









本文只总结我对Dice Loss的一些理解,如有不同见解欢迎批评指正
1、首先简单介绍一下,这个不多说,详细如知乎所讲。
Dice 定义为2倍交集/和, 范围在[0,1]:
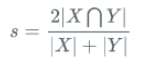
Dice Loss 取反或者用1-,定义为:
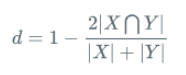
2、Dice Loss 与 BCE 的结合各自的作用。
Dice Loss与交叉熵经常搭配使用,具有以下优点:
1)Dice Loss相当于从全局上进行考察,BCE是从微观上逐像素进行拉近,角度互补。
2)当出现前后景极不均衡情况时。如一个512*512的图片只有一个10*10的分割样例。BCE全蒙背景依旧可以觉得效果很好,此时BCE无法解决这种极度不均衡情况。Dice Loss却不受前景大小的影响。
3)当出现分割内容不均衡情况时。如一个512*512的图片有一个10*10和一个200*200的分割样例。Dice Loss此时会趋向于学习大的块,而忽略小样本。但BCE依旧会对小样本进行学习。
4)BCE对Dice可以起到引导作用。如一个512*512的图片只有一个10*10的分割样例。如果在初始化时,预测结果完全没有在10*10范围内,此时Dice为0。如果只有Dice Loss则无法学习到正确的梯度下降方向。加上BCE可以给网络一个学习的方向。
3、Dice Loss实现
Dice 的官方实现(应该是吧)可以见github地址。
但一般我们用直接使用博客这样的
import torch.nn as nn
import torch.nn.functional as F
class SoftDiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(SoftDiceLoss, self).__init__()
def forward(self, logits, targets):
bs = targets.size(0)
smooth = 1
probs = F.sigmoid(logits)
m1 = probs.view(bs, -1)
m2 = targets.view(bs, -1)
intersection = (m1 * m2)
score = 2. * (intersection.sum(1) + smooth) / (m1.sum(1) + m2.sum(1) + smooth)
score = 1 - score.sum() / bs
return score区别有二
1)官方Forward中返回的np.sum(dice), 实际我们使用是 1 - score.sum()/num
2) 官方有backward, 我们常用的没有backward。
对于区别一,我们根据常识觉得第二种1 - score.sum()/num很符合常理。第一种返回np.sum(dice)莫名其妙,这怎么训练?
其原因就在于官方有自己的backward,所以不影响训练。
第二种方法没有backword是因为继承了nn.Module。该类可以自动实现backward。
4、讲个面试时候遇到的问题
假设输入尺寸为 [bs, c, w, h] 我们一般可以看到两种实现方式。
1)官方实现为对batch维度挨个计算Dice并求和。
2)当然也可以直接转换为一维然后计算Dice。
两种方法有区别吗?还是有的。
我们假设bs=2,w=h=512,其中bs1包含了200*200的病灶,且分割Dice=1。 bs2中包含了10*10病灶,Dice=0.
那么按照第一种,Dice =(1+0)/ 2 = 0.5
第二种, Dice = 2*交/和 = 2*200*200/(200*200 + 200*200 + 10*10)
所以第一种能解决bs之间不均衡的情况。因为他不会因为batch中大块的病灶而忽略小块的。
尴尬的是,我以为我用的第一种是对Dice Loss的一个机智的改进。但是面试官直接说Dice Loss本来就是这么实现的。吹牛不成,太丢人了。

















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









