







概述
本节讲解了机器学习从选定模型到定义代价函数再到优化模型的三部曲。李老师以他的油管视频日访问量的预测为切入点,讲解机器学习算法的开发三步骤。
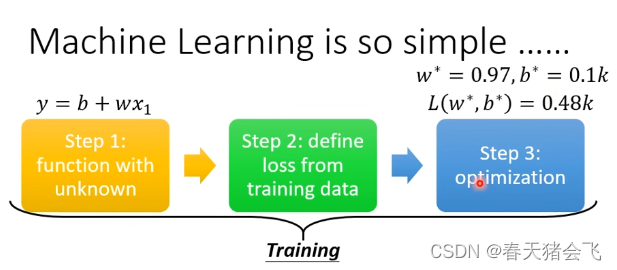
一、机器学习步骤(三部曲)
-
Function with Unknown Parmeter
即选定一个model 需要依靠domain knowledge -
Define Loss from Training Data(从训练数据中定义代价函数)

注意李老师只讲到两种e值,一种是绝对值误差,另一种是均值平方差误差,除此之外还有别的e的形式,只不过未涉及。 -
Optimization
解一个最佳化,即找到最佳的参数,使得代价函数取得最佳的结果
方法:Gradient Descent(梯度下降)求得Loss最低值
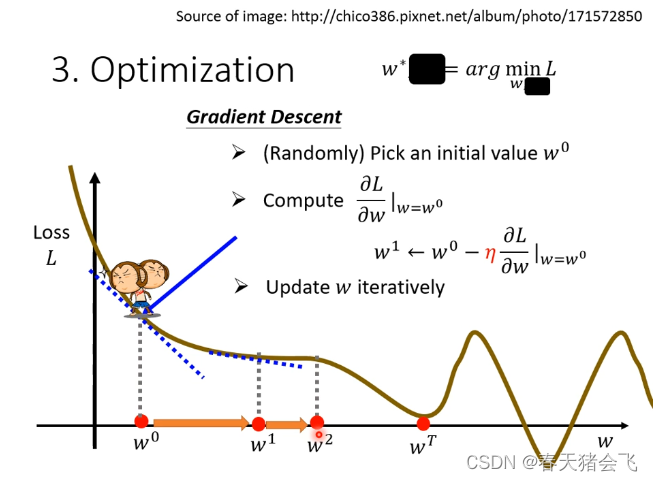
有一个问题,就是可能找不到全局最优情况(global minima),而只是找到局部最优(local minima)。(但实际上,Local minima 是个伪命题,这个后续再讲)
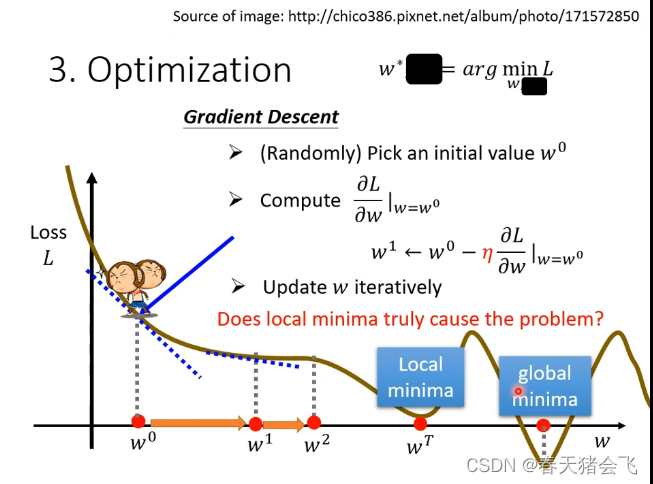
η:为学习速率,是一种hyperparameter(即设计者预设计的参数,而非通过训练得来的参数,译为:超参数)
做法:

深入思考:
进一步调整,如果在模型考量扩大feature(即输入)的考量,对应在李老师的例子中,即考虑更多的x,也就是统计更多天的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A53sBS7d-1659884599610)(第一节 机器学习与深度学习基本概念.assets/1659872155775.png)]](https://img-blog.csdnimg.cn/da92ccee126946a49cd5ece3edd50aa1.png)
二、升级(依然三部曲:找模型,定义Loss,优化)
1.构建模型
线性模型毕竟还是太简单,我们需要更完善的模型,由于模型自身不足产生的限制,被称为 Model Bias
引入:某一条曲线 = 某个常数 + 一组重复曲线(可以通过各种组合凑出)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Igb4j7Zq-1659884599610)(第一节 机器学习与深度学习基本概念.assets/1659867689845.png)]](https://img-blog.csdnimg.cn/0c2c62399f8d44a38ee0f226f7a753fa.png)
蓝色笔直的那条曲线称为:Hard Sigmoid , 而
通过不断的调参,可以用sigmoid曲线去逼近任何曲线
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K0FOBCBd-1659884599611)(第一节 机器学习与深度学习基本概念.assets/1659868294505.png)]](https://img-blog.csdnimg.cn/1beccdc4ebb547f2be3e5777780f5c08.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KSTk4AhC-1659884599612)(第一节 机器学习与深度学习基本概念.assets/image-20220807230249060.png)]](https://img-blog.csdnimg.cn/6f2d4ec7be8549c0a7df55f7070cb8f7.png)
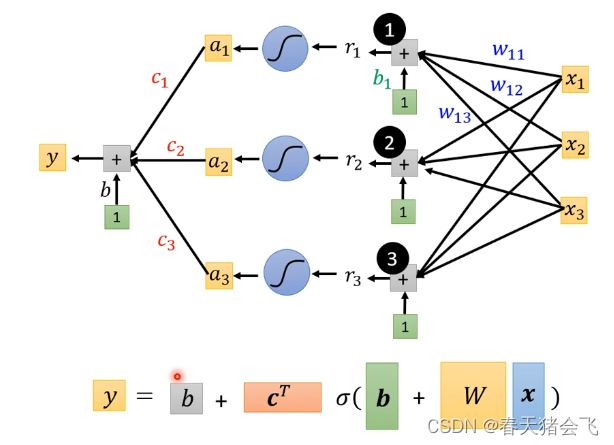
由此模型得到确认。所有的位置的参数全部放入一个θ向量中。
2.定义Loss 函数
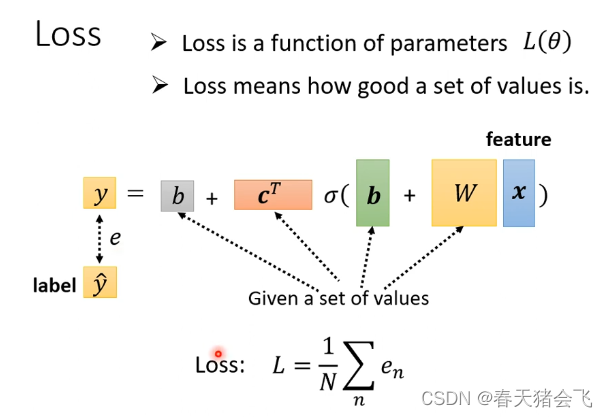
3.新模型的优化
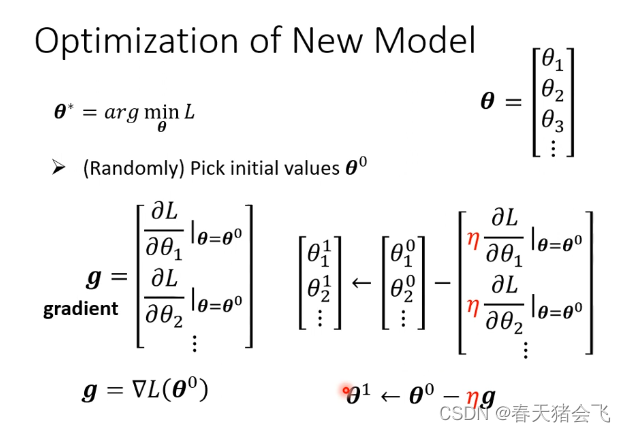
然后频繁使用梯度下降:

实际上所有的训练数据会分为很多的batch,所有的batch称为一个epoch
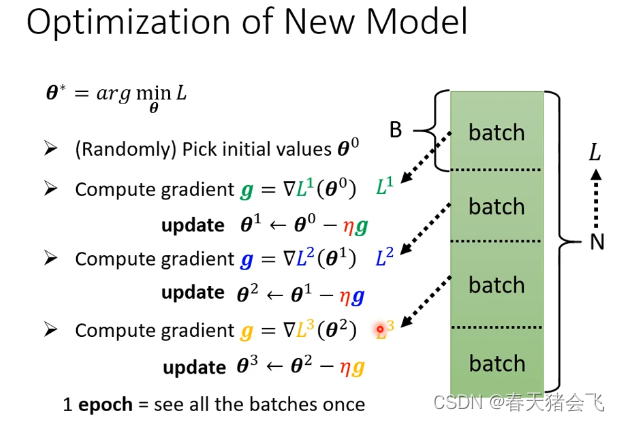
所以,batch size也是一个hyperparameter
进一步:为什么不使用hard sigmoid?
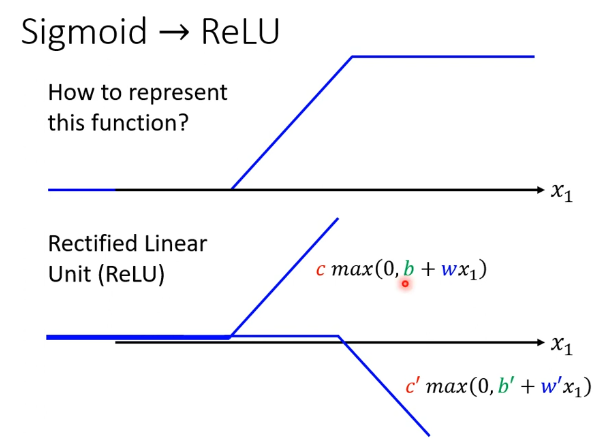
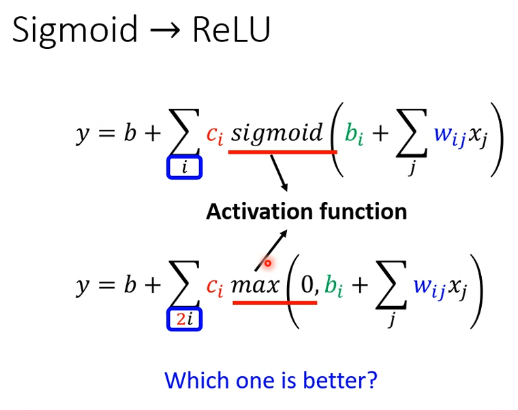
再深入:分层,更多的layer似乎会使预测更加的准确
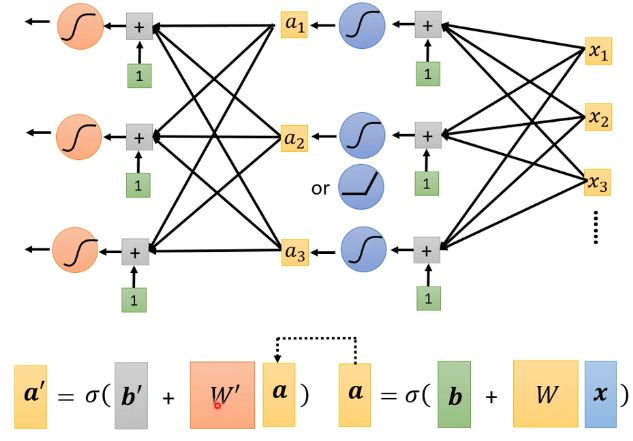
分层之后,给它取个高大上的名字:神经网络–》又改名为 深度学习
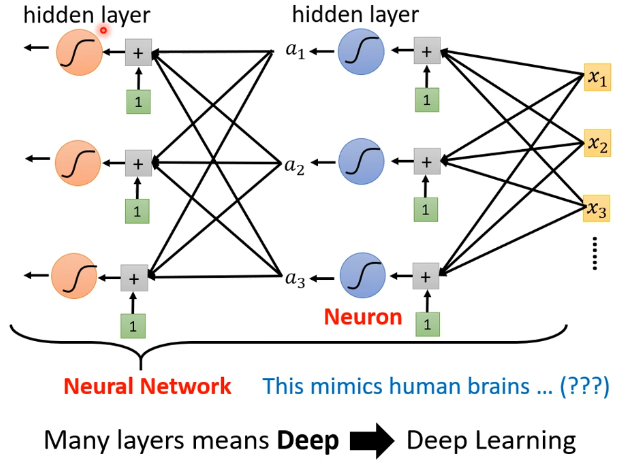
问题来了:为什么只把Network“变深”而不是“变胖”呢?
过拟合(overfitting):

最终我们选择的是3layer的模型,为什么?















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









