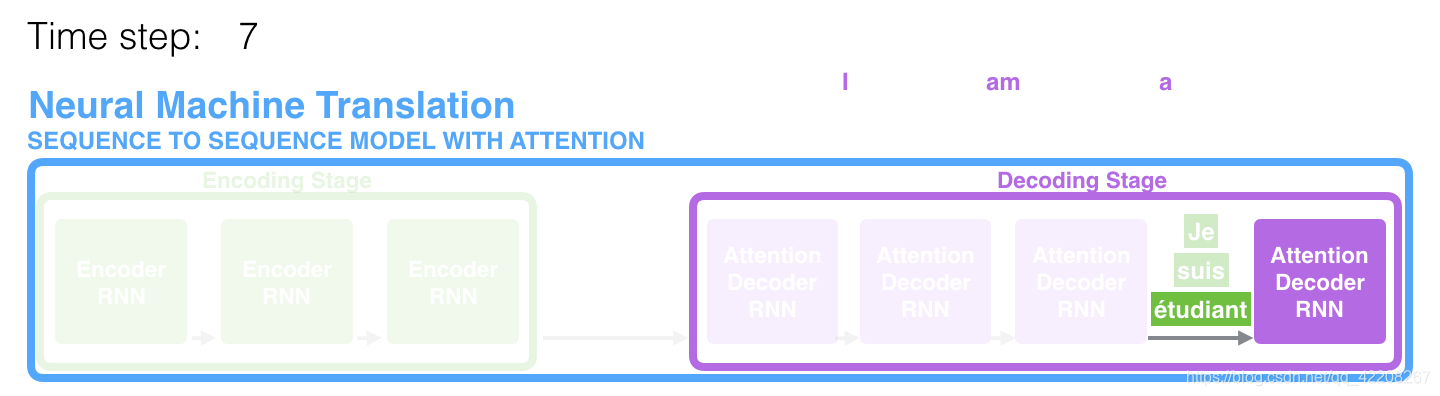
如图,注意力机制可以让解码器在将"étudiant" (“student” 的法语表示)翻译成英文时给"étudiant"更多的关注(权重),这种将输入序列相关部分放大(权重增加)的能力使得有注意力机制的模型效果比没有的好很多。
让我们继续以高度抽象的方式观察注意力模型。注意力模型和传统Seq2Seq(序列到序列)模型有两个主要不同:
首先,编码器传送给解码器更多的数据。与原始模型只传递最后隐藏层不同的是,注意力模型传递所有的隐藏层给解码器。
height="298" width="650" src="https://jalammar.github.io/images/seq2seq_7.mp4">其次,注意力模型的解码器在输出之前会多一个额外的步骤。为了聚焦输入与解码器里本时间步相关的部分,解码器做了以下工作:
1.查看它接收到的编码器的隐藏状态集-每个隐藏状态与当前输入的序列中某个单词最相关。(就是一个状态 对应 一个词 与其他所有词的 相关度)
2.给每个隐藏状态一个分数(这里我们先忽略它是怎么打分的)
3.让每个隐藏层状态得分使用softmax进行归一化,这样就可以放大高分,淹没低分(分数经过softmax函数后得到一个0-1之间的数,softmax就是让高分的更高,低分的更低)
这个打分的动作在解码器每一个时间步都会执行。
现在让我们看看整个编码解码过程并观察其中注意力是怎么工作的。
1.注意力解码器RNN接收到输入的 (end就是序列结束的标记,数据处理时我们自己添加的),和一个初始的解码器状态。
2. RNN处理输入,产生输出和一个新的隐藏层状态向量(h4),输出被丢弃。
3. 注意力步骤:这一个时间步我们使用编码器隐藏层状态和h4向量计算上下文向量(C4)
4. 我们将h4和C4组合成一个新向量
5. 让这个新向量通过前馈神经网络(feedforward neural network,模型中的一种训练方式)
6. 前馈神经网络的输出表示本次时间步输出的词(字)
7. 下一个时间步重复以上步骤,直至结束。
下面是从另一个角度查看每个解码步骤中注意力机制在输入序列(输入句子)的作用情况。
height="358" width="650" src="https://jalammar.github.io/images/seq2seq_9.mp4">请注意,注意力机制模型不仅仅无意识的将输入序列的第一个词和输出序列中的第一个词对齐,它实际上在训练阶段就学会了如何对齐语言中的单词(我们的例子中是法语和英语)。上面给的论文中有这种机制对应准确度的例子:

可以看到注意力模型翻译的准确度,英语中European Economic Area在法语中对应顺序是反转的(“européenne économique zone”),它也能很好的对应起来。
如果你觉得理解的差不多了,想动手试试,可以查看以下链接Neural Machine Translation (seq2seq) Tutorial
以上动画来自于优达学院

















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









