







1、 为什么要做这个研究(理论走向和目前缺陷) ?
基于anchor的检测器,对anchor的设计要求很麻烦,训练过程还有很多跟Anchor相关的计算比如正负例anchor判断时的iou计算。故考虑去除anchor,目前anchor free的方法典型如yolov1,由于其只考虑目标中心位置进行框回归,召回率很低,还有就是CornerNet,基于关键点检测的方法,但是在配对关键点时很麻烦。
2、 他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
提出FCOS类似于语义分割的思想,结构同RetinaNet类似,但是不用Anchor,对GT框内每个像素点进行框和类别的回归,最后NMS一下。其中每个像素点预测类别得分,和距离框四个边界的的距离。采用FPN多层预测以提高召回率和解决目标重叠时的像素点所属预测层的分配问题,实在解决不了就将像素点的gt框设置为较小的那个gt框。为了消除目标边界上的像素点会产生大量低质量的预测框的问题,提出加一个center-ness分支,用于判断像素点属于目标中心位置的得分,也是用来re-weight类别得分的,这样便可抑制大量低质量的边界框。
3、 发现了什么(总结结果,补充和理论的关系)?
避免了anchor相关的设计和计算,比较简单。
摘要:FCOS是全卷积的一阶段的目标检测器,原理有点像语义分割,需要对每个像素点进行预测。FCOS是anchor-freed,就避免了跟anchor box的复杂计算,比如训练阶段anchor box与gt box计算iou以挑选正负样本,以及anchor超参数的设置。只有一个NMS后处理操作保留,就在coco上实现了44.7的AP。
1、 引言
Anchor超参数设置麻烦且对检测性能影响很大。即使超参设置对了,预定义的超参也会阻碍模型的通用性,在不同的任务上还要重新设计。
全卷积神经网络对于处理语义分割,深度估计,关键点检测和计数等问题很不错,但是他的问题就是对于高度重叠的目标效果不好,故一般全卷积网络(FCN)适用于特定场景,如人脸检测,文本检测,因为他们重叠不多。本文提出,利用FPN可以很好的解决FCN所遇到的重叠问题。FCOS还引入一个只有一层的center-ness分支来预测一个像素点到此像素点所属目标中心点的偏差,这个偏差用于抑制那些低质量的预测的边界框。
FCN有如下优点:
1) 将检测用全卷积网络实现,与语义分割统一起来。
2) 无anchor,无proposal,设计简单,无跟anchor相关的复杂计算。
3) FCOS可以作为两步网络中的RPN网络来用。
2、 相关研究
基于anchor的检测器:Faster R-CNN, SSD, YOLOv2等,一些列缺点。
Anchor-free的检测器:YOLOv1只用目标中心附件的点来预测bbox,导致召回率低。CornerNet配对两个关键点很麻烦,计算量很大。
3、 我们的方法
3.1 全卷积单步目标检测器
以前基于anchor的检测器都是用靠近gt box的多个Anchor作为参考来进行回归, 而fcos直接以对每个像素点而不是anchor box进行回归,更直接。
每个像素点如果落在gt box中,那么这个像素点被视为正例点,需要对这个点预测一个类别标签,和四个与位置相关的标签{c, l*, t*, r*, b*},其中如果像素点未落在任何框内,c=0, 若落在某个类别为ci的gt框内,则c=ci, l为这个点距离gt框左边界的距离,t为距离顶边界的距离,r为距离右边界的距离,b为距离下边界的距离,计算如下式。如果一个像素点落在gt框内,即gt框有重合,则选择面积较小的那个gt框作为这个点的所属框。

网络输出:与训练目标相对应,最后一层网络预测一个80维的向量p用于分类,和一个4维的向量t=(l,t,r,b)用于定位。FCOS并不是训练一个多分类分类器,而是训练一个多个二分类器。和focalloss那篇论文类似,FCOS在主干网络头部输出的fm之后又添加4个卷积层。由于回归目标都是正的,对回归出来的值应用取指数exp(x)放缩到(0,正无穷)。FCOS比那种每个位置应用了9个anchor的网络,输出变量变为其1/9.
损失函数:
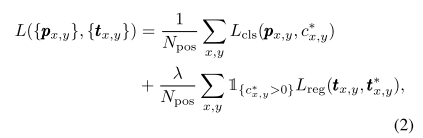
分类用的focal loss(交叉熵损失的升级),回归用的IOU损失,Npos代表正例数目,lamda=1是回归损失的平衡因子。回归损失中的1∈{0,1}是个标志符,代表像素点是背景框还是属于某个gt框的点。
推断:取Px,y大于0.05的像素点作为正例。
3.2多层输出预测(FPN)
FPN的多层输出预测可以很好解决FCOS面临的两个问题(1)召回率低(2)目标重叠问题。
1) 到最后一个fm输出层时由于相对原始图片缩小比例比较大(16倍),会导致比较低的最好的可能的召回(BPR, best possible recall),因为有的相对较小的目标在这层fm上已经没有位置了,基于anchor的检测器可以通过降低iou阈值来提高召回。实际上这种担心多余,从结果看BPR并不比一般的anchor-based的模型低,加上FPN之后比肩RetinaNet。
2) 重叠问题,目标重叠回导致不能确定当前像素点属于哪个gt框。FCOS中,输出层包括{P3, P4, P5,P6,P7},他们的strides(相对于原始图片的缩放比例)分别是8,16,32,64,128。
不像FPN所做的在各层根据GT框的大小在不同层为不同的框设置回归目标。FCOS先在每一层都为每个像素点计算回归目标(l*, t*, r*, b*)。如果max(l*, t*, r*, b*)>mi,说明回归目标很大,这个目标很大,那这个像素应该放到更高一层进行回归,如果max(l*, t*, r*, b*)<mi-1,说明回归目标较小,这个点应该放到较低的层进行回归。这里,{ m2, m3, m4, m5, m6 ,m7} = { 0, 64, 128, 256, 512, 正无穷}。这样,由于重叠目标多数是大小不同的,于是不同目标就被分配到不同层进行回归。但是还是会存在例外,就是一个像素点同时属于两个gt框内,并且这两个gt框大小相近,即在同一个层回归,那么我们就把这个点的gt框设置为那个相对面积较小的gt框。
另外对不同的层,回归目标的大小范围是不一样的,都用一个的指数函数exp(x)不太合理,故对不同的层设置一个可学习的参数si,应用exp(si*x)来缩放。会有轻微提升。
3.3、FCOS的Center-ness
即使使用了多层预测,FCOS效果依然不怎么样,这是由于产生大量的低质量的预测框,这些低质量的框往往是由于远离目标中心的限速点产生的。
故提出增加一个分支来抑制这些低质量框,这个分支预测每个像素点属于目标中心点的可能性,gt值通过下式计算:
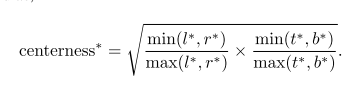
用交叉熵(binary cross entropy loss)计算这个分支的损失。
推断时,通过center-ness分支为每个像素点计算的分类得分再re-weight一下,这样就能抑制大量低质量的预测框。
还有一种抑制低质量边界框的办法就是只利用中心部分的点来做框的预测,实验证明这两种策略联合到一块效果最好。
4、 实验
Coco,默认参数同retinanet。
4.1 消融研究
4.1.1多层预测(FPN)
主要解决低召回率和目标重叠时的Gt选择问题。


与Anchor-based 的RetinaNet对比

4.1.2 带或不带Center-ness

4.2与其他检测器对比

5 FCOS替换RPN网络

6 结论
FOCS不用anchor,避免了与anchor相关的超参数设置,和计算。















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









