









1、为什么要做这个研究(理论走向和目前缺陷) ?
TBD是现在做目标跟踪的主流方法,这也导致检测结果很影响跟踪的好坏,能否利用由粗到精的思想(faster rcnn)先获得多个粗的轨迹,然后再细化(去除不准的轨迹)得到一个更加准确轨迹?这是本文的主要思考方向。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
1)先生成粗的候选轨迹片段:输入的是多帧(实际4帧)点云序列,每帧点云经过一个共享参数的spconv后再转成一个BEV特征,然后把这连续帧的BEV特征按顺序输入到ConvGRU中获取高阶BEV特征,之后预测3D候选框(正常的3D检测器监督)和相对上一帧的位置偏移(运动信息),在最后一帧的3D框预测结果做NMS,保留下来的3D框及基于其位置偏移反推到之前的帧的3D框组成粗的候选轨迹片段。
2)然后需要对粗的轨迹片段做细化,3D候选框在原始点云中一些3D点坐标连接上其对应的高阶BEV特征输入到pointnet++中获取一个特征向量。将获得连续帧特征向量序列输入到GRU中计算各个候选轨迹片段的置信度,按其得分进行NMS(基于个轨迹片段不同帧的检测的平均IOU),得到精细的轨迹片段。
3)最后对当前帧获得精细的轨迹片段和上一帧输出的轨迹片段进行关联,度量就是重合帧中检测框的平均3D IoU,高于一定阈值时认为关联上,否则,将在下一帧初始化为新轨迹。
3、发现了什么(总结结果,补充和理论的关系)?
算法可以端到端训练,效果很好,在KITTI上获得SOTA效果,但是感觉每一帧都输入多帧计算量会很大。
摘要:提出PC-TCNN算法,首先生成候选轨迹片段,然后对候选轨迹片段进行精细化,再把候选轨迹片段关联到一起生成长轨迹。
1、引言
轨迹片段是由比较短的一段时间内同一目标的多帧检测结果组成的,理论上,多帧中的同一目标(车,人等)它们具有相似的特征(长宽高,体积,几何结构等),这种一致性特征可以被用来有效提升检测质量。本文主要方向就是利用这种一致性特征,通过细化轨迹片段内的检测框的准确度来提升轨迹片段的准确性,进而提升跨帧长轨迹的准确性。
按照这种思路,本文设计了一种用于候选轨迹片段生成的CNN网络(PC-TCNN),1)先生成粗候选轨迹片段,2)再对粗候选轨迹片段进行精细化(基于同一目标的特征一致性),3)最后把细化的轨迹片段关联起来(贪心算法)。此过程如下图所示:

2、相关研究
TBD:检测很影响跟踪,是目前主流方法。
基于轨迹片段来做MOT:先独立地生成轨迹片段,然后把轨迹片段连在一块的方法。这种方法对检测不准的情况比较好。
基于候选区的方法:这是一种先粗后精的思想,比如Faster RCNN两步网络。以及一些利用时序信息做行为检测的方法,这些方法一般是在2D上研究。
3 本文方法
主要框架:

3.1 候选轨迹片段生成
主干网络:每个当前帧(记为0),输入之前的n帧点云(包括当前帧)
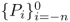
先转换到当前帧坐标系统,然后对每一帧点云体素化,每个体素网格内计算一个网格内的所有点的4维均值特征(3D坐标+强度),然后用稀疏3D卷积获取3D特征,公式如下:
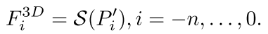
然后把这些帧提取到的3D特征压缩成BEV特征
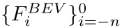
,然后用ConvGRU对这些BEV特征进行处理计算时序特征,公式如下:
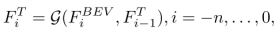
其中F_-n-1初始化为0,最后获得的当前帧时序特征经2D CNN后进一步编码为高阶 BEV特征。
候选轨迹片段生成头:
以多帧的BEV 特征图序列作为输入,在每个特征图的每个像素点会利用目标候选区(3D框)生成头计算目标置信度和偏移,并利用运动头计算每个像素点的跨帧2D偏移(如果有目标就认为是目标的位置偏移)。在最后一帧的目标候选区生成头的输出中做NMS,这样就获得了轨迹片段的m个种子(seed)了, 基于这m个种子和运动头计算的它们的位置偏移进行回推,就可以获得m个轨迹片段。
3.2 轨迹片段细化
轨迹特征聚合:每个候选轨迹片段中的每一帧的目标框在原始点云中会对应一系列3D点,随机挑选一部分,找到每个挑选的点p在此帧点云的对应的高阶BEV位置的特征f(可能非整数,需用到双线性插值),每个点转换到此点对应的3D框的坐标系下,将转换坐标系后的这些3D点坐标连接上其对应的BEV特征后全部输入到PointNet++中生成一个特征向量,然后利用一个GRU层对此轨迹片段的不同帧的特征向量按时序输入到GRU模块中,获取每个轨迹片段的聚合特征序列
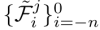
。
此过程表达如下:
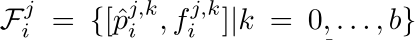
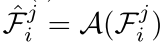
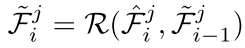
细化头:训练阶段,需要为每条轨迹片段分配GT轨迹,依据就是轨迹片段中的每一帧的3D框与GT轨迹中对应帧中的GT框的平均3D IOU要大于阈值(0.5)。每个轨迹片段的聚合特征序列,经过当前帧的GRU时会输出一个得分,这个得分代表当前轨迹片段的置信度,这个得分的监督选择(交叉熵)跟此轨迹片段与GT轨迹中各帧中的检测框和GT框的3D-IOU的平均值有关,公式表达如下:
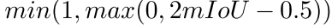
在推断阶段,基于细化后的轨迹输出的上述置信度得分以及轨迹片段最后一帧(当前帧)的检测框进行NMS。
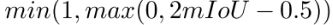
3.3 轨迹片段关联
当前帧预测的轨迹片段和上一帧预测的轨迹片段进行关联,以两个轨迹片段重合帧内的检测框的(平均?)3D IoU作为度量标准,利用贪心算法进行匹配,如果贪心算法得到的匹配对的3D IoU大于一定阈值,则认为这两个轨迹片段正确关联上。如果当前帧的轨迹片段与上一帧的轨迹片段没有关联上的,则将当前帧的这个轨迹片段初始化为新轨迹。
3.4 损失
可以端到端训练,一共两个损失,候选轨迹片段生成损失L_tpn和候选轨迹片段细化损失L_trn,其中,候选轨迹片段生成损失L_tpn有多个目标损失和运动损失组成,公式如下:
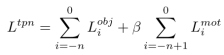
其中L_obj就是单帧的3D检测损失(smooth L1):
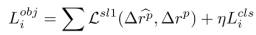
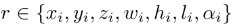
运动损失也是smooth L1损失:
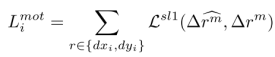
轨迹片段细化损失:


其中的轨迹片段置信度损失L_mIoU是交叉熵损失。
4 实验
4.1 数据集和度量
kitti数据集,度量:MOTA, MOTP,IDS,FRAG
4.2 实现细节(略)
4.3 消融实验
输入帧数的影响:4帧最好
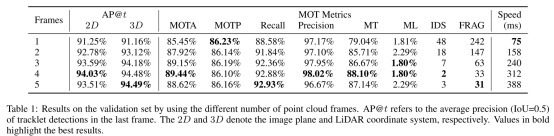
主干网络、候选轨迹片段细化、轨迹片段增强:
不同的主干网络、是否有候选轨迹片段细化、是否在训练阶段做轨迹片段的增强的影响:

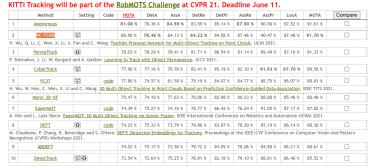
4.4 KITTI测试集上的实验结果
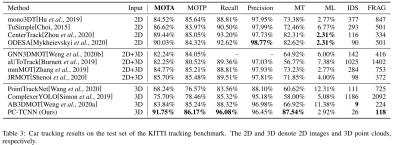
此方法目前在kitti榜单排名如下表:
按照HOTA方法是第二名,按照MOTA依然是第一名。
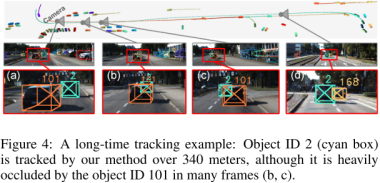
4.5 在3Dmot方法评估
kitti评估3Dmot是需要先把3D框转到2D图像上进行基于IoU的2Dmot评估,AB3DMOT提出新的评估方法直接基于3D IoU在3D空间评估。实验结果:
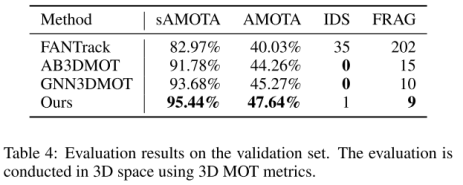















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









