







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/(下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单。
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是2828,数据集样本如下:

如果我们把每一张图片中的像素转换为向量,则得到长度为2828=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。

神经网络程序说明
建议先学习一下深度学习的理论知识,不然理解起来有点点困难(我是先在b站看了一点【李沐】动手学深度学习)。
神经网络程序可以简单概括如下:
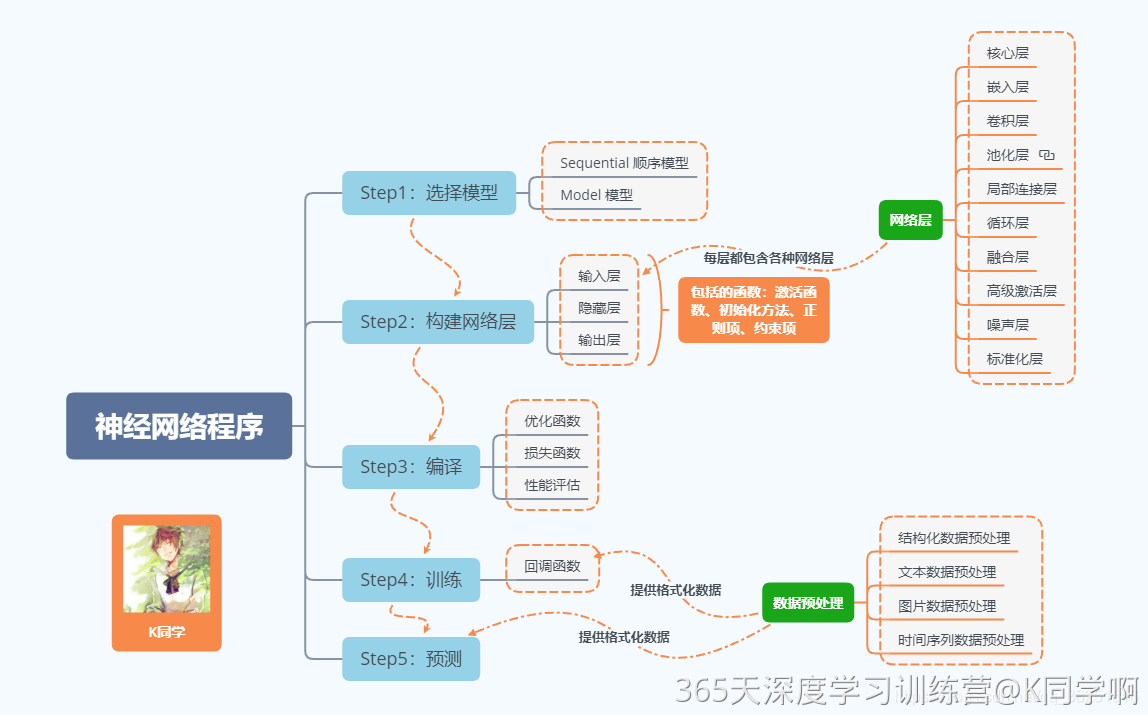
一、创建环境
-
🏡我的环境:
- ● 语言环境:Python3.8
- ● 编译器:pycharm专业版
-
● 深度学习环境:TensorFlow2
运行环境: colab
二、前期准备
2.1 设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
2.2 导入数据
2.2.1 在TensorFlow框架中导入MNIST数据集
import tensorflow as tf # 导入TensorFlow库,并将其命名为tf
from tensorflow.keras import datasets, layers, models # 从TensorFlow的keras子模块中导入了datasets、layers和models。datasets包含了常用的数据集,比如MNIST和CIFAR-10;layers是用于构建神经网络层的模块;models则是用于创建模型的高级接口。
import matplotlib.pyplot as plt
# 下载并导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()

2.2.2 数据归一化
📑归一化与标准化是特征缩放的两种形式,其作用是:
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。加快学习算法的收敛速度。
- 归一化是将数据“拍扁”统一到区间(仅由极值决定),而标准化是更加“弹性”和“动态”的,和整体样本的分布有很大的关系
👉归一化:把数变为(0,1)之间的小数;缩放仅仅跟最大、最小值的差别有关。
👉标准化:将数据按比例缩放,使之落入一个小的特定区间;缩放与每个点都有关
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
结果如下:

2.3数据可视化
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()
可视化结果如下:

2.4 调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
输出:

三、构建简单的CNN网络(卷积神经网络)
3.1 代码参照为以下网络结构:
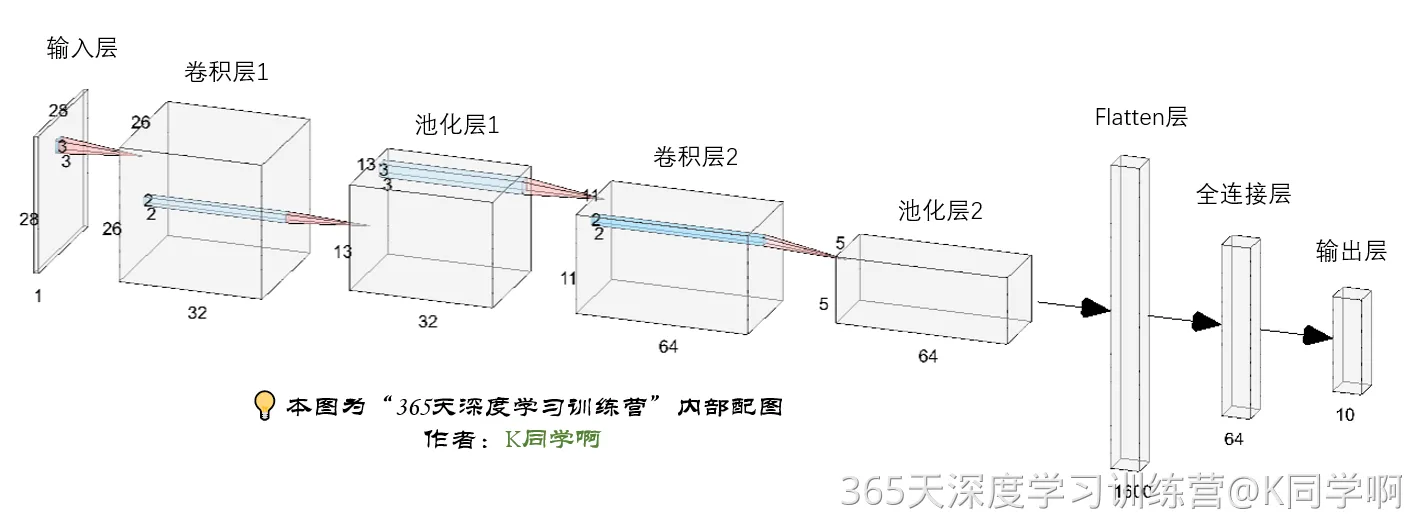
使用TensorFlow的Keras API来创建一个卷积神经网络(CNN)。
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
#池化层1,2*2采样
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
#池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()
model = models.Sequential()
创建一个Keras的Sequential模型,这是一种线性堆叠模型,各层之间是顺序的。
网络结构如图:

3.2 编译模型
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
四、训练模型
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))

五、预测
查看测试集中第三张图片:

预测结果:
输出的这组数组代表这张图片上的数字为0~9中每一个数字的几率(并非概率),out数字越大可能性越大,可以看到数字为0的几率是27+,所以预测这张图片最有可能的结果为0

六、总结
本次学习了特征的归一化和标准化。
归一化和标准化是数据处理中两种常用的技术,它们用于改变数据的规模和分布,以便更好地适应机器学习算法的要求。
归一化(Normalization):
- 定义: 归一化通常是指将数据缩放到一个固定的范围,通常是0到1之间。
- 应用:
当知道数据的最大值和最小值时。
当数据分布不是高斯分布时。
在神经网络中,归一化可以帮助加快学习过程。 - 特点:
受异常值影响较大。
改变了数据的分布范围,但不一定改变数据的分布形状。
标准化(Standardization):
- 定义: 标准化是指将数据转换为具有零均值和单位方差的过程。
- 应用:
当数据遵循高斯分布(正态分布)时。
在使用一些假设数据服从正态分布的算法时,如线性回归、逻辑回归、支持向量机等。 - 特点:
对异常值相对不敏感。
保持了原始数据的分布形状,但改变了数据的单位。
比较:
6. 范围:归一化将数据缩放到[0, 1]或[-1, 1]区间,而标准化将数据转换为具有零均值和单位方差。
7. 稳定性:标准化对异常值的影响较小,因为它依赖于均值和标准差,而归一化可能会受到异常值的影响。
8. 算法兼容性:某些算法(如K-近邻、K-均值聚类)可能需要归一化,而其他算法(如线性回归、神经网络)可能需要标准化。















 1495
1495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









