










1、为什么要做这个研究(理论走向和目前缺陷) ?
2D图像上的检测可以看得更远,而且检测更准,但是缺乏距离测量。3D点云有精确的距离测量,但是远距离的物体扫到的点就很少了,经常出现漏检,故考虑融合3D检测距离很准而2D检测看得更远的优势,提高3D目标跟踪对遮挡、远距离目标跟踪的效果。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
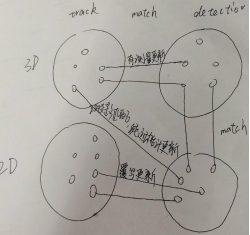
1)3D检测和2D检测关联:点云和图像都有各自的检测器,3D检测器获得的3D框先投影到2D图像上,基于2D IoU找到对应2D检测器输出的2D框(即同一目标的3D框和2D框)。
2)检测和跟踪匹配,状态参数更新:跟踪3D状态和2D状态参数是分别维护的,首先跟踪3D状态和3D检测进行匹配,匹配上的进行卡尔曼滤波更新。未匹配上的跟踪其3D状态的2D投影以及所有跟踪的2D状态(如果有)同无3D检测框关联的2D检测框匹配,匹配上的跟踪用纯运动估计(卡尔曼滤波)更新其运动信息,匹配上的跟踪2D状态更新时无滤波器,直接用匹配到的2D检测框更新位置,因为此时往往目标都处于比较远的位置,前后帧的2D框位置变化不大。
3、发现了什么(总结结果,补充和理论的关系)?
效果很好,KITTI上第七名(HOTA),NuScenes上第五名。 速度很快,kitti上90FPS,NuScenes上4FPS。利用现有的2D检测器和3D检测器就行,无需额外训练模型。利用了2D检测信息提高了召回率了,相当于跟踪更稳定(无3D检测匹配时)或加强(同时有3D检测和2D检测和跟踪匹配),改善了3D检测失败(距离较远或者遮挡)时的跟踪性能,但是同时也导致IDS比较高。
摘要:现存的很多方法只依赖于雷达点云做跟踪,但由于远距离的物体只能打到非常少的点,就很难检测到,也就跟踪不到了。但是图像对于即使是远距离的点也有丰富的文理和细节信息,比较容易检测到,但是对于对于距离的测量并不准。本文提出的EagerMOT跟踪方法能够同时利用点云距离测量比较准和图像检测比较准的特性,实现远距离的跟踪。KITTI上top1,nuScens上TOP5
1、引言
仅仅用点云信息的话只能在比较近的距离才能实现稳定跟踪,但是,基于图像的方法可以利用丰富的视觉信息实现对遮挡物体的较好检测,甚至远距离的物体检测效果也很好。EagerMOT可以融合2D和3D检测器的检测结果,采用一个两阶段的关联策略进行目标的关联。而且可以用于不同的传感器配置,比如kitti的激光雷达+前视摄像头,或者NuScenes上的激光雷达+多个视锥不重叠的摄像头。
EagerNet需要给定两个训练好的目标检测器(2D+3D),不再需要额外的训练。
2、相关研究
2D MOT:TrackR-CNN,Tracktor,CenterTrack
3D MOT:AB3DMOT,ProbabilisticTracking,CenterPoint
基于2D+3D融合的方法:BeyondPixels,MOTSFusion(光流+场景流+2D检测),GNN3DMOT(表观特征+运动特征)
3、本文方法
总体框架:

算法步骤:
1)获取一系列来自2D检测器的检测框和3D检测器的检测框,将来自同一个目标的2D检测框和3D检测框进行匹配。2)两阶段的数据关联模块实现跟踪框和检测框的关联之后,进行跟踪状态更新。3)利用给一个简单的生命周期管理方法管理跟踪。
A.2D框和3D框的关联
先把3D框投影到2D图像上,然后计算投影后的2D框和原始2D检测器输出的2D框计算IOU,利用贪心匹配,产生一系列同时有2D检测结果和3D检测结果的实例以及单独2D检测结果和单独3D检测结果,这些实例共同组成一个集合It。
多相机设置:如果有多个相机的话,会把3D检测结果投影到能被相机拍到的相机(可能有多个都能看到),找到IOU最大的那个相机上的2D检测框进行匹配,不会把一个3D框匹配到多个2D框上。
B.匹配
每一帧t,融合3D检测结果和2D检测结果的实例集合(包含3类实例,2D检测+3D检测,仅2D检测,仅3D检测)
跟踪参数化:同时维护2D跟踪状态和3D跟踪状态,但是是分开维护的。3D状态参数:3D框+速度向量,2D状态参数:2D检测框。因为最终目的是做3D跟踪,所以一个跟踪的置信度等于其3D状态的置信度。
3D状态参数位置和速度更新是基于卡尔曼滤波做的 。
第一阶段关联:当前帧检测到的3D框将和3D跟踪的状态参数进行贪心匹配。匹配的度量是欧式距离*归一化的朝向余弦距离:
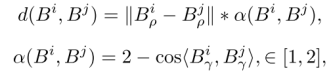
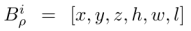
Br是3D框的朝向。实验发现这个度量比马氏距离或者3D IoU更好,尤其在低帧率的雷达(NuScenes上每10帧标1帧,每秒标2帧)。
经过第一阶段的匹配,还剩下一波没匹配的3D检测1u_It(无论是否和2D检测关联上)和没匹配的3D跟踪1u_Tt,但是这些3D检测并不参与第二阶段的匹配。
第二阶段关联:第二阶段只在2D空间进行匹配。将没有和3D检测关联上的2D检测(3D检测框和2D检测框关联的目的所在),和剩下的没匹配的3D跟踪1u_Tt和所有的2D跟踪2d_Tt,基于2D IoU度量进行匹配(3D跟踪的预测框需要投影到图像上获取2D框)。
有些目标在2D检测结果上有检测框,但是由于距离雷达太远,并不能通过雷达点云获得3D检测框,对于这种情况,2D检测框一般在图像上的位置变化不大,故并不进行2D框位置的预测(类似卡尔曼滤波),直接基于前一帧观测到的2D框进行关联。
状态更新:2D状态参数直接用匹配的2D检测框进行更新,且下一帧的当前目标位置直接用当前框,不做预测。而3D状态,当有3D检测框匹配时,用检测框+卡尔曼滤波器更新当前框位置,且基于匀速运动模型更新下一帧当前目标的3D位置(和AB3DMOT一样),当没有3D检测框匹配,或者3D跟踪仅有2D检测框和其投影匹配时,按无测量的纯运动估计(卡尔曼滤波)预测下一帧当前目标位置。
C.生命周期管理
跟AB3DMOT一样,2D跟踪连续3帧没有2D检测框和其匹配,或者3D跟踪连续3帧没有3D检测框和其3D框匹配且也没有2D检测框和其2D图像上的投影框匹配,则此跟踪认为丢失。
由于3D检测其通常不像2D检测器一样检测地那么准,如果一个3D跟踪之前连续多帧被2D检测框匹配(这个跟踪最初是个3D检测框,但是到后面的帧时并没有3D检测框和其匹配,仅有2D检测框和其2D投影匹配,这个跟踪纯运动更新状态参数好几次,并没被丢弃,因为有2D检测框和其匹配),当前帧时又有3D检测框和其预测框匹配,则认为是跟踪加强了。
实验评估:
两个数据集:KITTI和NuScenes。
评估方式:1)NuScens 3D MOT, 2) KITTI 3D MOT, 3) KITTI 2D MOT, 4) KITTI MOTS。
评估指标:MOTA, AMOTA, AMOTP,MOTSA, MOTSP, HOTA等。
3D检测:NuScenes上用的是CenterPoint的检测结果,KITTI 3D MOT上用的是Point-GNN和Point R-CNN的检测结果,提交到KITTI服务器上的用的是Point-GNN版的。
2D检测:NuScenes上用的是在NuImages上训练的Cascade R-CNN的检测结果,KITTI上用的是RRC提供的检测结果。
A.消融研究
数据关联:表IV中Full代表既有2D检测输入也有3D检测输入。

上表结果反应出3DIoU度量并不适合NuScenes,因为NuScenes雷达线束(32线,而KITTI是64线)太低了。
表V中反映的是使用不同的检测源的影响。
B.Benchmark结果:
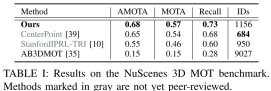
NuScenes:如下表I可以看出Recall非常高,说明融合2D信息可以提高对遮挡目标的跟踪效果,但同时IDs也非常高?
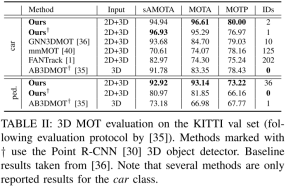
KITTI 3D MOT:kitti验证集,用3D MOT评估方式如下表II。
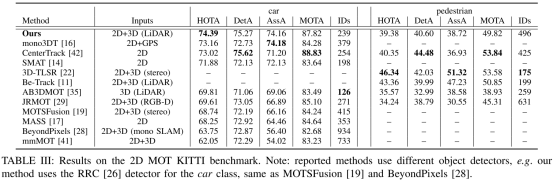
KITTI 2D MOT:kitti测试集上的结果如下表
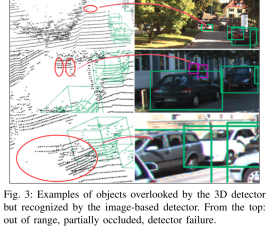
kitti上,3D检测失败但是2D检测补回来的案例:
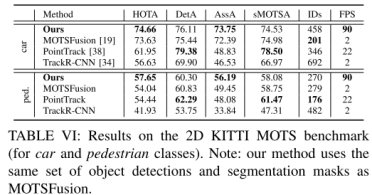
KITTI MOTS(多目标跟踪与分割):
C.运行时间
NuScenes上4FPS,StanforIPRL-TRL和AB3DMOT是10FPS。而在KITTI上,EagerMOT是90FPS,而AB3DMOT是207FPS。在NuScenes上速度这么慢的原因就是NuScenes上有太多的摄像头,需要lidar检测框在做多个摄像头检测框之间关联,而KITTI上只有一个前视摄像头。但是也比很多KITTI上排名靠前的融合2D和3D算法(GNN3DMOT5FPS, mmMOT:4FPS, FANTrack:25FPS)快太多了。















 2971
2971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









