







 本文详细介绍了通过Shell命令与HDFS进行交互的过程,包括启动Hadoop集群,使用各种HDFS命令进行目录和文件操作,如创建目录、上传和下载文件等。
本文详细介绍了通过Shell命令与HDFS进行交互的过程,包括启动Hadoop集群,使用各种HDFS命令进行目录和文件操作,如创建目录、上传和下载文件等。
利用Shell命令与HDFS进行交互
在学习HDFS编程实践前,我们需要启动Hadoop。执行如下命令:
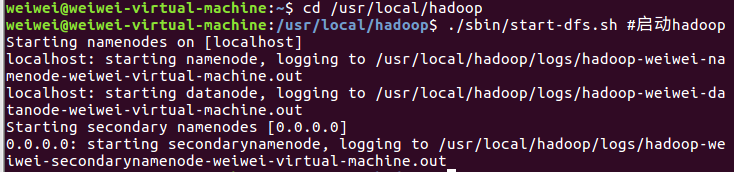
一、启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh #启动hadoop
二、利用Shell命令与HDFS进行交互
终端输入如下命令,查看fs总共支持了哪些命令
./bin/hadoop fs

在终端输入如下命令,可以查看具体某个命令的作用
例如:我们查看put命令如何使用,可以输入如下命令:
./bin/hadoop fs -help put

1.目录操作
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
该命令中表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。

列出HDFS上的所有目录,可以使用如下命令:
./bin/hdfs dfs -ls /

在/user/hadoop/中创建一个二级目录input
./bin/hdfs dfs -mkdir /user/hadoop/input

HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
./bin/hdfs dfs -mkdir /input

使用rm命令删除刚刚创建的根目录下的input目录
(可以使用rm命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(不是“/user/hadoop/input”目录):)
./bin/hdfs dfs –rm –r /input

上面命令中,“-r”参数表示如果删除“/input”目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用“-r”参数,否则会执行失败。
2.文件操作
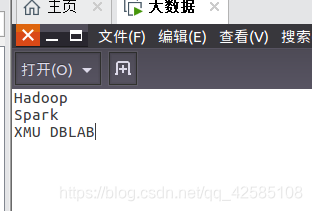
创建一个文件my.txt
touch my.txt


在my.txt文件中输入
Hadoop
Spark
XMU DBLAB
使用如下命令把本地文件系统的“/usr/local/hadoop/my.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:
./bin/hdfs dfs -put ./my.txt /user/hadoop/input

使用ls命令查看一下文件是否成功上传到HDFS中,具体如下:
/bin/hdfs dfs -ls /user/hadoop/input

使用如下命令查看HDFS中的my.txt这个文件的内容:
./bin/hdfs dfs -cat /user/hadoop/input/my.txt

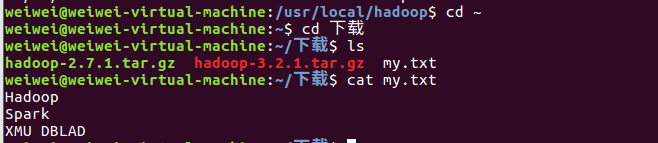
下面把HDFS中的my.txt文件下载到本地文件系统中的“/home/weiwei/下载/”这个目录下
./bin/hdfs dfs -get /user/hadoop/input/my.txt /home/weiwei/下载

使用如下命令,到本地文件系统查看下载下来的文件my.txt:
cd ~
cd 下载
ls
cat my.txt
把HDFS的“/user/hadoop/input/my.txt”文件,拷贝到HDFS的另外一个目录“/input”中(因为之前的根目录下的input目录删除了,现在重新创建input目录)
./bin/hdfs dfs -cp /user/hadoop/input/my.txt /input

查看是否拷贝成功:
./bin/hdfs dfs -ls /input

说明已经拷贝进去。

















 3366
3366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









