







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
CUDA(Compute Unified Device Architecture)是NVIDIA专有的并行计算平台和编程模型。使用CUDA SDK,开发人员可以利用他们的NVIDIA GPU(图形处理单元),从而使他们能够在通常的编程工作流程中引入基于GPU的并行处理能力,而不是通常的基于CPU的顺序处理能力。
随着近年来深度学习的兴起,可以看到模型训练中涉及的各种运算,如矩阵乘法,求逆等,可以在很大程度上并行化,以获得更好的学习性能和更快的训练周期。因此,许多像Pytorch这样的深度学习库使用户能够使用一组接口和实用程序函数来利用GPU。本文将介绍在任何包含支持CUDA的GPU的系统中设置CUDA环境,并简要介绍使用Python的Pytorch库中提供的各种CUDA操作。
查看GPU支持的CUDA版本
在cmd控制台输入navidia-smi查看GPU支持的最高CUDA版本:
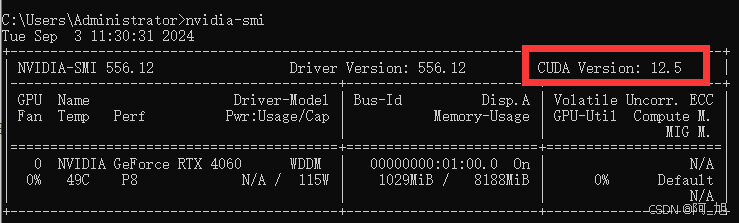
如上图所示,最高支持的CUDA版本为12.5,版本可以向下兼容。因此安装的CUDA版本必须小于或者等于12.5版本。
安装GPU版Pytorch
首先,通过官方Nvidia CUDA兼容性列表检查其系统的GPU,以确保其GPU是否启用CUDA。Pytorch通过提供一个很好的用户友好界面,让您选择操作系统和其他要求,使CUDA安装过程非常简单,如下图所示。根据我们的计算机,我们将根据下图中给出的规格进行安装。
参考Pytorch的官方链接,根据他们的电脑规格选择规格。我们还建议在安装后完全重新启动系统,以确保工具包的正常工作。
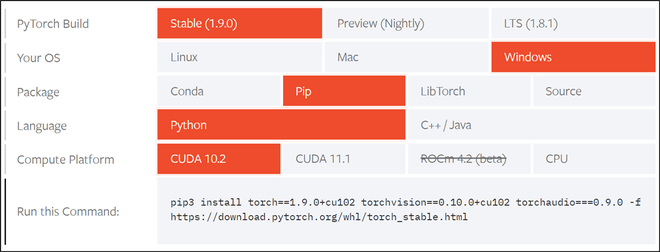
Pytorch安装页面截图
pip3 install torch1.9.0+cu102 torchvision0.10.0+cu102 torchaudio=0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
在Pytorch中开始使用CUDA
安装后,我们可以使用torch.cuda接口使用Pytorch与CUDA交互。我们将使用以下函数:
语法:
- torch.version.cuda() :返回当前安装的软件包的CUDA版本
- torch.cuda.is_available():如果您的系统支持CUDA,则返回True,否则返回False
- torch.cuda.current_device():返回当前设备的ID
- torch.cuda.get_device_name(device_ID):返回ID = 'device_ID’的CUDA设备的名称
代码:
import torch
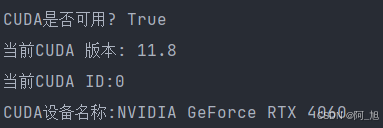
print(f"CUDA是否可用? {torch.cuda.is_available()}")
print(f"当前CUDA 版本: {torch.version.cuda}")
# Storing ID of current CUDA device
cuda_id = torch.cuda.current_device()
print(f"当前CUDA ID:{torch.cuda.current_device()}")
print(f"CUDA设备名称:{torch.cuda.get_device_name(cuda_id)}")
输出:
使用CUDA处理张量
为了通过CUDA交互Pytorch张量,我们可以使用以下实用函数:
语法:
- tensor.device:返回“Tensor”所在的设备名称
- Tensor.to(device_name):返回“device_name”指定的设备上的“Tensor”的新实例:“cpu”表示CPU,“cuda”表示支持CUDA的GPU
- tensor.cpu():将“Tensor”从当前设备传输到CPU
为了演示上述函数,我们将创建一个测试张量并执行以下操作:
检查张量的当前设备并应用张量操作(平方),将张量传输到GPU并应用相同的张量操作(平方),并比较2个设备的结果。
代码:
import torch
# Creating a test tensor
x = torch.randint(1, 100, (100, 100))
# Checking the device name:
# Should return 'cpu' by default
print(x.device)
# Applying tensor operation
res_cpu = x ** 2
# Transferring tensor to GPU
x = x.to(torch.device('cuda'))
# Checking the device name:
# Should return 'cuda:0'
print(x.device)
# Applying same tensor operation
res_gpu = x ** 2
# Checking the equality
# of the two results
assert torch.equal(res_cpu, res_gpu.cpu())
输出:
cpu
cuda : 0
使用CUDA处理深度学习模型
一个好的Pytorch实践是生成与设备无关的代码,因为某些系统可能无法访问GPU,只能依赖CPU,反之亦然。完成后,可以使用以下函数将任何机器学习模型传输到所选设备上
**网址:**Model.to(device_name):
返回:“device_name”指定的设备上的机器学习“Model”的新实例:“cpu”表示CPU,“cuda”表示启用CUDA的GPU
在本例中,我们从torchvision.models实用程序导入预训练的Resnet-18模型,读者可以使用相同的步骤将模型传输到所选设备。
代码:
import torch
import torchvision.models as models
# Making the code device-agnostic
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Instantiating a pre-trained model
model = models.resnet18(pretrained=True)
# Transferring the model to a CUDA enabled GPU
model = model.to(device)

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











