







近几年来,神经网络飞跃发展,其中一个方向是CNN,时计算机处理的一个飞跃提升,学习CNN 过程复杂且艰巨。下面就开始介绍~
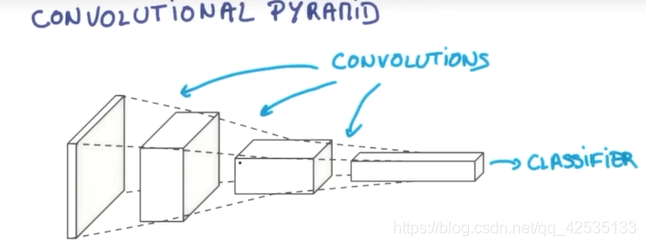
从左至右图片描述:
256x256xRGB → 128x128x16 → 64x64x64 → 32x32x256
加粗的数字,即RGB(彩色,三原色),16, 64, 256 为经过逐层神经网络处理过后的图片厚度(Depth)
256x256,128x128,64x64,32x32为经过逐层神经网络处理过后的图片的长、宽(Space)
整个过程的处理为,将输入的图片的长宽不断进行压缩,厚度加厚,最后就变成了一个classifier,运用最后的信息进行分类。
具体各个层如何工作,打算回头再写一篇博客进行介绍,下面介绍CNN的代码实现。
CNN代码实现
1 定义网络参数,权重Weight,偏值biases,卷积层以及池化层
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) #tf.truncated_normal产生随机变量,标准差0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)#bias一般取正值,设为0.1
return tf.Variable(initial)
def conv2d(x, W): #定义卷积神经网络层
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
#x为图片的所有信息,W为传入的Weight,strides为步长(每隔多少个像素提取一次信息)
def max_pool_2x2(x): #用pooling解决跨度大带来的信息损失问题
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
2 reshape输入图片
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# print(x_image.shape) # [n_samples, 28,28,1]
3 定义各个层
## conv1 layer ##
W_conv1 = weight_variable([5,5, 1,32]) # patch 5x5, in size 1(输入图片的高度为1) , out size 32 图片高度32,一个单位,32个高度
b_conv1 = bias_variable([32]) #32个长度
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # tf.nn.relu非线性处理,使其非线性化 output size 28x28x32
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32
## conv2 layer ##
W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
## fc1 layer ##
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #将pooling2的结果变平
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## fc2 layer ##
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #计算概率
4 定义损失与训练step
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #选择较小的损失率
注:以上代码源自网络,只是对其分析解读。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









