







Motivate
Conventional NAS method search for a novel architecture from scratch for a given unseen dataset, such task-specific methods search for a neural architecture from scratch for every given task, they incur a large computational cost.
This paper proposed an efficient NAS framework that is trained once on a database consisting of datasets and pretrained networks and can rapidly search for a neural architecture for a
novel dataset.
A meta-performance predictor was also introduced to estimate and select the best generated architecture.
Dataset
Dataset for training
To meta-learn our model, we practically collect multiple tasks where each task consists of (dataset, architecture, accuracy).
ImageNet-1K is compiled as multiple sub-sets by randomly sampling 20 classes and search for the set-specific architecture of each sampled dataset using random search among high-quality architectures
For the predictor, we additionally collect 2,920 tasks through random sampling
Method
Generator training
We meta-learn the model using:
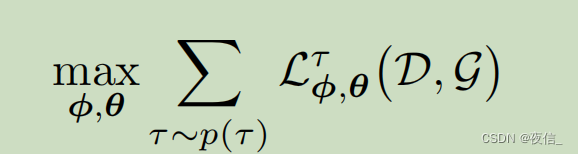
where:
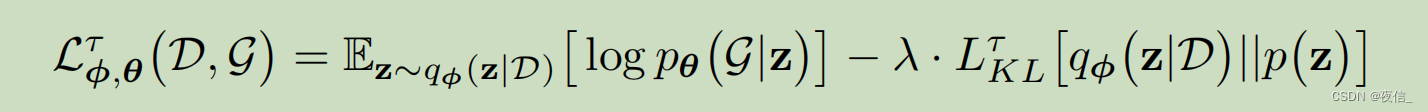 the first term of the objectve can be rewritten as :
the first term of the objectve can be rewritten as :
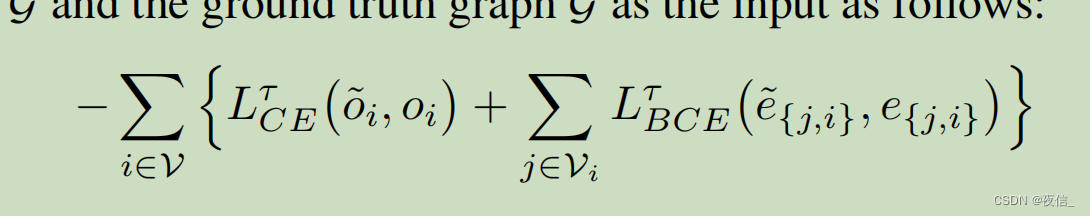
Oi denote nodes and e ji denote edges
MetaTest
Graph Decoding
For a given dataset, sample num_sample instances per category , concat and feed them into Set encoder. After encode the give dateset, a batch of set-dependent latent codes z can be obtained from dataset-conditioned Gaussian distribution taking the encoded unseen dataset as input.

When generating i-th node Vi, we will compute the operation type O over N candidate operation of this node based on current graph state Hg = Hvi-1
Ovi is defined as follows:
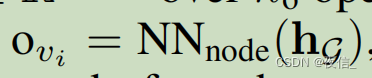
We update the hidden state Hvi as follows:
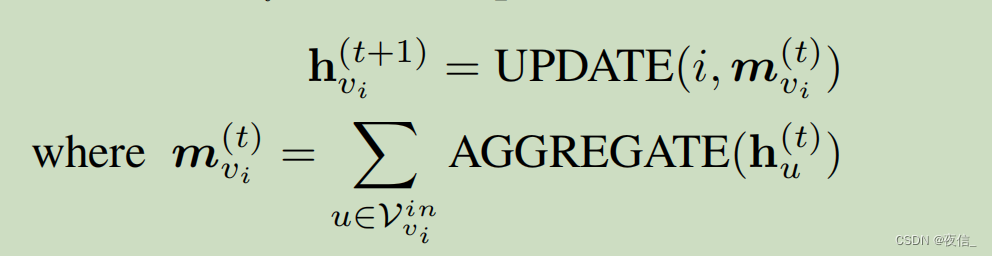
function UPDATE is a GRU, m is the incoming message to vi
we decide whether to link an edge vj to vi based on edge connection e{vj, vi} = N N e d g e ( h j , h i ) NN_{edge}(h_j, h_i) NNedge(hj,hi), incorporating the initial state H 0 H_0 H0 is also feasible .

Accuracy prediction
After we generated the set-dependent architectures, the predictor will predict accuracies
S
i
S_i
Si for a give unseen dataset
D
i
D_i
Di and each generated candidate architecture
G
i
G_i
Gi and then select the architecture with highest predicted accuracy.
Set encoder
Inputting the sampled instances into the IntraSetPool, the intra-class encoder, to encode
class prototype
V
c
∈
R
b
a
t
c
h
∗
d
x
V_c \in \R^{batch * d_x}
Vc∈Rbatch∗dx for each class
c
=
1.......
C
c=1.......C
c=1.......C. Then we further feed the class-specific set representations
V
c
V_c
Vc into the InterSetPool, the inter-class encoder, to generate the dataset
representation
H
H
H as follows:
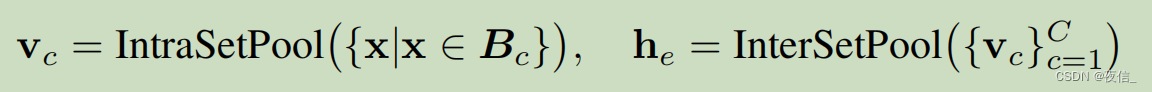















 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









