







文章目录
前言
本文主要记录在部署阿里达摩院开源实时数字人对话VideoChat时遇到的问题,希望对各位技术开发或爱好者有所帮助!
资料链接
• 参考资料:开源数字人实时对话:形象可自定义,支持语音输入,对话首包延迟可低至3s|已上线阿里ModelScope魔搭社区
• 开源地址:https://github.com/Henry-23/VideoChat
技术原理
目前数字人实时对话方法
- Linly Talker,基于Gradio的数字人对话项目,多模型集成,功能丰富,但不支持实时对话和流式输出。(个人理解:意思就是)
- LiveTalking,基于流媒体的数字人生成项目,数字人响应快,但交互界面比较简陋,且需要配置服务器,部署难度较高。
- awesome-digital-human-live2d,基于Dify编排的数字人互动项目,轻量化,交互方式丰富,但数字人形象不够真实,且不支持口型同步。
• 基于此,VideoChat实现了一个基于开源的技术方案、支持语音输入和实时对话、数字人形象真实且口型同步、可在线试用的开源数字人实时对话demo。
方法/工作流概述
技术选型:
• ASR (Automatic Speech Recognition): FunASR
• LLM (Large Language Model): Qwen
• TTS (Text to speech): GPT-SoVITS, CosyVoice, edge-tts
• THG (Talking Head Generation): MuseTalk

并行流水线架构
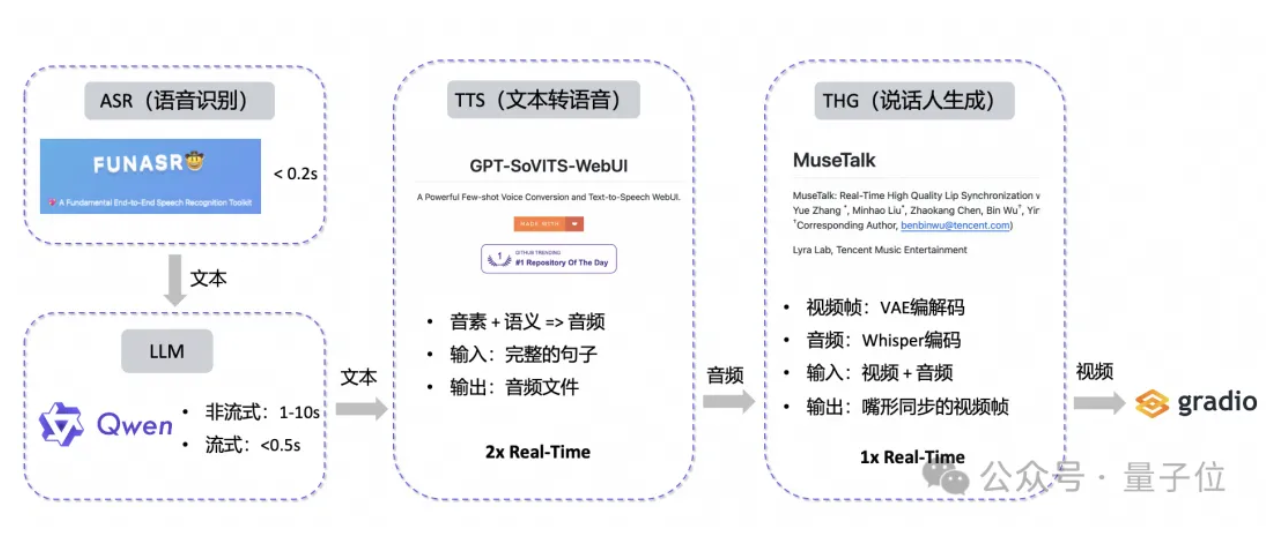
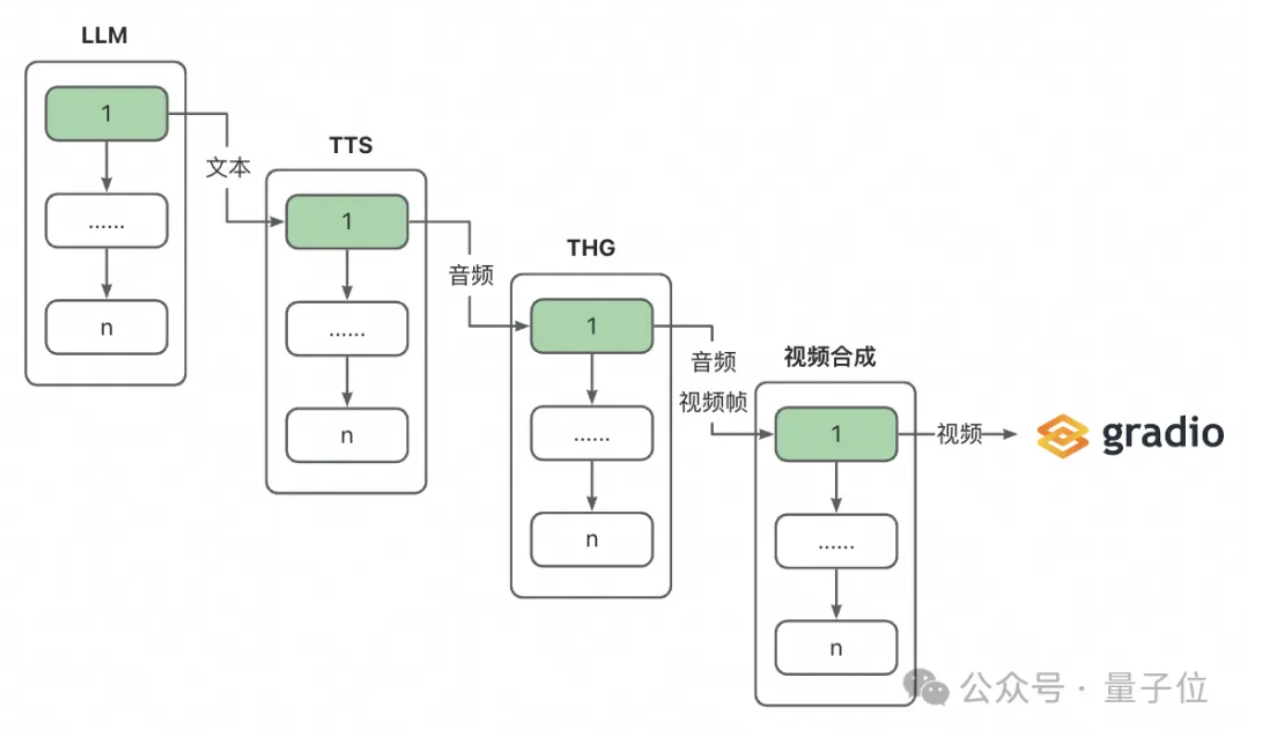
• 如上,维护多个队列,分别保存LLM生成的句子、TTS生成的音频和THG生成的视频帧,并结合多线程进行并行处理。这使得在完成第一个句子的处理后即可开始数字人的响应,边推理边播放,极大地降低了用户的等待时间。
性能水平
• 研究人员实测在A100/V100上,首包延迟可低至为3s。
先附上安装环境
备注:官方的requirements.txt中的环境实测不行!需要我们自己配环境!
注意:以下环境(包版本)已经过测试,可用!
所需要的包:
gradio==5.4.0
modelscope_studio==0.5.2
omegaconf==2.3.0
ffmpeg-python==0.2.0
opencv-python==4.9.0.80
numpy==1.23.0
dashscope
soundfile==0.12 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2696
2696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









