







论文地址:Real-time Scene Text Detection with Differentiable Binarization
又是白翔老师组的产出。tql
这篇文章仍然是基于语义分割的文本检测算法。
概述
目前,基于语义分割的方法很多,它们可以更准确地描述不同形状的文本。但是一般这些方法都会配有二值化的post processing,将概率的分割图转化为文本或者非文本区域。作者这里提出了一个Differentiable Binarization (DB),可以自适应地设置阈值来做二值化处理,不仅能够简化post processing,而且还能够增强文本检测的效果。并且,以前的binarization操作是在inference的post processing部分,而这里,作者直接把这个操作放到分割任务一块,联合优化。
普通的二值化操作无非就是先预设一个阈值,对于预测得到的每个pixel的概率值,如果超过这个阈值就设为1,否则就是0,如果把这个操作放在优化过程中,可以发现这个操作并不可微,所以作者提出了DB,设计了一个可微的二值化操作。
方法

Differentiable binarization
首先看标准的二值化操作:
P
∈
R
H
×
W
P\in R^{H\times W}
P∈RH×W是一个概率图,
t
t
t是预设的阈值。
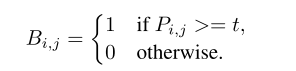
作者设计的DB:
B
^
i
,
j
=
1
1
+
e
−
k
(
P
i
,
j
−
T
i
,
j
)
\hat B_{i,j}=\frac{1}{1+e^{-k(P_{i,j}-T_{i,j})}}
B^i,j=1+e−k(Pi,j−Ti,j)1其中,
T
i
,
j
T_{i,j}
Ti,j是一个阈值矩阵在
(
i
,
j
)
(i,j)
(i,j)处的值。
k
k
k是一个因子,这里根据经验设置为50。
label generation
我们需要得到ground truth的两个map:probability map和threshold map。
数据集一般提供了文本的形状的多边形节点表示 G = { S k } k = 1 n G=\{S_k\}^n_{k=1} G={Sk}k=1n, S k S_k Sk表示第 k k k个文本, n n n是指每个文本区域的多边形由几个corner组成。
probability map:将 G G G向内缩小偏移量 D D D得到 G s G_s Gs, G s G_s Gs内部标记为1,外面标记为0;
threshold map:将 G G G向外放大偏移量 D D D得到 G d G_d Gd, G d G_d Gd和 G s G_s Gs之间的区域作为文本的边界,这其中的每个点对应的值由该点到 G G G最近的一条边的距离得到。
D
D
D的计算和PSENet中类似:
D
=
A
(
1
−
r
2
)
L
D=\frac{A(1-r^2)}{L}
D=LA(1−r2)
虽然binary map没有在论文的label generation部分提到,但其在损失函数的计算中出现了,貌似binary map和probability map一样?待看完代码求证后再记录。
损失函数
L
=
L
s
+
α
×
L
b
+
β
×
L
t
L=L_s+\alpha \times L_b+\beta \times L_t
L=Ls+α×Lb+β×Lt前面两个是probability map和binary map的损失函数,这里使用的是BCE。且正负像素点的采样按照1:3。
最后那个是threshold map,使用L1范数。
Inference
Inference阶段就是要根据得到的几个map,计算出文本区域的bounding box。
三个步骤:
- 对probability map或者approximate binary map二值化,得到一个binary map;
- 对上步得到的binary map提取出每个联通分量;
- 因为前面我们计算的时候,将文本区域向内偏移了一个变量 D D D,这里inference时需要再进行向外的偏移。这时的偏移量是 D ′ D' D′,且 D ′ = A ′ × r ′ L ′ D'=\frac{A'\times r'}{L'} D′=L′A′×r′。















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









