







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
🍺 要求:
- 学习如何编写一个完整的深度学习程序
- 手动推导卷积层与池化层的计算过程
🔔本次的重点在于学会构建CNN网络
一、创建环境
🏡我的环境:
● 语言环境:Python3.8
● 编译器:pycharm专业版
● 深度学习环境:Pytorch(配置方法参考0基础深度学习项目1)
本节中涉及的函数在以上链接中均有详解,建议和上一篇结合学习!!!
二、前期准备
2.1 设置GPU
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.2 导入数据
# 导入数据,划分测试集和训练集
train_ds = torchvision.datasets.CIFAR10('data',
train=True,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
test_ds = torchvision.datasets.CIFAR10('data',
train=False,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
# 设置batch_size,加载数据
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size)
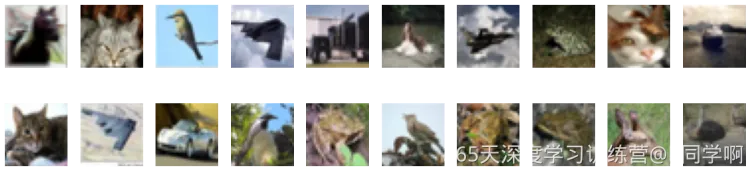
2.3 数据可视化
import numpy as np
# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):
# 维度缩减
npimg = imgs.numpy().transpose((1, 2, 0))
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')
plt.show()
结果如下:
三、构建简单的CNN网络(卷积神经网络)
3.1 构建网络
对于一般的CNN网络来说,都是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
import torch.nn.functional as F
num_classes = 10 # 图片的类别数
class Model(nn.Module):
def __init__(self):
super().__init__()
# 特征提取网络
self.conv1 = nn.Conv2d(3, 64, kernel_size=3) # 第一层卷积,卷积核大小为3*3
self.pool1 = nn.MaxPool2d(kernel_size=2) # 设置池化层,池化核大小为2*2
self.conv2 = nn.Conv2d(64, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3) # 第三层卷积,卷积核大小为3*3
self.pool3 = nn.MaxPool2d(kernel_size=2)
# 分类网络
self.fc1 = nn.Linear(512, 256)
self.fc2 = nn.Linear(256, num_classes)
# 前向传播
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = torch.flatten(x, start_dim=1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载并打印模型
from torchinfo import summary
# 将模型转移到GPU中(我们模型运行均在GPU中进行)
model = Model().to(device)
summary(model)
⭐1. torch.nn.Conv2d()详解
- torch.nn.Conv2d()是一层卷积层,它接受一个通道(例如灰度图像)的输入,并输出64个通道。卷积核的大小是3x3,这意味着每个卷积核在输入图像上滑动时,查看的是一个3x3的区域。。
- 函数原型:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
参数说明:
● in_channels ( int ) – 输入图像中的通道数
● out_channels ( int ) – 卷积产生的通道数
● kernel_size ( int or tuple ) – 卷积核的大小
● stride ( int or tuple , optional ) – 卷积的步幅。默认值:1
● padding ( int , tuple或str , optional ) – 添加到输入的所有四个边的填充。默认值:0
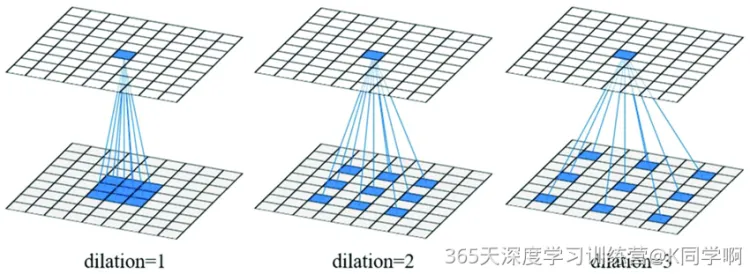
● dilation (int or tuple, optional) - 扩张操作:控制kernel点(卷积核点)的间距,默认值:1。
● groups(int,可选):将输入通道分组成多个子组,每个子组使用一组卷积核来处理。默认值为 1,表示不进行分组卷积。
● padding_mode (字符串,可选) – ‘zeros’, ‘reflect’, ‘replicate’或’circular’. 默认:‘zeros’
关于dilation参数图解:
⭐2. torch.nn.Linear()详解
- torch.nn.Linear()是一个全连接层,它接受512个输入(之前卷积和池化操作后的特征数量),并输出256个节点。。
- 函数原型:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数说明:
● in_features:每个输入样本的大小
● out_features:每个输出样本的大小
⭐3. torch.nn.MaxPool2d()详解
- torch.nn.MaxPool2d()是一个最大池化层,它的池化核大小是2x2。池化操作会减少数据的维度,同时保留最重要的特征。
- 函数原型:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数说明:
● kernel_size:最大的窗口大小
● stride:窗口的步幅,默认值为kernel_size
● padding:填充值,默认为0
● dilation:控制窗口中元素步幅的参数
结果如图:

3.2 关于卷积层、池化层的手动计算知识补充
3.2.1 卷积层
3.2.1.1 卷积输出shape计算(参照3.1 torch.nn.Conv2d()详解)
4*4 的输入矩阵
I
I
I 和 3*3 的卷积核
K
K
K:
● 在步长(stride)为 1 时,输出的大小为 ( 4 − 3 + 1 ) × ( 4 − 3 + 1 )
计算公式:
● 输入图片矩阵
I
I
I 大小:
w
×
w
w × w
w×w
● 卷积核
K
K
K:
k
×
k
k × k
k×k
● 步长
S
S
S:
s
s
s
● 填充大小(padding):
p
p
p
o = ⌊ ( w − k + 2 p ) s + 1 ⌋ o = ⌊\frac{(w − k + 2p )}{s}+1⌋ o=⌊s(w−k+2p)+1⌋
输出图片大小为: o × o o × o o×o
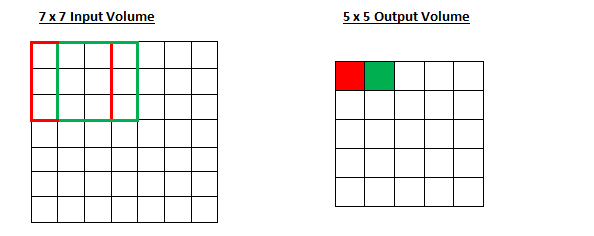
🔍实例:
7
∗
7
7*7
7∗7 的 input,
3
∗
3
3*3
3∗3 的 kernel,无填充(padding=0),步长为1,则
o
=
(
7
−
3
)
1
+
1
o = \frac{(7 − 3 )}{1}+1
o=1(7−3)+1也即 output size 为
5
∗
5
5*5
5∗5
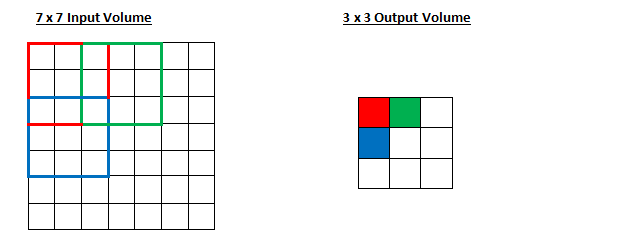
7
∗
7
7*7
7∗7 的 input,
3
∗
3
3*3
3∗3 的 kernel,无填充(padding=0),步长为2,则
o
=
(
7
−
3
)
2
+
1
o = \frac{(7 − 3 )}{2}+1
o=2(7−3)+1也即 output size 为
3
∗
3
3*3
3∗3
3.2.1.2 卷积层运算量的计算
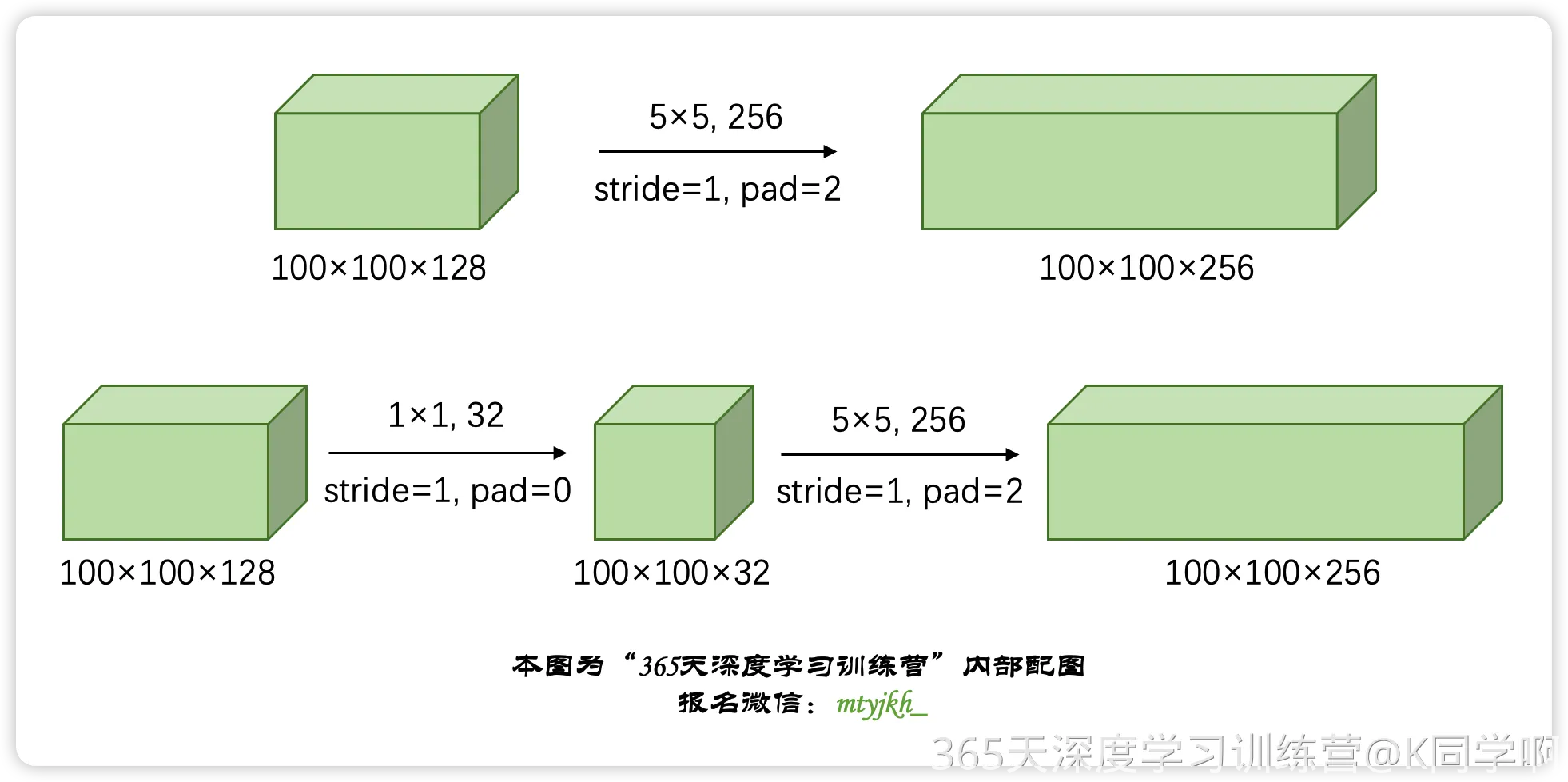
⭐对于第一个卷积过程涉及的计算量计算过程如下:
首先,我们需要计算卷积层的参数量。对于一个卷积核大小为 k × k k \times k k×k,输入特征图大小为 h × w × c i n h \times w \times c_{in} h×w×cin,输出特征图大小为 h ′ × w ′ × c o u t h' \times w' \times c_{out} h′×w′×cout的卷积层,其参数量为:
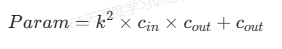
其中最后的
c
o
u
t
c_{out}
cout是bias的数量。
对于本题,输入特征图大小为
100
×
100
×
128
100 \times 100 \times 128
100×100×128,输出特征图大小为
100
×
100
×
256
100 \times 100 \times 256
100×100×256,卷积核大小为
5
×
5
5 \times 5
5×5,且填充为 2,步长为 1,输出通道数为 256。因此,每个卷积层的参数量为:
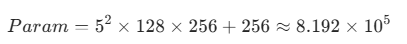
参数量会计算了,那么
F
L
O
P
s
FLOPs
FLOPs其实也是很简单的,就一个公式:
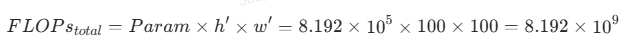
因此,经过具有 256 个输出的 5x5 卷积层之后,输出数据为 100x100x256 的计算量是约为
8.192
×
1
0
9
F
L
O
P
s
8.192 \times 10^{9} FLOPs
8.192×109FLOPs。
⭐对于第二个卷积过程涉及的计算量计算过程如下:
首先考虑 1x1 卷积层的计算量。套用上面的公式,输入特征图大小为 100 × 100 × 128 100 \times 100 \times 128 100×100×128,输出通道数为 32,因此经过 1x1 卷积层后,输出特征图大小为 100 × 100 × 32 100 \times 100 \times 32 100×100×32,这里的bias值很小直接省了,计算量为:
F L O P s 1 × 1 = 1 2 × 128 × 32 × 100 × 100 = 4.096 × 1 0 7 FLOPs_{1\times1} = 1^2 \times 128 \times 32 \times 100 \times 100 = 4.096 \times 10^7 FLOPs1×1=12×128×32×100×100=4.096×107
接下来考虑 5x5 卷积层的计算量,经过 1x1 卷积层后,输出特征图大小为 100 × 100 × 32 100 \times 100 \times 32 100×100×32,输入通道数为 32,输出通道数为 256,卷积核大小为 5x5,填充为 2,步长为 1,这里的bias值很小我直接省了,计算量为:
F L O P s 5 × 5 = 5 2 × 32 × 256 × 100 × 100 = 2.048 × 1 0 9 FLOPs_{5\times5} = 5^2 \times 32 \times 256 \times 100 \times 100= 2.048 \times 10^{9} FLOPs5×5=52×32×256×100×100=2.048×109
因此,经过具有 32 个 1x1大小的卷积核的卷积层和具有 256 个5x5大小的卷积核的卷积层之后,输出数据为 100x100x256 的计算量为
F L O P s 1 × 1 + F L O P s 5 × 5 ≈ 2.048 × 1 0 9 FLOPs_{1\times1} + FLOPs_{5\times5} ≈ 2.048 \times 10^{9} FLOPs1×1+FLOPs5×5≈2.048×109
3.2.2 池化层
3.2.2.1 池化层理论详解
在图像处理中,由于图像中存在较多冗余信息,可用某一区域子块的统计信息(如最大值或均值等)来刻画该区域中所有像素点呈现的空间分布模式,以替代区域子块中所有像素点取值,这就是卷积神经网络中池化(pooling)操作。
池化层可对提取到的特征信息进行降维,实现下采样,同时保留了特征图中主要信息,一方面使特征图变小,简化网络计算复杂度;另一方面进行特征压缩,提取主要特征,增加平移不变性,减少过拟合风险。但其实池化更多程度上是一种计算性能的一个妥协,强硬地压缩特征的同时也损失了一部分信息。
池化的几种常见方法包括:平均池化 与 最大池化。
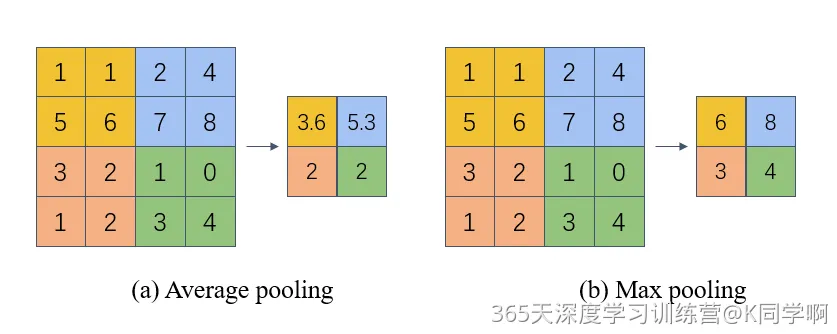
● 平均池化: 计算区域子块所包含所有像素点的均值,将均值作为平均池化结果。如 图1(a),这里使用大小为
2
×
2
2\times2
2×2的池化窗口,每次移动的步长为2,对池化窗口覆盖区域内的像素取平均值,得到相应的输出特征图的像素值。池化窗口的大小也称为池化大小,用
k
h
×
k
w
k_h \times k_w
kh×kw表示。在卷积神经网络中用的比较多的是窗口大小为
2
×
2
2 \times 2
2×2,步长为2的池化。
● 最大池化: 从输入特征图的某个区域子块中选择值最大的像素点作为最大池化结果。如 图1(b),对池化窗口覆盖区域内的像素取最大值,得到输出特征图的像素值。当池化窗口在图片上滑动时,会得到整张输出特征图。
池化的特点:
- 当输入数据做出少量平移时,经过池化后的大多数输出还能保持不变,因此,池化对微小的位置变化具有鲁棒性。例如 ,输入矩阵向右平移一个像素值,使用最大池化后,结果与平移前依旧能保持不变。
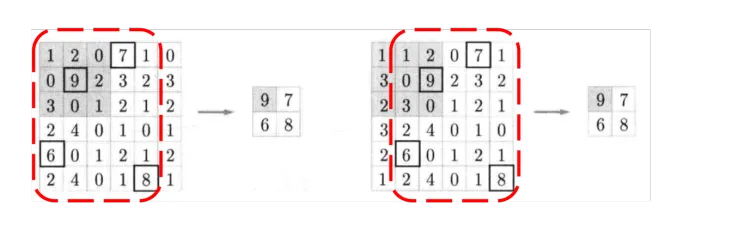
- 由于池化之后特征图会变小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
3.2.2.2 池化层的计算
📐池化层计算公式:

🔍案例1
import torch
import torch.nn as nn
m = nn.MaxPool2d(2)
input_x = torch.randn(3, 32, 32)
print("输入数据input_x.shape:",input_x.shape)
output = m(input_x)
print("输出数据output.shape:",output.shape)
输入数据input_x.shape: torch.Size([3, 32, 32])
输出数据output.shape: torch.Size([3, 16, 16])
📏推导分析(参照3.1 torch.nn.MaxPool2d()详解):

🔍案例2
m = nn.MaxPool2d(3)
input_x = torch.randn(3, 32, 32)
print("输入数据input_x.shape:",input_x.shape)
output = m(input_x)
print("输出数据output.shape:",output.shape)
输入数据input_x.shape: torch.Size([3, 32, 32])
输出数据output.shape: torch.Size([3, 10, 10])
📏推导分析:
输入的数据格式是:[3,32,32],即[C*Hin*Win]
带入公式:其中Hin=32,padding=0,dilation=1,kernel_size=3,stride=3,代入上面的公式可得Hout=10
同理,Wout=10,C保持不变,故而output.shape为 [3, 10, 10]。
四、训练模型
4.1 设置超参数
# 设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-2 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
4.2 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 循环遍历dataloader中的每个批量,每个批量包含一批图片X和对应的标签y。
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 通过模型对当前批量的图片进行预测
loss = loss_fn(pred, y) # 计算预测结果pred和真实标签y之间的损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播,计算损失关于模型参数的梯度
optimizer.step() # 每一步自动更新,根据计算出的梯度更新模型的参数
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item() #更新训练准确率。pred.argmax(1)返回每个预测向量的最大值索引,即最可能的类别。然后比较预测的类别和真实的类别y,计算正确预测的图片数量。
train_loss += loss.item() #累加当前批量的损失
train_acc /= size # 计算平均训练准确率,通过将累加的正确预测数量除以训练集的总大小.
train_loss /= num_batches #计算平均训练损失,通过将累加的损失除以批次数目。
return train_acc, train_loss #函数返回平均训练准确率和平均训练损失
4.3 编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4.4 开始训练
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
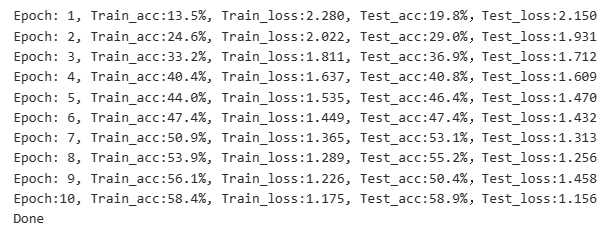
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
结果如图:
4.5 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
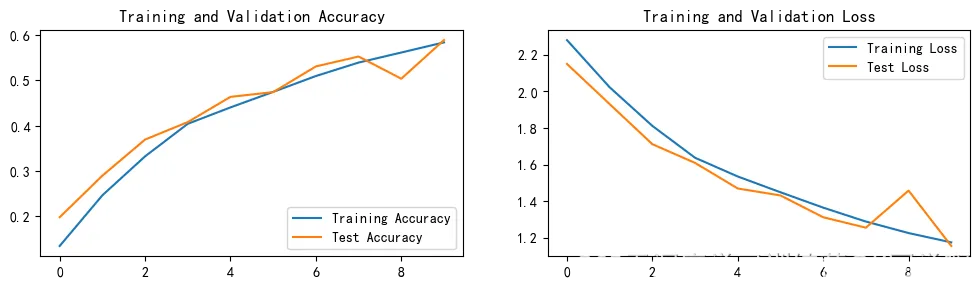
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
结果如图:
五、总结
本节中学会了卷积层和池化层的手动计算,搞清楚了数据是如何在卷积层和池化层从输入到输出的。















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









