






摘要:本文提出了一种新颖的在检测框层面做语义分割的监督学习框架,能够实现准确且实时地多光谱(可见光和红外光)行人检测。具体来说就是将已经获得的行人检测框的普通图像和红外图像(已对齐)作为输入,然后估计出准确的预测热力图来表征行人的存在。
比之前的用anchor来做的多光谱检测方法,本文方法有两个有点:
1) 抛弃anchor的方法,避免了复杂的anchor超参数设置,而且提高了准确率,对小目标和遮挡目标效果很好。
2) 可以利用地分辨率的输入图片就能生成准确的检测结果,计算量小,速度很快。
1 引言
目前所做的行人检测多是仅仅基于可见光进行检测的,导致只有白天检测效果好,晚上就不行了,环境亮度的改变对检测结果影响很大。于是,多光谱检测应运而生,本文所用的多光谱数据集KAIST包含可见光和红外线,能够提供互补信息,从而在各种光照条件下提高了模型的鲁棒性。
现存的多光谱目标检测多是基于anchor所做的,比如rpn网络或者faster r-cnn。
本文针对anchor方法对小目标检测不好,增大输入图片又导致计算量变大,而且anchor正样本和负样本数目不平衡这几个问题??(这些问题不是都解决的差不多了么??)
本文主要贡献:
1、 提出的检测框分割监督框架不用Anchor box训练
2、 证明这种不用anchor box来做分割的方法比用Anchor box的方法,在训练两步网络时能提供更好的监督信息。
3、 快:30fps。准(存疑)
相关工作
第一个公开的多光谱数据集KAIST.
2016年第一次有人用深度神经网络做多光谱行人检测。
3 我们的方法
输入时两张对齐的图片(多光谱摄像机拍摄),然后两个前驱网络(vgg1-5)分别独立地对这两张图片提取特征,然后将分别提取的单通道的fm合成一个fm(连接操作),利用这个合成的fm进行一个1*1的卷积,生成一个两通道的fm,一个代表前景的预测值,一个代表背景的预测值,在这个fm上执行softmax哪个输出值大于0.5就作为最终的预测结果(前景或背景),来生成预测热力图。
3.1网络结构
如下图左边为所提出的特征融合网络MFFN(multispectral feature fusion network)的工作流程图,右边MFFN和HMFFN(hierarchical multispectral fea- ture fusion network)的网络架构图。
3.2 训练过程
用已经有的标签框生成掩膜,对应到相应的卷积层的输出需要对掩膜缩放。本文的掩膜对应到的两个前驱网络生成的两个单通道的fm连接之后所形成的的fm上。

具体这个框型掩膜怎么生成的呢?很简单,框内的像素点掩膜值为1,代表前景,框外的像素点掩膜值为0,代表背景。
损失函数(下图左):
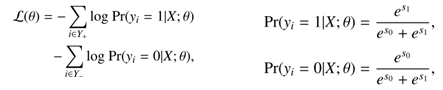
Y+、Y-代表每个像素点标签为前景或背景,Pr(yi|X; θ) ∈ [0, 1]代表预测每个像素点上的预测值是1(前景)或0(背景)的得分,用softmax计算。theta代表要进行优化更新的权重。
S1、S0代表连接的两通道的fm(经过1*1的卷积之后生成的那个两通道的fm)计算所得的输出值。用sgd优化权重参数。
4实验
4.1数据集与评估方法
数据集:KAIST
也有其他的多光谱数据集,如CVC-14,但不像KAIST那样对得很准。
如何评估预测的准确性呢?
将标签框转换为掩膜,与预测的掩膜做比较。具体来说
TP代表正确地预测为正例的像素点数目,TN代表正确地预测为负例的像素点数目,FP代表错位的预测为正例的像素点数目,FN错位的预测为负例的像素点数目。
准确率计算为:TP/(TP+FP),即热力图上按照0.5的阈值区分正例点负例点之后,预测正确的正例点占所有预测的正例点的数目。
召回率的计算:TP/(TP+FN),即正确预测出的正例点占所有gt正例点的数目。
本文做的是全尺寸的预测热力图,也就是说不区分不同的实例,如果两个人离得很近,在热力图上显示的结果这两个人所处的区域都是高亮的,但是你无法区分这个高亮区域是有两个人还是一个人,只能得出这里有人的结论。
为什么不是将预测结果(热力图)转换为标签框的形式进行评估检测准确性呢?
因为这样根本无法进行。无法区分不同的实例就无法计算出不同的标签框,也就无法按照voc或者coco中目标检测的评估标准进行评估。
基于anchor的预测是要预测要求要知道是否为不同的实例。从这一点也可以侧面看出这种基于检测框层面的分割预测是简化了问题,就采取了一种更为简单的手段去解决问题。能去anchor也是因为不需要预测不同的实例。
所以这种不区分实例的预测有多大意义呢?
作者认为
4.2 实现细节
两个前驱卷积网络用imageNet预训练权重初始化,其他卷积层用Xavier初始化,Caffe框架,SGD优化器,学习率:前两个epoch:0.001,第三个epoch0.0001.
4.3对比本文提出两个模型
只做了纵向对比评估,即本文所提出的两个模型的评估,没做横向评估,因为与其他模型用的评价标准不一致,没办法比较。
实验证明在输入图片尺寸比较小(320250)时HMFFN相对于MFFN模型检测结果的提升更为明显,因为HMFFN用到了残差连接,将低层特征加到了高层上,低层特征对小目标更敏感,所以对小目标检测会有提升。
但在大尺寸(640512)的输入时,提升就不明显了。


4.4 与基于anchor box做检测框回归的模型作对比
HMFFN 和 RPN-HMFFN,作者对RPN-HMFFN细节没做介绍。推测就是在1*1的卷积层输出的层上用anchor作为先验框,输入到分类、回归头中预测检测框和得分,作为最终的得分和回归框。就是将原来的预测热力图改为对anchor预测得分和回归框。

与其他模型做对比(将其他检测框的结果转换为热力图的评估标准):
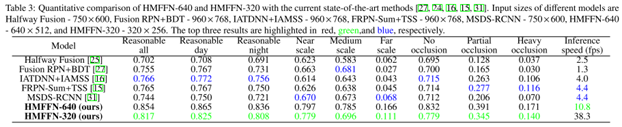
与基于anchor的检测结果对比:

与其他模型对比图:
















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









